 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Centered AI for Indian Legal Text Analytics
Mar 16, 2024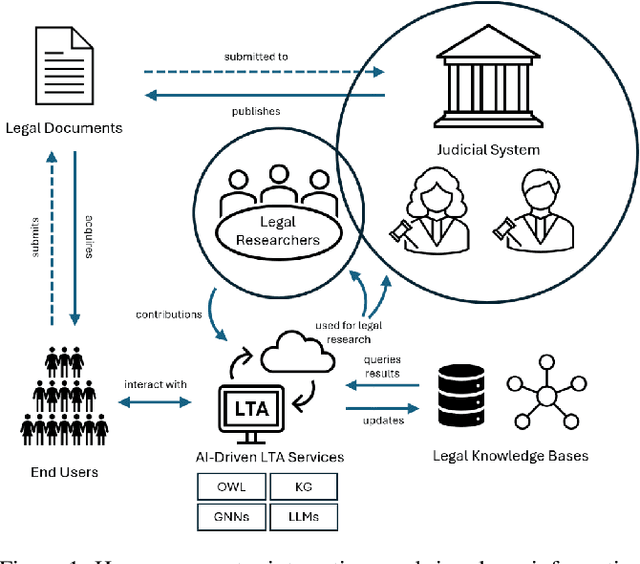
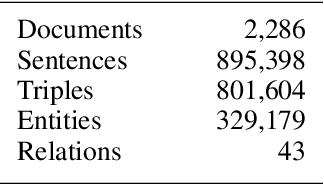


Legal research is a crucial task in the practice of law. It requires intense human effort and intellectual prudence to research a legal case and prepare arguments. Recent boom in generative AI has not translated to proportionate rise in impactful legal applications, because of low trustworthiness and and the scarcity of specialized datasets for training Large Language Models (LLMs). This position paper explores the potential of LLMs within Legal Text Analytics (LTA), highlighting specific areas where the integration of human expertise can significantly enhance their performance to match that of experts. We introduce a novel dataset and describe a human centered, compound AI system that principally incorporates human inputs for performing LTA tasks with LLMs.
xLP: Explainable Link Prediction for Master Data Management
Mar 14, 2024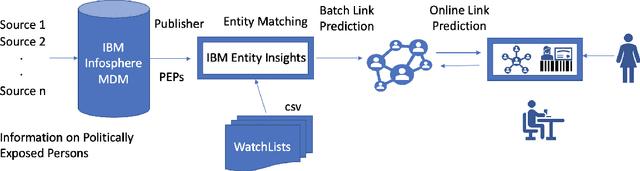
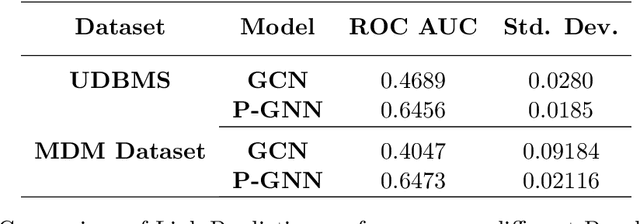
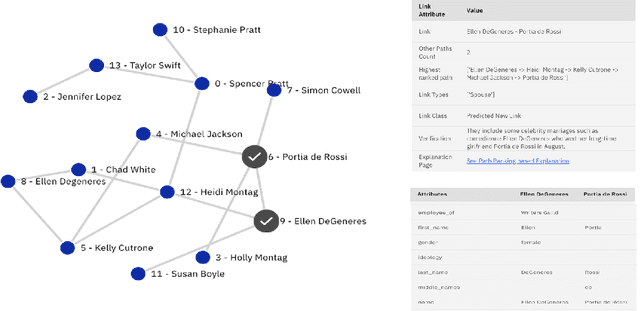

