 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Discourse Cohesion Analysis of Scientific Scholarly Texts using Multilayer Networks
May 16, 2022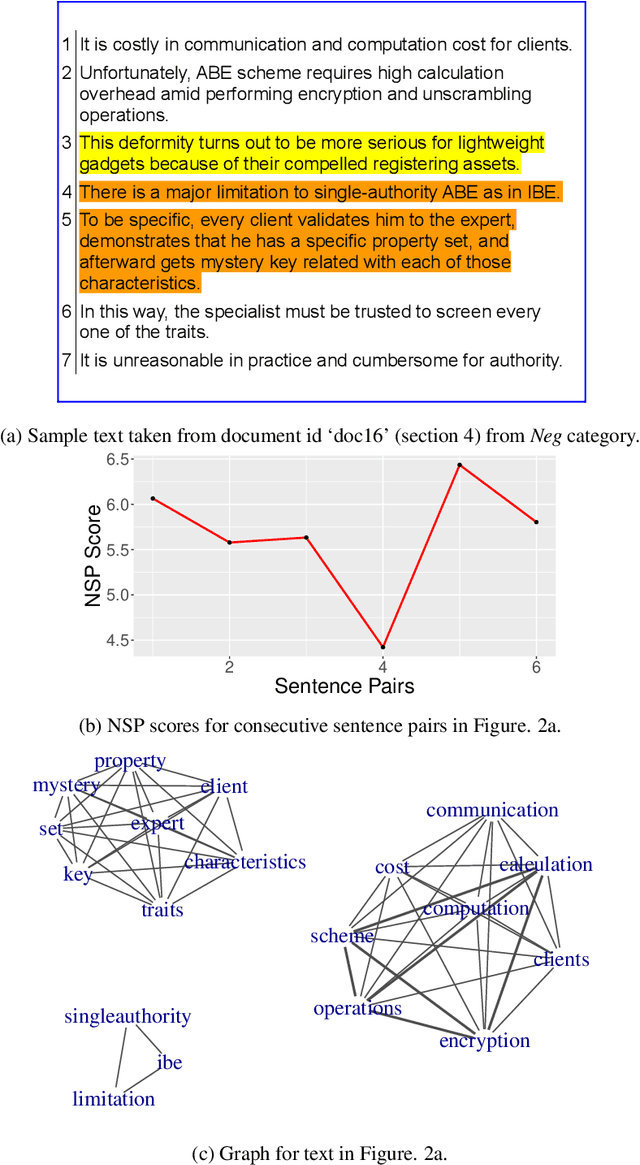
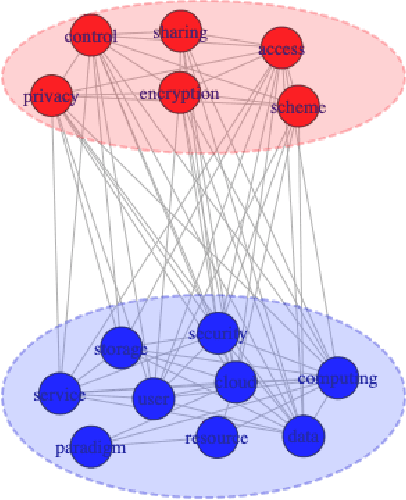

Discourse cohesion facilitates text comprehension and helps the reader form a coherent narrative. In this study, we aim to computationally analyze the discourse cohesion in scientific scholarly texts using multilayer network representation and quantify the writing quality of the document. Exploiting the hierarchical structure of scientific scholarly texts, we design section-level and document-level metrics to assess the extent of lexical cohesion in text. We use a publicly available dataset along with a curated set of contrasting examples to validate the proposed metrics by comparing them against select indices computed using existing cohesion analysis tools. We observe that the proposed metrics correlate as expected with the existing cohesion indices. We also present an analytical framework, CHIAA (CHeck It Again, Author), to provide pointers to the author for potential improvements in the manuscript with the help of the section-level and document-level metrics. The proposed CHIAA framework furnishes a clear and precise prescription to the author for improving writing by localizing regions in text with cohesion gaps. We demonstrate the efficacy of CHIAA framework using succinct examples from cohesion-deficient text excerpts in the experimental dataset.
