 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugAbEx : Way Forward for Extractive Case Summarization
Nov 15, 2025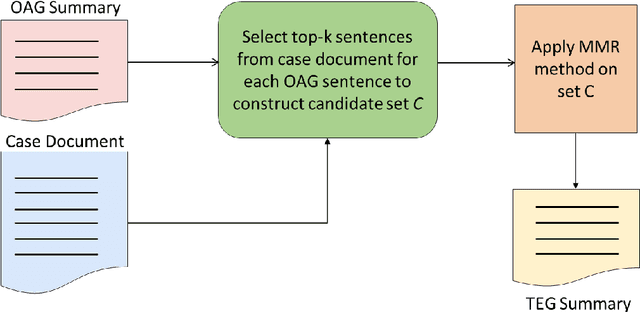
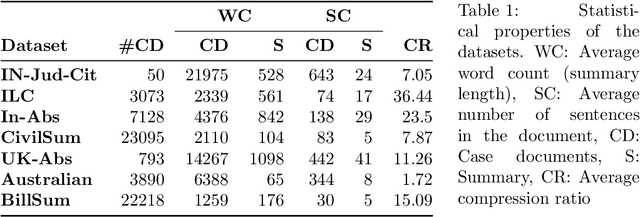
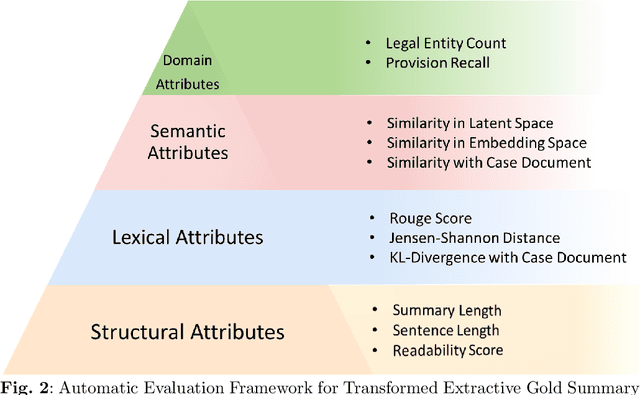
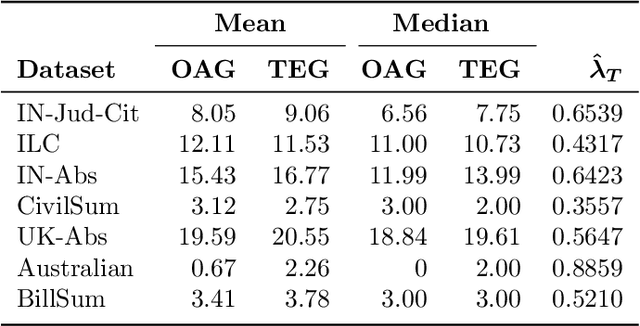
Summarization of legal judgments poses a heavy cognitive burden on law practitioners due to the complexity of the language, context-sensitive legal jargon, and the length of the document. Therefore, the automatic summarization of legal documents has attracted serious attention from natural language processing researchers. Since the abstractive summaries of legal documents generated by deep neural methods remain prone to the risk of misrepresenting nuanced legal jargon or overlooking key contextual details, we envisage a rising trend toward the use of extractive case summarizers. Given the high cost of human annotation for gold standard extractive summaries, we engineer a light and transparent pipeline that leverages existing abstractive gold standard summaries to create the corresponding extractive gold standard versions. The approach ensures that the experts` opinions ensconced in the original gold standard abstractive summaries are carried over to the transformed extractive summaries. We aim to augment seven existing case summarization datasets, which include abstractive summaries, by incorporating corresponding extractive summaries and create an enriched data resource for case summarization research community. To ensure the quality of the augmented extractive summaries, we perform an extensive comparative evaluation with the original abstractive gold standard summaries covering structural, lexical, and semantic dimensions. We also compare the domain-level information of the two summaries. We commit to release the augmented datasets in the public domain for use by the research community and believe that the resource will offer opportunities to advance the field of automatic summarization of legal documents.
