 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Centered AI for Indian Legal Text Analytics
Paper and Code
Mar 16, 2024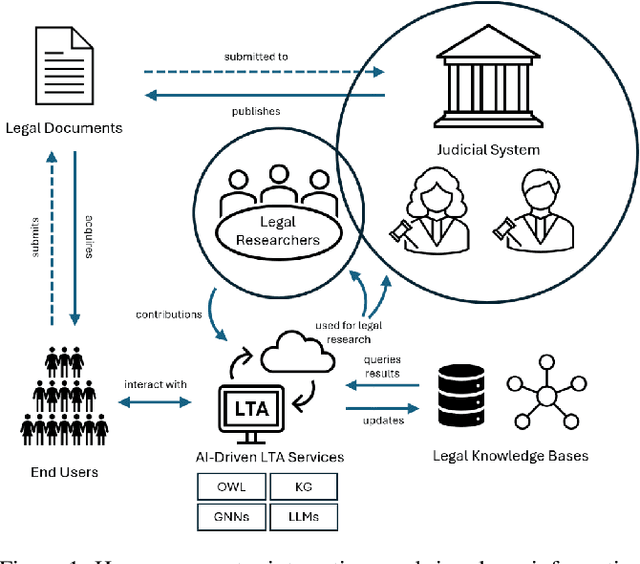
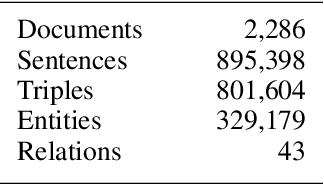


Legal research is a crucial task in the practice of law. It requires intense human effort and intellectual prudence to research a legal case and prepare arguments. Recent boom in generative AI has not translated to proportionate rise in impactful legal applications, because of low trustworthiness and and the scarcity of specialized datasets for training Large Language Models (LLMs). This position paper explores the potential of LLMs within Legal Text Analytics (LTA), highlighting specific areas where the integration of human expertise can significantly enhance their performance to match that of experts. We introduce a novel dataset and describe a human centered, compound AI system that principally incorporates human inputs for performing LTA tasks with LLMs.