Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Unsupervised and Supervised Learning on Superconducting Processors
Paper and Code
Sep 10, 2019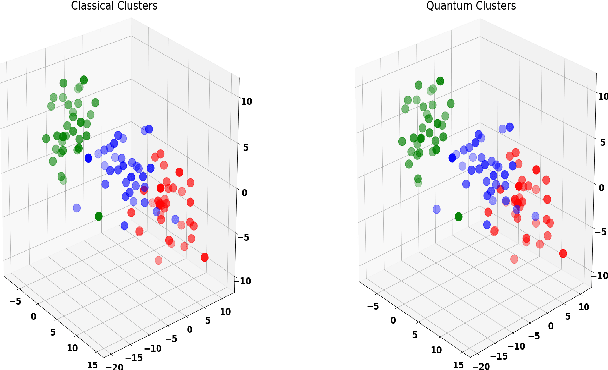
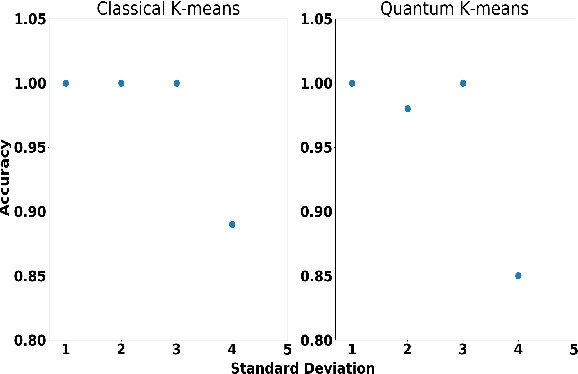
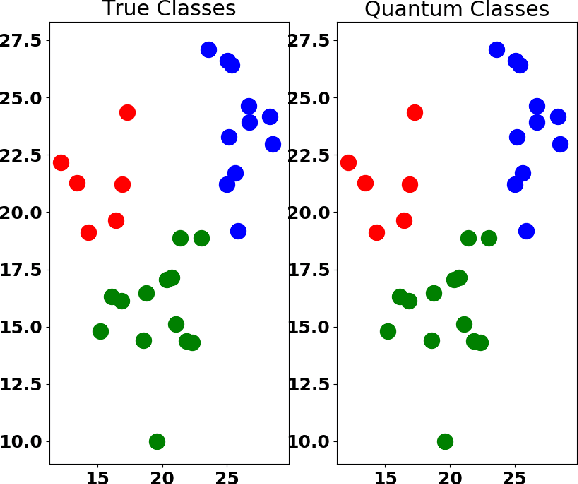
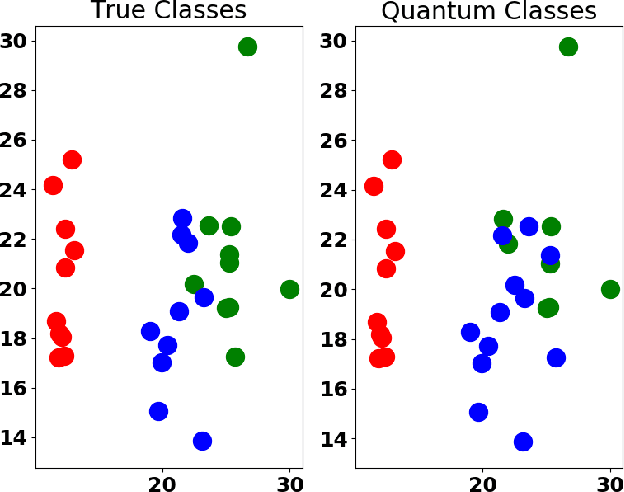
Machine learning algorithms perform well on identifying patterns in many datasets due to their versatility. However, as one increases the size of the data, the time for training and using these statistical models grows quickly. Here, we propose and implement on the IBMQ a quantum analogue to K-means clustering, and compare it to a previously developed quantum support vector machine. We find the algorithm's accuracy comparable to classical K-means for clustering and classification problems, and find that it becomes less computationally expensive to implement for large datasets.
* 6 pages, 4 figures, 2 tables
View paper on