Citation-Based Summarization of Landmark Judgments
Jun 16, 2024



Landmark judgments are of prime importance in the Common Law System because of their exceptional jurisprudence and frequent references in other judgments. In this work, we leverage contextual references available in citing judgments to create an extractive summary of the target judgment. We evaluate the proposed algorithm on two datasets curated from the judgments of Indian Courts and find the results promising.
Human Centered AI for Indian Legal Text Analytics
Mar 16, 2024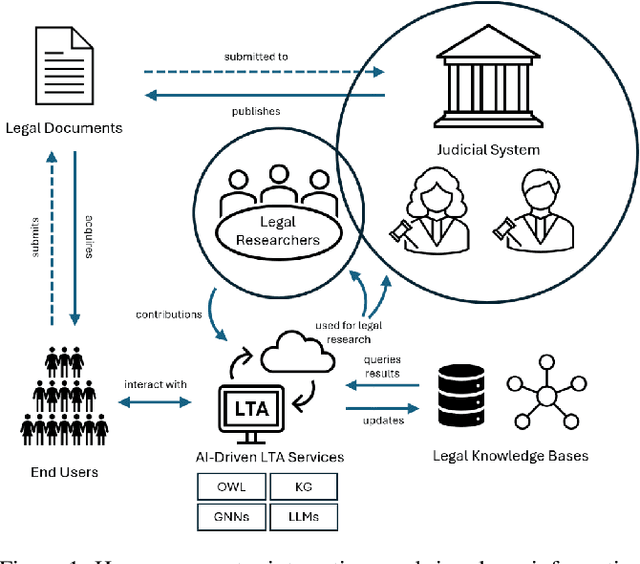


Legal research is a crucial task in the practice of law. It requires intense human effort and intellectual prudence to research a legal case and prepare arguments. Recent boom in generative AI has not translated to proportionate rise in impactful legal applications, because of low trustworthiness and and the scarcity of specialized datasets for training Large Language Models (LLMs). This position paper explores the potential of LLMs within Legal Text Analytics (LTA), highlighting specific areas where the integration of human expertise can significantly enhance their performance to match that of experts. We introduce a novel dataset and describe a human centered, compound AI system that principally incorporates human inputs for performing LTA tasks with LLMs.
Infusing Knowledge into Large Language Models with Contextual Prompts
Mar 03, 2024



Knowledge infusion is a promising method for enhancing Large Language Models for domain-specific NLP tasks rather than pre-training models over large data from scratch. These augmented LLMs typically depend on additional pre-training or knowledge prompts from an existing knowledge graph, which is impractical in many applications. In contrast, knowledge infusion directly from relevant documents is more generalisable and alleviates the need for structured knowledge graphs while also being useful for entities that are usually not found in any knowledge graph. With this motivation, we propose a simple yet generalisable approach for knowledge infusion by generating prompts from the context in the input text. Our experiments show the effectiveness of our approach which we evaluate by probing the fine-tuned LLMs.
Deep dive into language traits of AI-generated Abstracts
Dec 17, 2023



Generative language models, such as ChatGPT, have garnered attention for their ability to generate human-like writing in various fields, including academic research. The rapid proliferation of generated texts has bolstered the need for automatic identification to uphold transparency and trust in the information. However, these generated texts closely resemble human writing and often have subtle differences in the grammatical structure, tones, and patterns, which makes systematic scrutinization challenging. In this work, we attempt to detect the Abstracts generated by ChatGPT, which are much shorter in length and bounded. We extract the texts semantic and lexical properties and observe that traditional machine learning models can confidently detect these Abstracts.
