 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI autonomously build, operate, and use the entire data stack?
Dec 08, 2025Enterprise data management is a monumental task. It spans data architecture and systems, integration, quality, governance, and continuous improvement. While AI assistants can help specific persona, such as data engineers and stewards, to navigate and configure the data stack, they fall far short of full automation. However, as AI becomes increasingly capable of tackling tasks that have previously resisted automation due to inherent complexities, we believe there is an imminent opportunity to target fully autonomous data estates. Currently, AI is used in different parts of the data stack, but in this paper, we argue for a paradigm shift from the use of AI in independent data component operations towards a more holistic and autonomous handling of the entire data lifecycle. Towards that end, we explore how each stage of the modern data stack can be autonomously managed by intelligent agents to build self-sufficient systems that can be used not only by human end-users, but also by AI itself. We begin by describing the mounting forces and opportunities that demand this paradigm shift, examine how agents can streamline the data lifecycle, and highlight open questions and areas where additional research is needed. We hope this work will inspire lively debate, stimulate further research, motivate collaborative approaches, and facilitate a more autonomous future for data systems.
LLM driven Text-to-Table Generation through Sub-Tasks Guidance and Iterative Refinement
Aug 12, 2025Transforming unstructured text into structured data is a complex task, requiring semantic understanding, reasoning, and structural comprehension. While Large Language Models (LLMs) offer potential, they often struggle with handling ambiguous or domain-specific data, maintaining table structure, managing long inputs, and addressing numerical reasoning. This paper proposes an efficient system for LLM-driven text-to-table generation that leverages novel prompting techniques. Specifically, the system incorporates two key strategies: breaking down the text-to-table task into manageable, guided sub-tasks and refining the generated tables through iterative self-feedback. We show that this custom task decomposition allows the model to address the problem in a stepwise manner and improves the quality of the generated table. Furthermore, we discuss the benefits and potential risks associated with iterative self-feedback on the generated tables while highlighting the trade-offs between enhanced performance and computational cost. Our methods achieve strong results compared to baselines on two complex text-to-table generation datasets available in the public domain.
Towards Automated Evaluation of Explanations in Graph Neural Networks
Jun 22, 2021


Explaining Graph Neural Networks predictions to end users of AI applications in easily understandable terms remains an unsolved problem. In particular, we do not have well developed methods for automatically evaluating explanations, in ways that are closer to how users consume those explanations. Based on recent application trends and our own experiences in real world problems, we propose automatic evaluation approaches for GNN Explanations.
Multifaceted Context Representation using Dual Attention for Ontology Alignment
Oct 26, 2020



Ontology Alignment is an important research problem that finds application in various fields such as data integration, data transfer, data preparation etc. State-of-the-art (SOTA) architectures in Ontology Alignment typically use naive domain-dependent approaches with handcrafted rules and manually assigned values, making them unscalable and inefficient. Deep Learning approaches for ontology alignment use domain-specific architectures that are not only in-extensible to other datasets and domains, but also typically perform worse than rule-based approaches due to various limitations including over-fitting of models, sparsity of datasets etc. In this work, we propose VeeAlign, a Deep Learning based model that uses a dual-attention mechanism to compute the contextualized representation of a concept in order to learn alignments. By doing so, not only does our approach exploit both syntactic and semantic structure of ontologies, it is also, by design, flexible and scalable to different domains with minimal effort. We validate our approach on various datasets from different domains and in multilingual settings, and show its superior performance over SOTA methods.
Compliance Change Tracking in Business Process Services
Aug 20, 2019



Regulatory compliance is an organization's adherence to laws, regulations, guidelines and specifications relevant to its business. Compliance officers responsible for maintaining adherence constantly struggle to keep up with the large amount of changes in regulatory requirements. Keeping up with the changes entail two main tasks: fetching the regulatory announcements that actually contain changes of interest, and incorporating those changes in the business process. In this paper we focus on the first task, and present a Compliance Change Tracking System, that gathers regulatory announcements from government sites, news sites, email subscriptions; classifies their importance i.e Actionability through a hierarchical classifier, and business process applicability through a multi-class classifier. For these classifiers, we experiment with several approaches such as vanilla classification methods (e.g. Naive Bayes, logistic regression etc.), hierarchical classification methods, rule based approach, hybrid approach with various preprocessing and feature selection methods; and show that despite the richness of other models, a simple hierarchical classification with bag-of-words features works the best for Actionability classifier and multi-class logistic regression works the best for Applicability classifier. The system has been deployed in global delivery centers, and has received positive feedback from payroll compliance officers.
A Deep Generative Framework for Paraphrase Generation
Sep 15, 2017