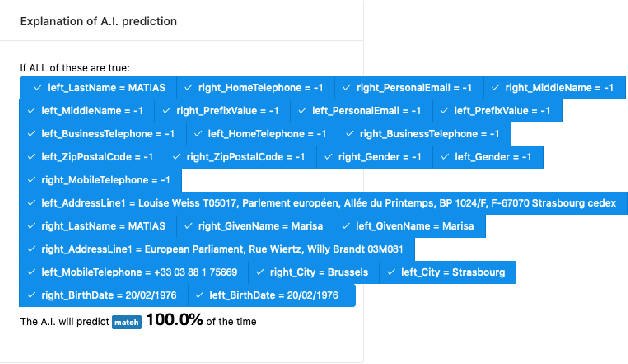
Explaining neural model predictions to users requires creativity. Especially in enterprise applications, where there are costs associated with users' time, and their trust in the model predictions is critical for adoption. For link prediction in master data management, we have built a number of explainability solutions drawing from research in interpretability, fact verification, path ranking, neuro-symbolic reasoning and self-explaining AI. In this demo, we present explanations for link prediction in a creative way, to allow users to choose explanations they are more comfortable with.
Infusing Knowledge into Large Language Models with Contextual Prompts
Mar 03, 2024Knowledge infusion is a promising method for enhancing Large Language Models for domain-specific NLP tasks rather than pre-training models over large data from scratch. These augmented LLMs typically depend on additional pre-training or knowledge prompts from an existing knowledge graph, which is impractical in many applications. In contrast, knowledge infusion directly from relevant documents is more generalisable and alleviates the need for structured knowledge graphs while also being useful for entities that are usually not found in any knowledge graph. With this motivation, we propose a simple yet generalisable approach for knowledge infusion by generating prompts from the context in the input text. Our experiments show the effectiveness of our approach which we evaluate by probing the fine-tuned LLMs.
Foundation Model Sherpas: Guiding Foundation Models through Knowledge and Reasoning
Feb 02, 2024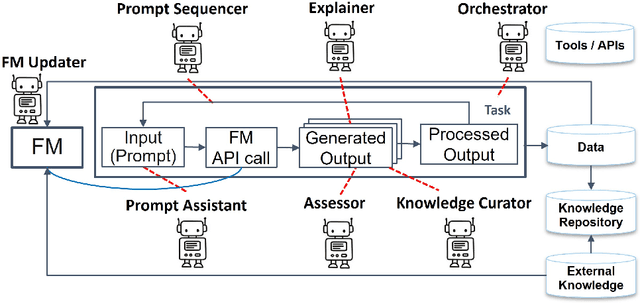


Foundation models (FMs) such as large language models have revolutionized the field of AI by showing remarkable performance in various tasks. However, they exhibit numerous limitations that prevent their broader adoption in many real-world systems, which often require a higher bar for trustworthiness and usability. Since FMs are trained using loss functions aimed at reconstructing the training corpus in a self-supervised manner, there is no guarantee that the model's output aligns with users' preferences for a specific task at hand. In this survey paper, we propose a conceptual framework that encapsulates different modes by which agents could interact with FMs and guide them suitably for a set of tasks, particularly through knowledge augmentation and reasoning. Our framework elucidates agent role categories such as updating the underlying FM, assisting with prompting the FM, and evaluating the FM output. We also categorize several state-of-the-art approaches into agent interaction protocols, highlighting the nature and extent of involvement of the various agent roles. The proposed framework provides guidance for future directions to further realize the power of FMs in practical AI systems.
Automated Answer Validation using Text Similarity
Jan 13, 2024Automated answer validation can help improve learning outcomes by providing appropriate feedback to learners, and by making question answering systems and online learning solutions more widely available. There have been some works in science question answering which show that information retrieval methods outperform neural methods, especially in the multiple choice version of this problem. We implement Siamese neural network models and produce a generalised solution to this problem. We compare our supervised model with other text similarity based solutions.
xEM: Explainable Entity Matching in Customer 360
Dec 01, 2022



Entity matching in Customer 360 is the task of determining if multiple records represent the same real world entity. Entities are typically people, organizations, locations, and events represented as attributed nodes in a graph, though they can also be represented as records in relational data. While probabilistic matching engines and artificial neural network models exist for this task, explaining entity matching has received less attention. In this demo, we present our Explainable Entity Matching (xEM) system and discuss the different AI/ML considerations that went into its implementation.
Similar Cases Recommendation using Legal Knowledge Graphs
Jul 10, 2021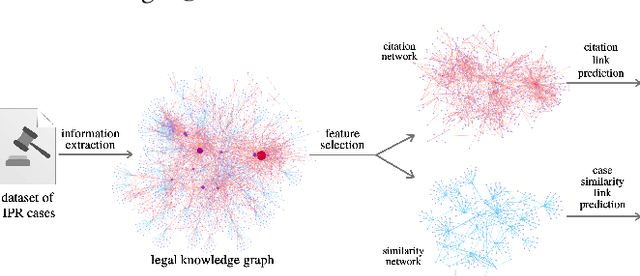