I Want This, Not That: Personalized Summarization of Scientific Scholarly Texts
Jun 16, 2023



In this paper, we present a proposal for an unsupervised algorithm, P-Summ, that generates an extractive summary of scientific scholarly text to meet the personal knowledge needs of the user. The method delves into the latent semantic space of the document exposed by Weighted Non-negative Matrix Factorization, and scores sentences in consonance with the knowledge needs of the user. The novelty of the algorithm lies in its ability to include desired knowledge and eliminate unwanted knowledge in the personal summary. We also propose a multi-granular evaluation framework, which assesses the quality of generated personal summaries at three levels of granularity - sentence, terms and semantic. The framework uses system generated generic summary instead of human generated summary as gold standard for evaluating the quality of personal summary generated by the algorithm. The effectiveness of the algorithm at the semantic level is evaluated by taking into account the reference summary and the knowledge signals. We evaluate the performance of P-Summ algorithm over four data-sets consisting of scientific articles. Our empirical investigations reveal that the proposed method has the capability to meet negative (or positive) knowledge preferences of the user.
Quantitative Discourse Cohesion Analysis of Scientific Scholarly Texts using Multilayer Networks
May 16, 2022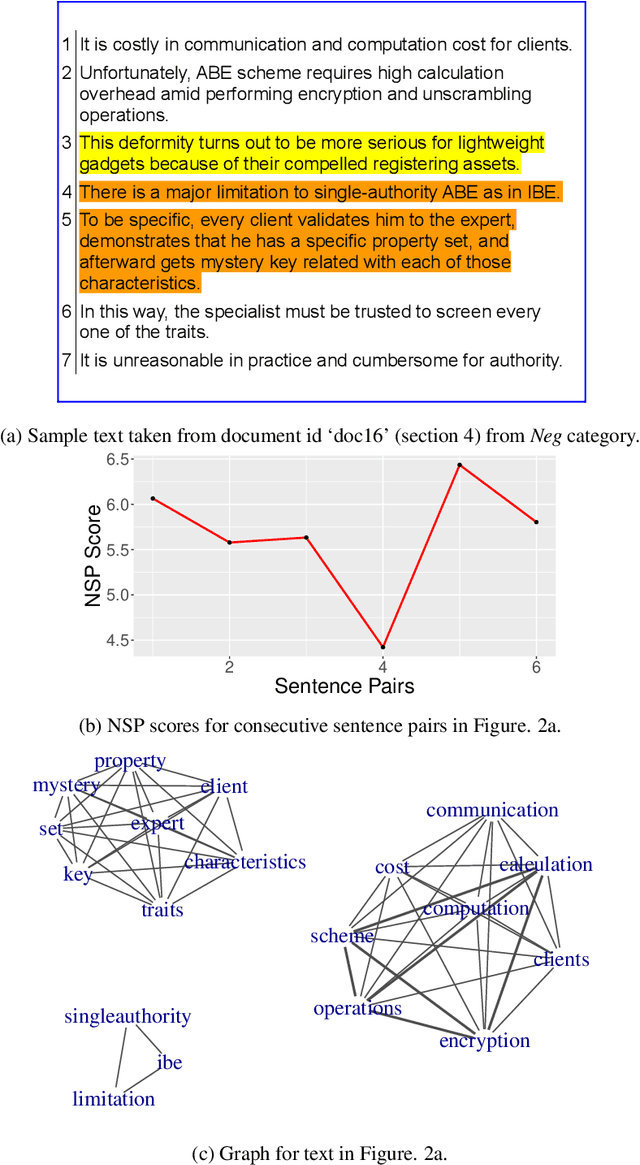
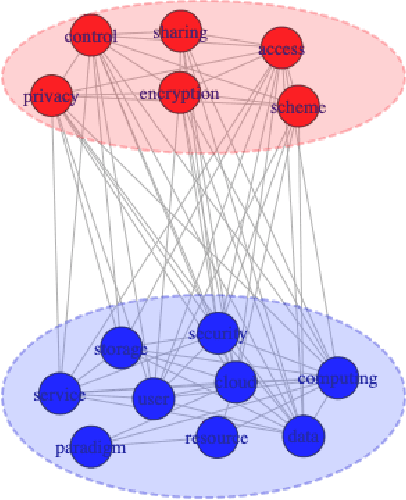

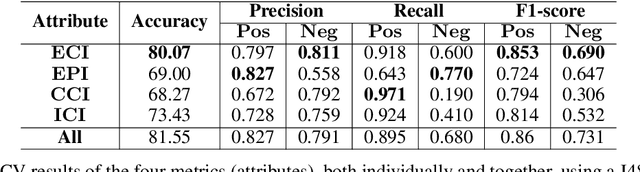
Discourse cohesion facilitates text comprehension and helps the reader form a coherent narrative. In this study, we aim to computationally analyze the discourse cohesion in scientific scholarly texts using multilayer network representation and quantify the writing quality of the document. Exploiting the hierarchical structure of scientific scholarly texts, we design section-level and document-level metrics to assess the extent of lexical cohesion in text. We use a publicly available dataset along with a curated set of contrasting examples to validate the proposed metrics by comparing them against select indices computed using existing cohesion analysis tools. We observe that the proposed metrics correlate as expected with the existing cohesion indices. We also present an analytical framework, CHIAA (CHeck It Again, Author), to provide pointers to the author for potential improvements in the manuscript with the help of the section-level and document-level metrics. The proposed CHIAA framework furnishes a clear and precise prescription to the author for improving writing by localizing regions in text with cohesion gaps. We demonstrate the efficacy of CHIAA framework using succinct examples from cohesion-deficient text excerpts in the experimental dataset.
Investigating Entropy for Extractive Document Summarization
Sep 30, 2021

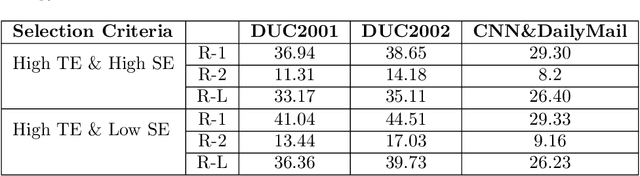
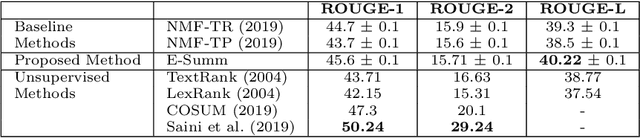
Automatic text summarization aims to cut down readers time and cognitive effort by reducing the content of a text document without compromising on its essence. Ergo, informativeness is the prime attribute of document summary generated by an algorithm, and selecting sentences that capture the essence of a document is the primary goal of extractive document summarization. In this paper, we employ Shannon entropy to capture informativeness of sentences. We employ Non-negative Matrix Factorization (NMF) to reveal probability distributions for computing entropy of terms, topics, and sentences in latent space. We present an information theoretic interpretation of the computed entropy, which is the bedrock of the proposed E-Summ algorithm, an unsupervised method for extractive document summarization. The algorithm systematically applies information theoretic principle for selecting informative sentences from important topics in the document. The proposed algorithm is generic and fast, and hence amenable to use for summarization of documents in real time. Furthermore, it is domain-, collection-independent and agnostic to the language of the document. Benefiting from strictly positive NMF factor matrices, E-Summ algorithm is transparent and explainable too. We use standard ROUGE toolkit for performance evaluation of the proposed method on four well known public data-sets. We also perform quantitative assessment of E-Summ summary quality by computing its semantic similarity w.r.t the original document. Our investigation reveals that though using NMF and information theoretic approach for document summarization promises efficient, explainable, and language independent text summarization, it needs to be bolstered to match the performance of deep neural methods.
