 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-automatic System for Title Construction
Paper and Code
May 01, 2019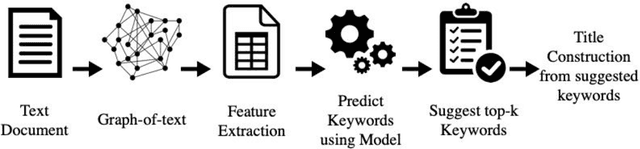
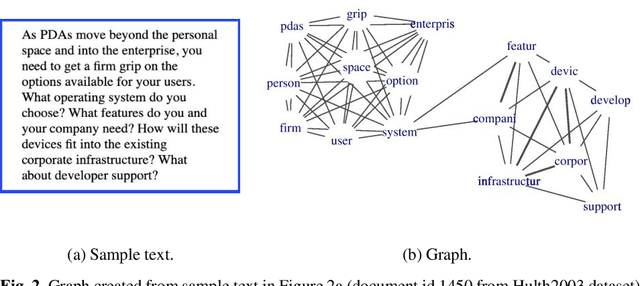
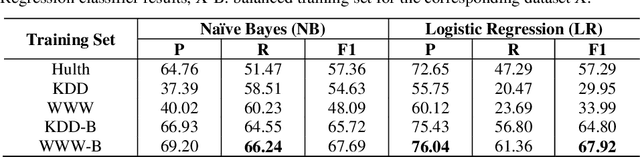
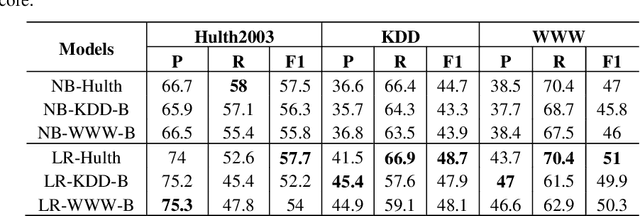
In this paper, we propose a semi-automatic system for title construction from scientific abstracts. The system extracts and recommends impactful words from the text, which the author can creatively use to construct an appropriate title for the manuscript. The work is based on the hypothesis that keywords are good candidates for title construction. We extract important words from the document by inducing a supervised keyword extraction model. The model is trained on novel features extracted from graph-of-text representation of the document. We empirically show that these graph-based features are capable of discriminating keywords from non-keywords. We further establish empirically that the proposed approach can be applied to any text irrespective of the training domain and corpus. We evaluate the proposed system by computing the overlap between extracted keywords and the list of title-words for documents, and we observe a macro-averaged precision of 82%.