 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Structure aware Relational Graph Convolutional Networks for Ontology Population
Apr 27, 2021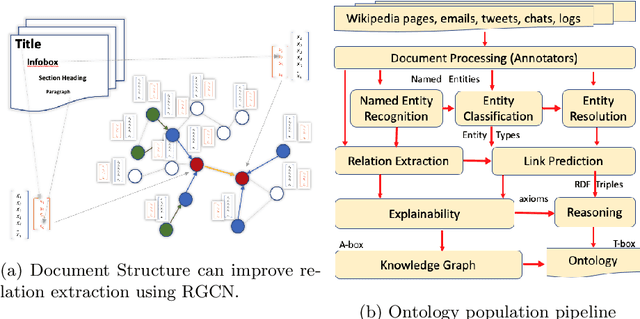
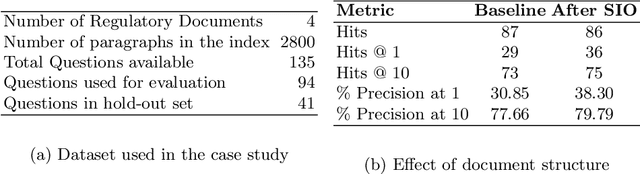
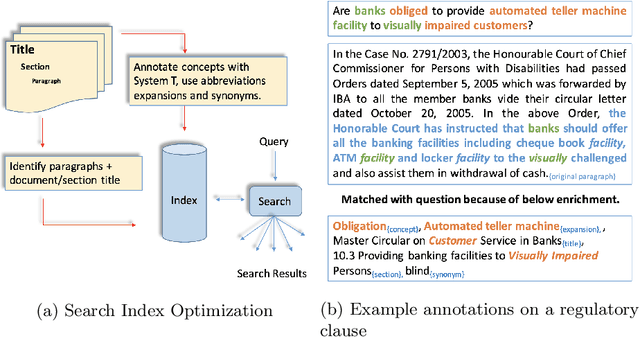
Ontologies comprising of concepts, their attributes, and relationships, form the quintessential backbone of many knowledge based AI systems. These systems manifest in the form of question-answering or dialogue in number of business analytics and master data management applications. While there have been efforts towards populating domain specific ontologies, we examine the role of document structure in learning ontological relationships between concepts in any document corpus. Inspired by ideas from hypernym discovery and explainability, our method performs about 15 points more accurate than a stand-alone R-GCN model for this task.
Document Structure Measure for Hypernym discovery
Nov 30, 2018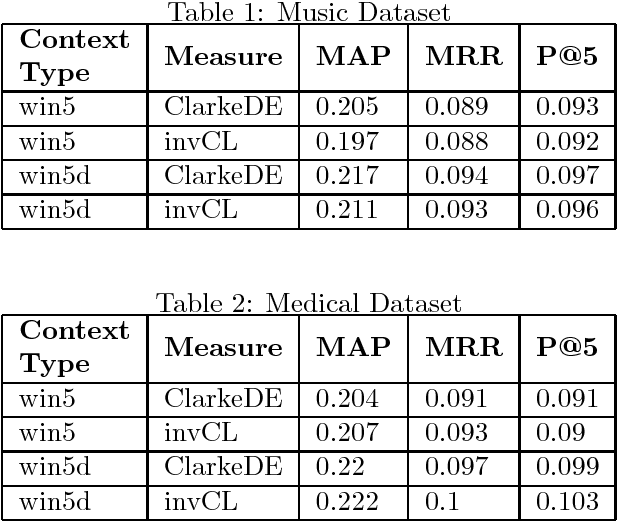
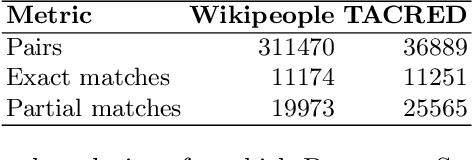
Hypernym discovery is the problem of finding terms that have is-a relationship with a given term. We introduce a new context type, and a relatedness measure to differentiate hypernyms from other types of semantic relationships. Our Document Structure measure is based on hierarchical position of terms in a document, and their presence or otherwise in definition text. This measure quantifies the document structure using multiple attributes, and classes of weighted distance functions.
Fine Grained Classification of Personal Data Entities
Nov 23, 2018
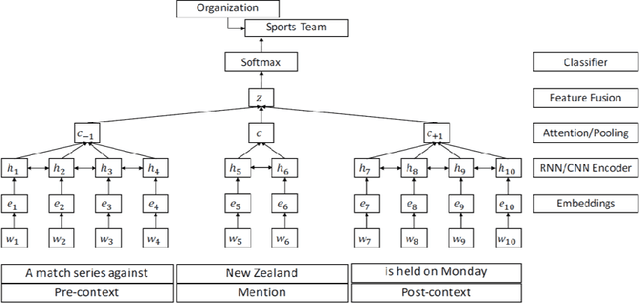
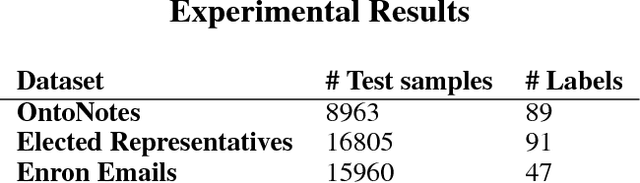
Entity Type Classification can be defined as the task of assigning category labels to entity mentions in documents. While neural networks have recently improved the classification of general entity mentions, pattern matching and other systems continue to be used for classifying personal data entities (e.g. classifying an organization as a media company or a government institution for GDPR, and HIPAA compliance). We propose a neural model to expand the class of personal data entities that can be classified at a fine grained level, using the output of existing pattern matching systems as additional contextual features. We introduce new resources, a personal data entities hierarchy with 134 types, and two datasets from the Wikipedia pages of elected representatives and Enron emails. We hope these resource will aid research in the area of personal data discovery, and to that effect, we provide baseline results on these datasets, and compare our method with state of the art models on OntoNotes dataset.