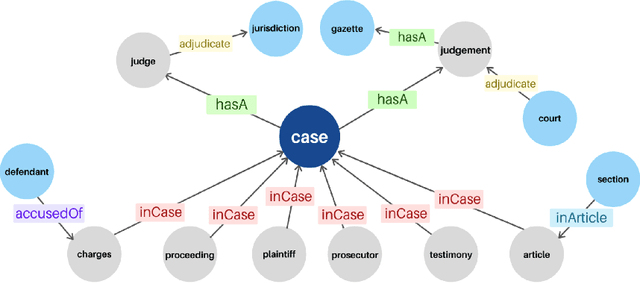
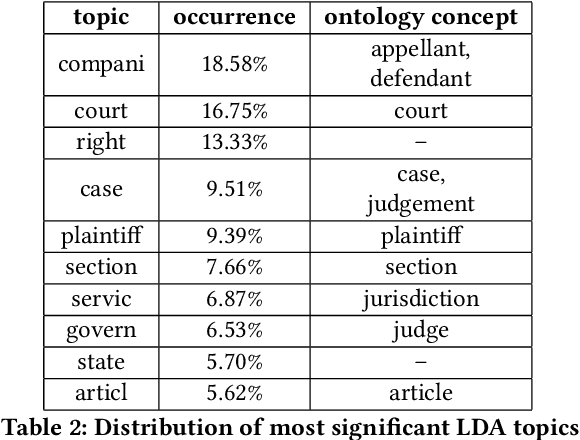
A legal knowledge graph constructed from court cases, judgments, laws and other legal documents can enable a number of applications like question answering, document similarity, and search. While the use of knowledge graphs for distant supervision in NLP tasks is well researched, using knowledge graphs for downstream graph tasks like node similarity presents challenges in selecting node types and their features. In this demo, we describe our solution for predicting similar nodes in a case graph derived from our legal knowledge graph.
Reimagining GNN Explanations with ideas from Tabular Data
Jun 23, 2021
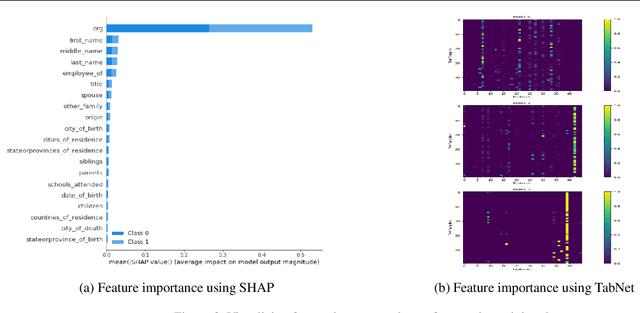

Explainability techniques for Graph Neural Networks still have a long way to go compared to explanations available for both neural and decision decision tree-based models trained on tabular data. Using a task that straddles both graphs and tabular data, namely Entity Matching, we comment on key aspects of explainability that are missing in GNN model explanations.
Towards Automated Evaluation of Explanations in Graph Neural Networks
Jun 22, 2021


Explaining Graph Neural Networks predictions to end users of AI applications in easily understandable terms remains an unsolved problem. In particular, we do not have well developed methods for automatically evaluating explanations, in ways that are closer to how users consume those explanations. Based on recent application trends and our own experiences in real world problems, we propose automatic evaluation approaches for GNN Explanations.
Document Structure aware Relational Graph Convolutional Networks for Ontology Population
Apr 27, 2021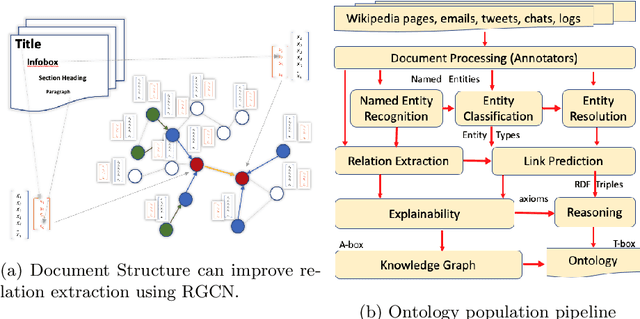
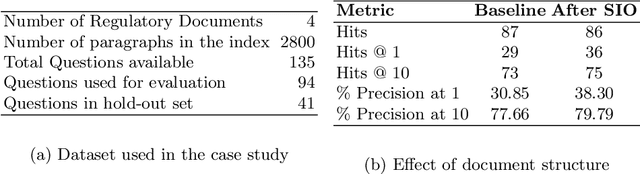
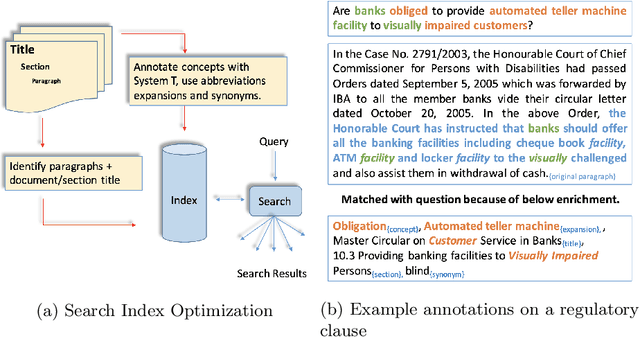
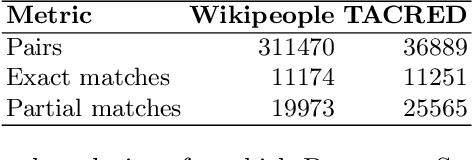
Ontologies comprising of concepts, their attributes, and relationships, form the quintessential backbone of many knowledge based AI systems. These systems manifest in the form of question-answering or dialogue in number of business analytics and master data management applications. While there have been efforts towards populating domain specific ontologies, we examine the role of document structure in learning ontological relationships between concepts in any document corpus. Inspired by ideas from hypernym discovery and explainability, our method performs about 15 points more accurate than a stand-alone R-GCN model for this task.