 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Architecture for Person Ontology population
Jan 22, 2020

A person ontology comprising concepts, attributes and relationships of people has a number of applications in data protection, didentification, population of knowledge graphs for business intelligence and fraud prevention. While artificial neural networks have led to improvements in Entity Recognition, Entity Classification, and Relation Extraction, creating an ontology largely remains a manual process, because it requires a fixed set of semantic relations between concepts. In this work, we present a system for automatically populating a person ontology graph from unstructured data using neural models for Entity Classification and Relation Extraction. We introduce a new dataset for these tasks and discuss our results.
"You might also like this model": Data Driven Approach for Recommending Deep Learning Models for Unknown Image Datasets
Nov 26, 2019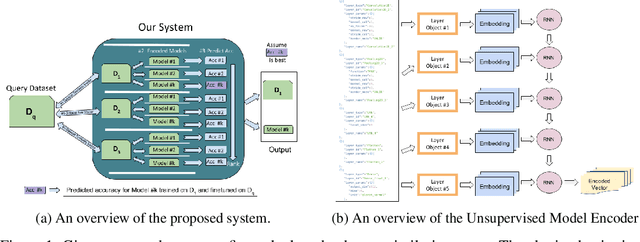
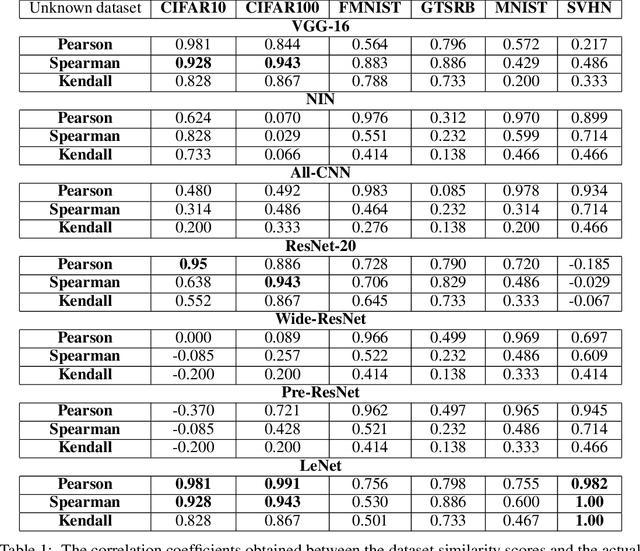
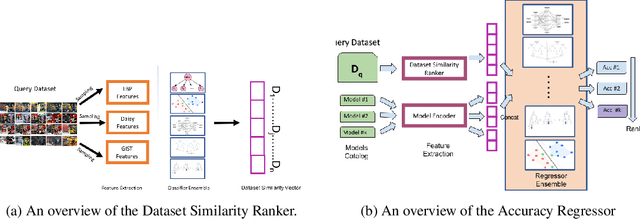