Paraphrase generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. In this paper, we address the problem of generating paraphrases automatically. Our proposed method is based on a combination of deep generative models (VAE) with sequence-to-sequence models (LSTM) to generate paraphrases, given an input sentence. Traditional VAEs when combined with recurrent neural networks can generate free text but they are not suitable for paraphrase generation for a given sentence. We address this problem by conditioning the both, encoder and decoder sides of VAE, on the original sentence, so that it can generate the given sentence's paraphrases. Unlike most existing models, our model is simple, modular and can generate multiple paraphrases, for a given sentence. Quantitative evaluation of the proposed method on a benchmark paraphrase dataset demonstrates its efficacy, and its performance improvement over the state-of-the-art methods by a significant margin, whereas qualitative human evaluation indicate that the generated paraphrases are well-formed, grammatically correct, and are relevant to the input sentence. Furthermore, we evaluate our method on a newly released question paraphrase dataset, and establish a new baseline for future research.
Dialogue Act Sequence Labeling using Hierarchical encoder with CRF
Sep 14, 2017



Dialogue Act recognition associate dialogue acts (i.e., semantic labels) to utterances in a conversation. The problem of associating semantic labels to utterances can be treated as a sequence labeling problem. In this work, we build a hierarchical recurrent neural network using bidirectional LSTM as a base unit and the conditional random field (CRF) as the top layer to classify each utterance into its corresponding dialogue act. The hierarchical network learns representations at multiple levels, i.e., word level, utterance level, and conversation level. The conversation level representations are input to the CRF layer, which takes into account not only all previous utterances but also their dialogue acts, thus modeling the dependency among both, labels and utterances, an important consideration of natural dialogue. We validate our approach on two different benchmark data sets, Switchboard and Meeting Recorder Dialogue Act, and show performance improvement over the state-of-the-art methods by $2.2\%$ and $4.1\%$ absolute points, respectively. It is worth noting that the inter-annotator agreement on Switchboard data set is $84\%$, and our method is able to achieve the accuracy of about $79\%$ despite being trained on the noisy data.
Multitask Learning for Sequence Labeling Tasks
May 09, 2016


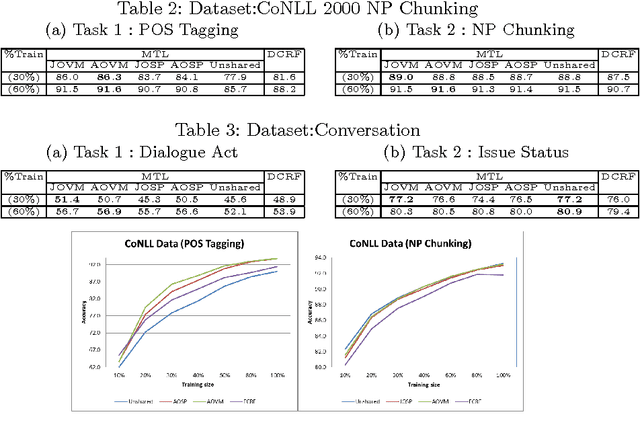
In this paper, we present a learning method for sequence labeling tasks in which each example sequence has multiple label sequences. Our method learns multiple models, one model for each label sequence. Each model computes the joint probability of all label sequences given the example sequence. Although each model considers all label sequences, its primary focus is only one label sequence, and therefore, each model becomes a task-specific model, for the task belonging to that primary label. Such multiple models are learned {\it simultaneously} by facilitating the learning transfer among models through {\it explicit parameter sharing}. We experiment the proposed method on two applications and show that our method significantly outperforms the state-of-the-art method.
A Geometric View of Conjugate Priors
May 01, 2010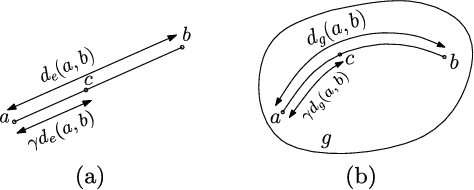

