 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise in Relation Classification Dataset TACRED: Characterization and Reduction
Nov 21, 2023The overarching objective of this paper is two-fold. First, to explore model-based approaches to characterize the primary cause of the noise. in the RE dataset TACRED Second, to identify the potentially noisy instances. Towards the first objective, we analyze predictions and performance of state-of-the-art (SOTA) models to identify the root cause of noise in the dataset. Our analysis of TACRED shows that the majority of the noise in the dataset originates from the instances labeled as no-relation which are negative examples. For the second objective, we explore two nearest-neighbor-based strategies to automatically identify potentially noisy examples for elimination and reannotation. Our first strategy, referred to as Intrinsic Strategy (IS), is based on the assumption that positive examples are clean. Thus, we have used false-negative predictions to identify noisy negative examples. Whereas, our second approach, referred to as Extrinsic Strategy, is based on using a clean subset of the dataset to identify potentially noisy negative examples. Finally, we retrained the SOTA models on the eliminated and reannotated dataset. Our empirical results based on two SOTA models trained on TACRED-E following the IS show an average 4% F1-score improvement, whereas reannotation (TACRED-R) does not improve the original results. However, following ES, SOTA models show the average F1-score improvement of 3.8% and 4.4% when trained on respective eliminated (TACRED-EN) and reannotated (TACRED-RN) datasets respectively. We further extended the ES for cleaning positive examples as well, which resulted in an average performance improvement of 5.8% and 5.6% for the eliminated (TACRED-ENP) and reannotated (TACRED-RNP) datasets respectively.
Budget Sensitive Reannotation of Noisy Relation Classification Data Using Label Hierarchy
Dec 26, 2021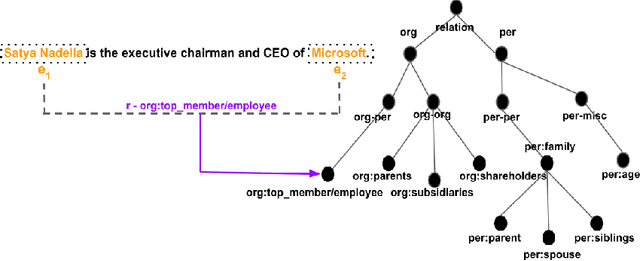
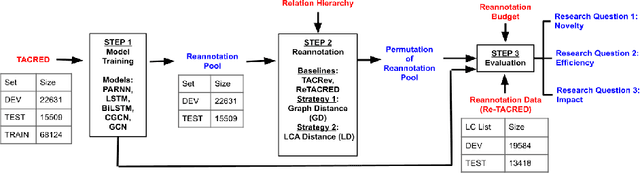

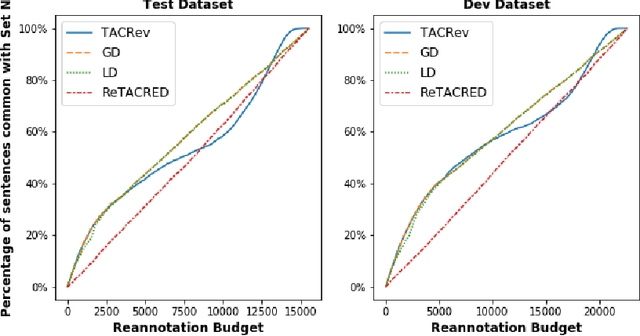
Large crowd-sourced datasets are often noisy and relation classification (RC) datasets are no exception. Reannotating the entire dataset is one probable solution however it is not always viable due to time and budget constraints. This paper addresses the problem of efficient reannotation of a large noisy dataset for the RC. Our goal is to catch more annotation errors in the dataset while reannotating fewer instances. Existing work on RC dataset reannotation lacks the flexibility about how much data to reannotate. We introduce the concept of a reannotation budget to overcome this limitation. The immediate follow-up problem is: Given a specific reannotation budget, which subset of the data should we reannotate? To address this problem, we present two strategies to selectively reannotate RC datasets. Our strategies utilize the taxonomic hierarchy of relation labels. The intuition of our work is to rely on the graph distance between actual and predicted relation labels in the label hierarchy graph. We evaluate our reannotation strategies on the well-known TACRED dataset. We design our experiments to answer three specific research questions. First, does our strategy select novel candidates for reannotation? Second, for a given reannotation budget is our reannotation strategy more efficient at catching annotation errors? Third, what is the impact of data reannotation on RC model performance measurement? Experimental results show that our both reannotation strategies are novel and efficient. Our analysis indicates that the current reported performance of RC models on noisy TACRED data is inflated.
A Neural Architecture for Person Ontology population
Jan 22, 2020
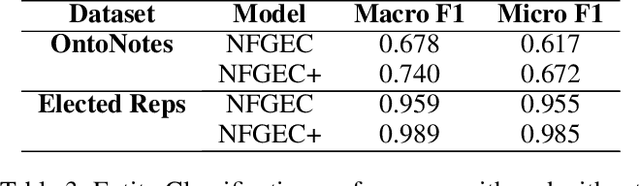

A person ontology comprising concepts, attributes and relationships of people has a number of applications in data protection, didentification, population of knowledge graphs for business intelligence and fraud prevention. While artificial neural networks have led to improvements in Entity Recognition, Entity Classification, and Relation Extraction, creating an ontology largely remains a manual process, because it requires a fixed set of semantic relations between concepts. In this work, we present a system for automatically populating a person ontology graph from unstructured data using neural models for Entity Classification and Relation Extraction. We introduce a new dataset for these tasks and discuss our results.
Taxonomical hierarchy of canonicalized relations from multiple Knowledge Bases
Sep 17, 2019
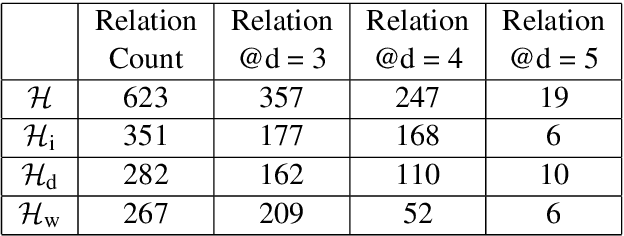


This work addresses two important questions pertinent to Relation Extraction (RE). First, what are all possible relations that could exist between any two given entity types? Second, how do we define an unambiguous taxonomical (is-a) hierarchy among the identified relations? To address the first question, we use three resources Wikipedia Infobox, Wikidata, and DBpedia. This study focuses on relations between person, organization and location entity types. We exploit Wikidata and DBpedia in a data-driven manner, and Wikipedia Infobox templates manually to generate lists of relations. Further, to address the second question, we canonicalize, filter, and combine the identified relations from the three resources to construct a taxonomical hierarchy. This hierarchy contains 623 canonical relations with highest contribution from Wikipedia Infobox followed by DBpedia and Wikidata. The generated relation list subsumes an average of 85% of relations from RE datasets when entity types are restricted.