 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Network based Supervised Keyword Extractor
Paper and Code

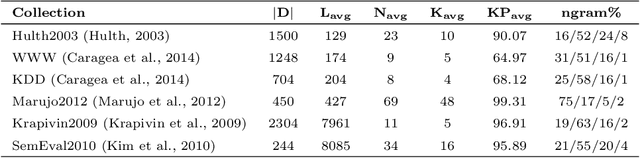
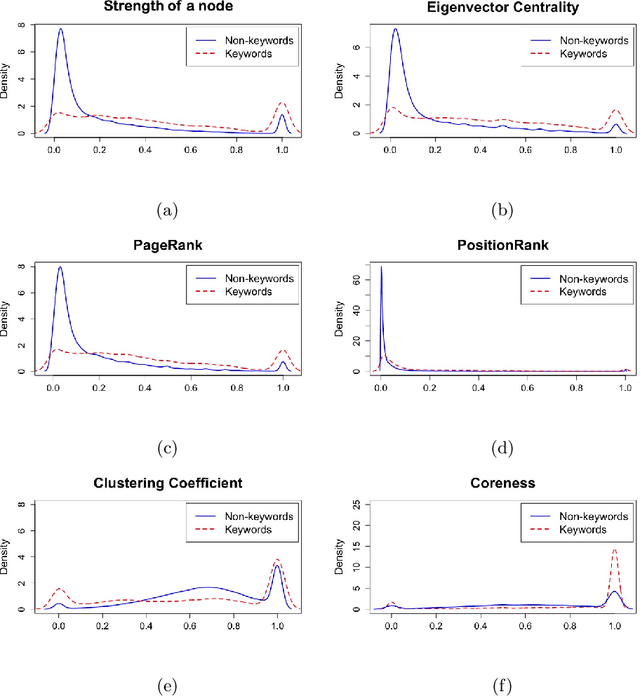
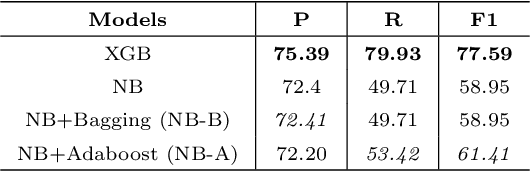
In this paper, we present a supervised framework for automatic keyword extraction from single document. We model the text as complex network, and construct the feature set by extracting select node properties from it. Several node properties have been exploited by unsupervised, graph-based keyword extraction methods to discriminate keywords from non-keywords. We exploit the complex interplay of node properties to design a supervised keyword extraction method. The training set is created from the feature set by assigning a label to each candidate keyword depending on whether the candidate is listed as a gold-standard keyword or not. Since the number of keywords in a document is much less than non-keywords, the curated training set is naturally imbalanced. We train a binary classifier to predict keywords after balancing the training set. The model is trained using two public datasets from scientific domain and tested using three unseen scientific corpora and one news corpus. Comparative study of the results with several recent keyword and keyphrase extraction methods establishes that the proposed method performs better in most cases. This substantiates our claim that graph-theoretic properties of words are effective discriminators between keywords and non-keywords. We support our argument by showing that the improved performance of the proposed method is statistically significant for all datasets. We also evaluate the effectiveness of the pre-trained model on Hindi and Assamese language documents. We observe that the model performs equally well for the cross-language text even though it was trained only on English language documents. This shows that the proposed method is independent of the domain, collection, and language of the training corpora.