For an unknown (new) classification dataset, choosing an appropriate deep learning architecture is often a recursive, time-taking, and laborious process. In this research, we propose a novel technique to recommend a suitable architecture from a repository of known models. Further, we predict the performance accuracy of the recommended architecture on the given unknown dataset, without the need for training the model. We propose a model encoder approach to learn a fixed length representation of deep learning architectures along with its hyperparameters, in an unsupervised fashion. We manually curate a repository of image datasets with corresponding known deep learning models and show that the predicted accuracy is a good estimator of the actual accuracy. We discuss the implications of the proposed approach for three benchmark images datasets and also the challenges in using the approach for text modality. To further increase the reproducibility of the proposed approach, the entire implementation is made publicly available along with the trained models.
Fine Grained Classification of Personal Data Entities
Nov 23, 2018
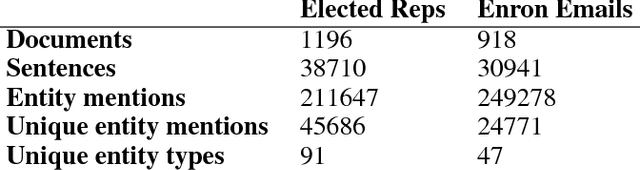
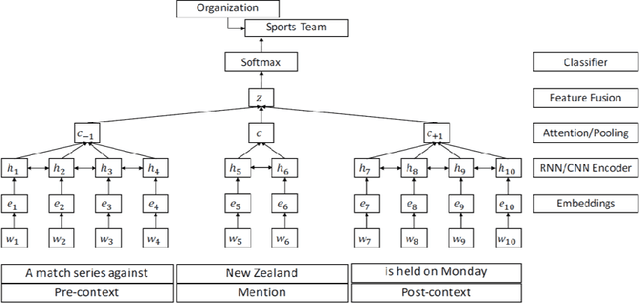
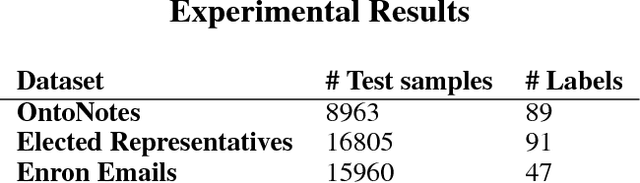
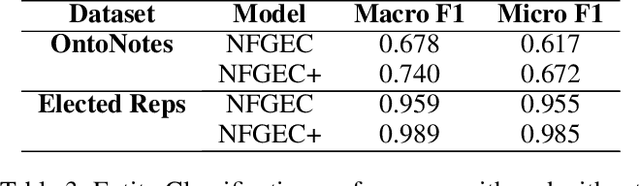
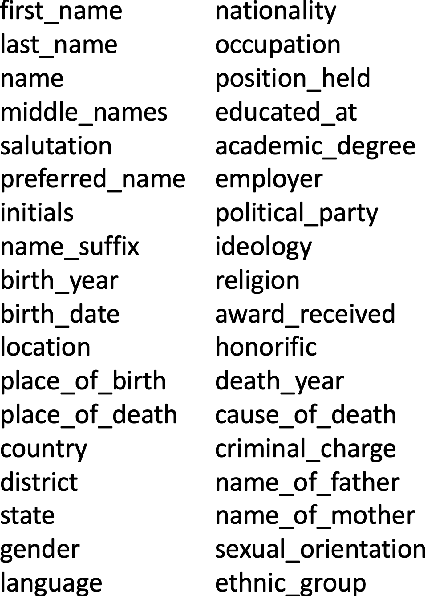
Entity Type Classification can be defined as the task of assigning category labels to entity mentions in documents. While neural networks have recently improved the classification of general entity mentions, pattern matching and other systems continue to be used for classifying personal data entities (e.g. classifying an organization as a media company or a government institution for GDPR, and HIPAA compliance). We propose a neural model to expand the class of personal data entities that can be classified at a fine grained level, using the output of existing pattern matching systems as additional contextual features. We introduce new resources, a personal data entities hierarchy with 134 types, and two datasets from the Wikipedia pages of elected representatives and Enron emails. We hope these resource will aid research in the area of personal data discovery, and to that effect, we provide baseline results on these datasets, and compare our method with state of the art models on OntoNotes dataset.
Dialogue Act Sequence Labeling using Hierarchical encoder with CRF
Sep 14, 2017



Dialogue Act recognition associate dialogue acts (i.e., semantic labels) to utterances in a conversation. The problem of associating semantic labels to utterances can be treated as a sequence labeling problem. In this work, we build a hierarchical recurrent neural network using bidirectional LSTM as a base unit and the conditional random field (CRF) as the top layer to classify each utterance into its corresponding dialogue act. The hierarchical network learns representations at multiple levels, i.e., word level, utterance level, and conversation level. The conversation level representations are input to the CRF layer, which takes into account not only all previous utterances but also their dialogue acts, thus modeling the dependency among both, labels and utterances, an important consideration of natural dialogue. We validate our approach on two different benchmark data sets, Switchboard and Meeting Recorder Dialogue Act, and show performance improvement over the state-of-the-art methods by $2.2\%$ and $4.1\%$ absolute points, respectively. It is worth noting that the inter-annotator agreement on Switchboard data set is $84\%$, and our method is able to achieve the accuracy of about $79\%$ despite being trained on the noisy data.