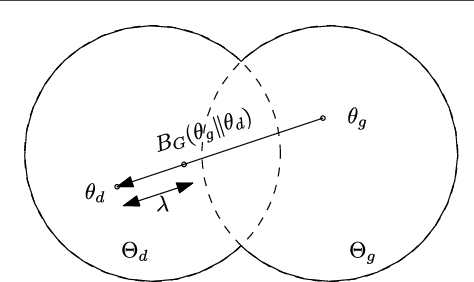
In Bayesian machine learning, conjugate priors are popular, mostly due to mathematical convenience. In this paper, we show that there are deeper reasons for choosing a conjugate prior. Specifically, we formulate the conjugate prior in the form of Bregman divergence and show that it is the inherent geometry of conjugate priors that makes them appropriate and intuitive. This geometric interpretation allows one to view the hyperparameters of conjugate priors as the {\it effective} sample points, thus providing additional intuition. We use this geometric understanding of conjugate priors to derive the hyperparameters and expression of the prior used to couple the generative and discriminative components of a hybrid model for semi-supervised learning.
A Unified Algorithmic Framework for Multi-Dimensional Scaling
Mar 30, 2010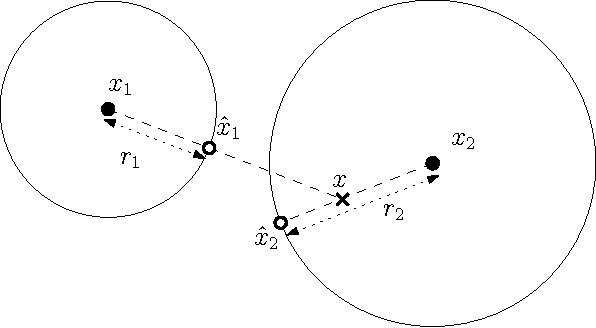

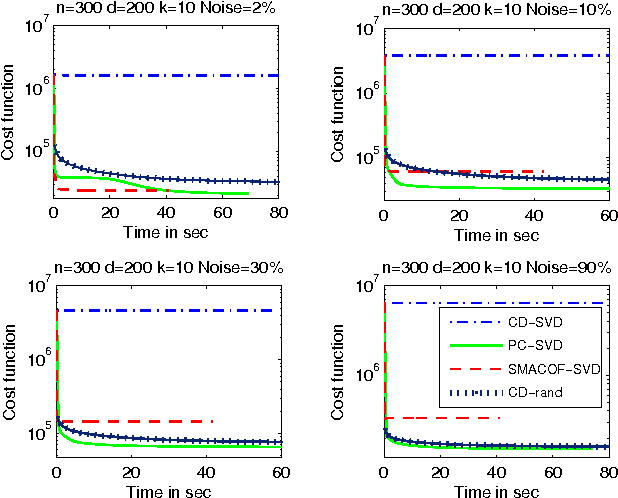
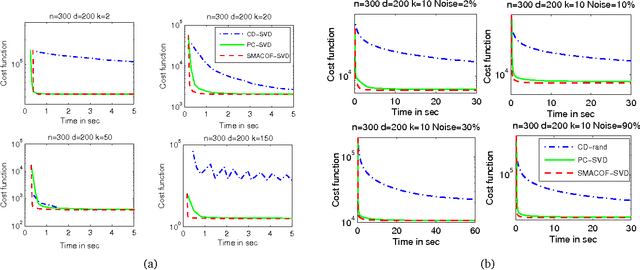
In this paper, we propose a unified algorithmic framework for solving many known variants of \mds. Our algorithm is a simple iterative scheme with guaranteed convergence, and is \emph{modular}; by changing the internals of a single subroutine in the algorithm, we can switch cost functions and target spaces easily. In addition to the formal guarantees of convergence, our algorithms are accurate; in most cases, they converge to better quality solutions than existing methods, in comparable time. We expect that this framework will be useful for a number of \mds variants that have not yet been studied. Our framework extends to embedding high-dimensional points lying on a sphere to points on a lower dimensional sphere, preserving geodesic distances. As a compliment to this result, we also extend the Johnson-Lindenstrauss Lemma to this spherical setting, where projecting to a random $O((1/\eps^2) \log n)$-dimensional sphere causes $\eps$-distortion.