Complex Network based Supervised Keyword Extractor
Sep 26, 2019
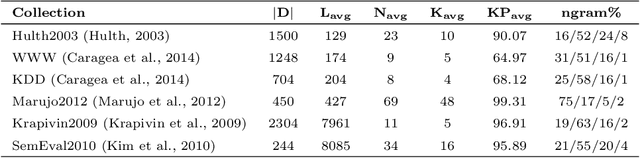
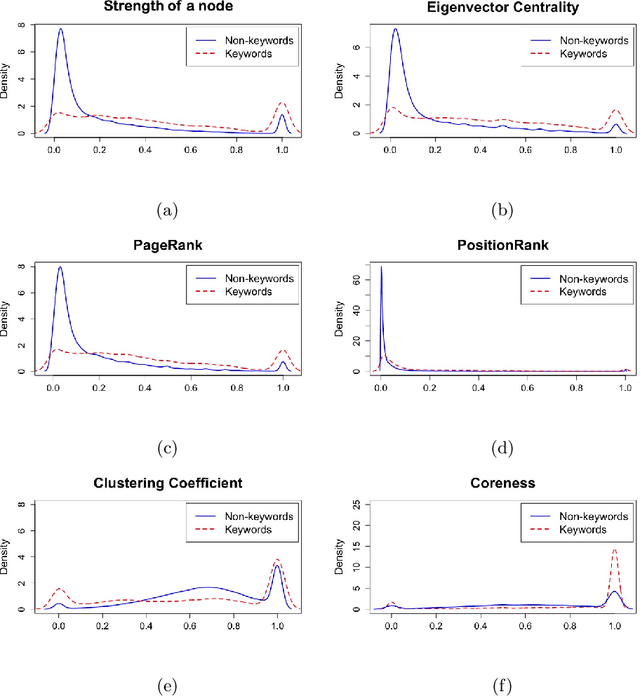
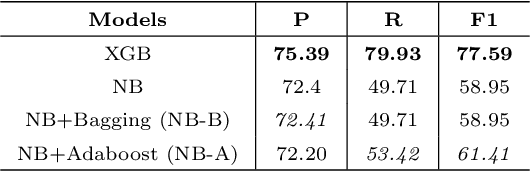
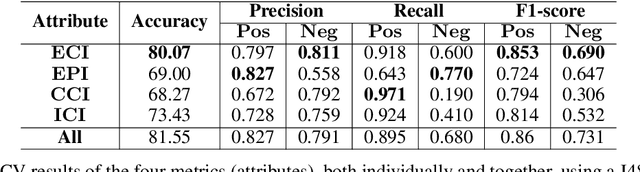
In this paper, we present a supervised framework for automatic keyword extraction from single document. We model the text as complex network, and construct the feature set by extracting select node properties from it. Several node properties have been exploited by unsupervised, graph-based keyword extraction methods to discriminate keywords from non-keywords. We exploit the complex interplay of node properties to design a supervised keyword extraction method. The training set is created from the feature set by assigning a label to each candidate keyword depending on whether the candidate is listed as a gold-standard keyword or not. Since the number of keywords in a document is much less than non-keywords, the curated training set is naturally imbalanced. We train a binary classifier to predict keywords after balancing the training set. The model is trained using two public datasets from scientific domain and tested using three unseen scientific corpora and one news corpus. Comparative study of the results with several recent keyword and keyphrase extraction methods establishes that the proposed method performs better in most cases. This substantiates our claim that graph-theoretic properties of words are effective discriminators between keywords and non-keywords. We support our argument by showing that the improved performance of the proposed method is statistically significant for all datasets. We also evaluate the effectiveness of the pre-trained model on Hindi and Assamese language documents. We observe that the model performs equally well for the cross-language text even though it was trained only on English language documents. This shows that the proposed method is independent of the domain, collection, and language of the training corpora.
Semi-automatic System for Title Construction
May 01, 2019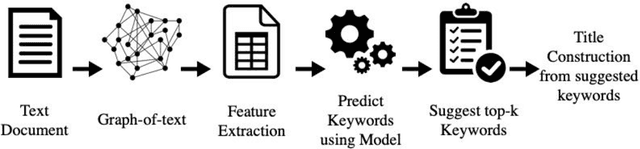
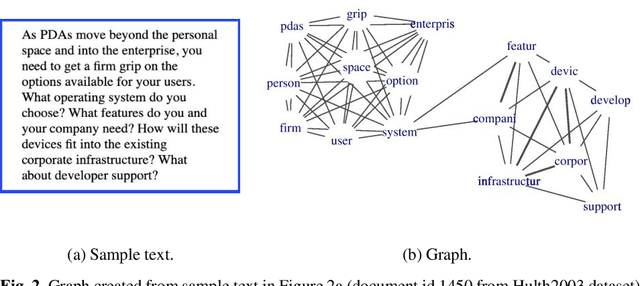
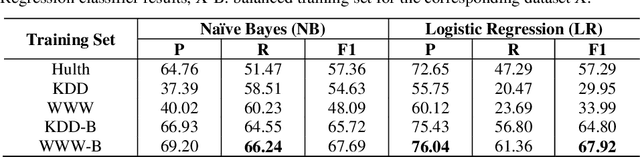
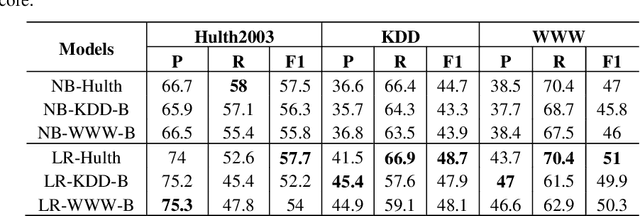
In this paper, we propose a semi-automatic system for title construction from scientific abstracts. The system extracts and recommends impactful words from the text, which the author can creatively use to construct an appropriate title for the manuscript. The work is based on the hypothesis that keywords are good candidates for title construction. We extract important words from the document by inducing a supervised keyword extraction model. The model is trained on novel features extracted from graph-of-text representation of the document. We empirically show that these graph-based features are capable of discriminating keywords from non-keywords. We further establish empirically that the proposed approach can be applied to any text irrespective of the training domain and corpus. We evaluate the proposed system by computing the overlap between extracted keywords and the list of title-words for documents, and we observe a macro-averaged precision of 82%.