Similar Cases Recommendation using Legal Knowledge Graphs
Jul 10, 2021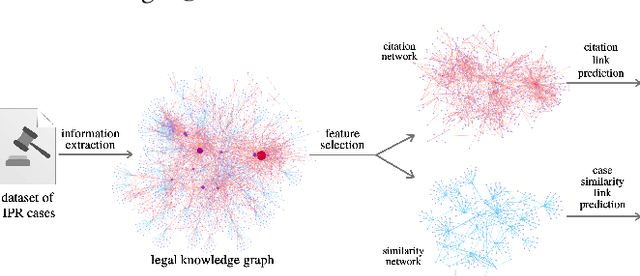

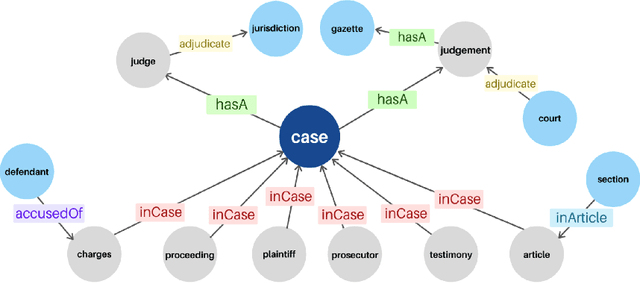
A legal knowledge graph constructed from court cases, judgments, laws and other legal documents can enable a number of applications like question answering, document similarity, and search. While the use of knowledge graphs for distant supervision in NLP tasks is well researched, using knowledge graphs for downstream graph tasks like node similarity presents challenges in selecting node types and their features. In this demo, we describe our solution for predicting similar nodes in a case graph derived from our legal knowledge graph.
Complex Network based Supervised Keyword Extractor
Sep 26, 2019
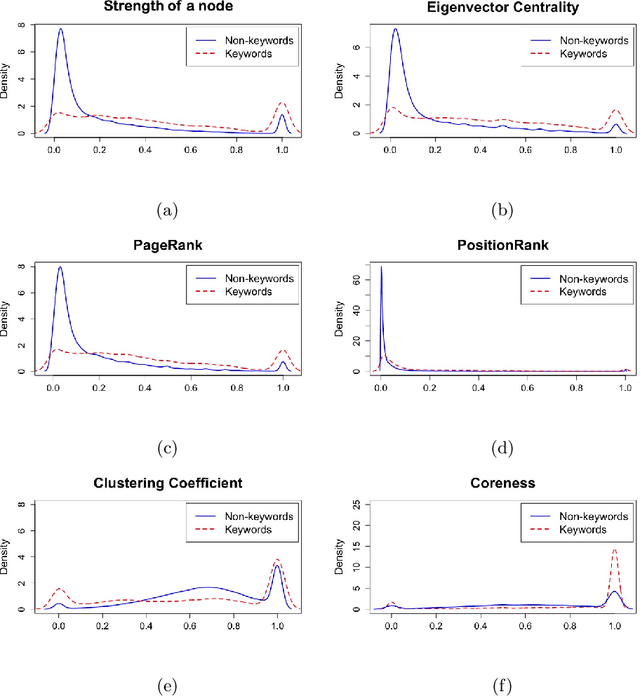
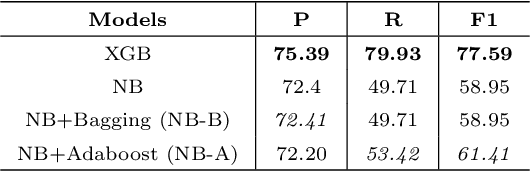
In this paper, we present a supervised framework for automatic keyword extraction from single document. We model the text as complex network, and construct the feature set by extracting select node properties from it. Several node properties have been exploited by unsupervised, graph-based keyword extraction methods to discriminate keywords from non-keywords. We exploit the complex interplay of node properties to design a supervised keyword extraction method. The training set is created from the feature set by assigning a label to each candidate keyword depending on whether the candidate is listed as a gold-standard keyword or not. Since the number of keywords in a document is much less than non-keywords, the curated training set is naturally imbalanced. We train a binary classifier to predict keywords after balancing the training set. The model is trained using two public datasets from scientific domain and tested using three unseen scientific corpora and one news corpus. Comparative study of the results with several recent keyword and keyphrase extraction methods establishes that the proposed method performs better in most cases. This substantiates our claim that graph-theoretic properties of words are effective discriminators between keywords and non-keywords. We support our argument by showing that the improved performance of the proposed method is statistically significant for all datasets. We also evaluate the effectiveness of the pre-trained model on Hindi and Assamese language documents. We observe that the model performs equally well for the cross-language text even though it was trained only on English language documents. This shows that the proposed method is independent of the domain, collection, and language of the training corpora.