 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Want This, Not That: Personalized Summarization of Scientific Scholarly Texts
Jun 16, 2023



In this paper, we present a proposal for an unsupervised algorithm, P-Summ, that generates an extractive summary of scientific scholarly text to meet the personal knowledge needs of the user. The method delves into the latent semantic space of the document exposed by Weighted Non-negative Matrix Factorization, and scores sentences in consonance with the knowledge needs of the user. The novelty of the algorithm lies in its ability to include desired knowledge and eliminate unwanted knowledge in the personal summary. We also propose a multi-granular evaluation framework, which assesses the quality of generated personal summaries at three levels of granularity - sentence, terms and semantic. The framework uses system generated generic summary instead of human generated summary as gold standard for evaluating the quality of personal summary generated by the algorithm. The effectiveness of the algorithm at the semantic level is evaluated by taking into account the reference summary and the knowledge signals. We evaluate the performance of P-Summ algorithm over four data-sets consisting of scientific articles. Our empirical investigations reveal that the proposed method has the capability to meet negative (or positive) knowledge preferences of the user.
Investigating Entropy for Extractive Document Summarization
Sep 30, 2021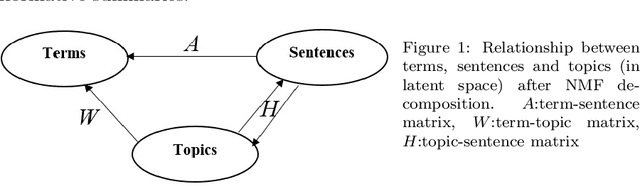

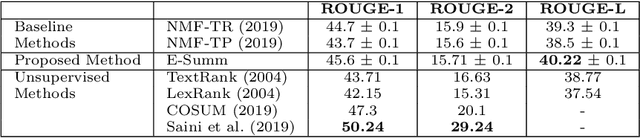
Automatic text summarization aims to cut down readers time and cognitive effort by reducing the content of a text document without compromising on its essence. Ergo, informativeness is the prime attribute of document summary generated by an algorithm, and selecting sentences that capture the essence of a document is the primary goal of extractive document summarization. In this paper, we employ Shannon entropy to capture informativeness of sentences. We employ Non-negative Matrix Factorization (NMF) to reveal probability distributions for computing entropy of terms, topics, and sentences in latent space. We present an information theoretic interpretation of the computed entropy, which is the bedrock of the proposed E-Summ algorithm, an unsupervised method for extractive document summarization. The algorithm systematically applies information theoretic principle for selecting informative sentences from important topics in the document. The proposed algorithm is generic and fast, and hence amenable to use for summarization of documents in real time. Furthermore, it is domain-, collection-independent and agnostic to the language of the document. Benefiting from strictly positive NMF factor matrices, E-Summ algorithm is transparent and explainable too. We use standard ROUGE toolkit for performance evaluation of the proposed method on four well known public data-sets. We also perform quantitative assessment of E-Summ summary quality by computing its semantic similarity w.r.t the original document. Our investigation reveals that though using NMF and information theoretic approach for document summarization promises efficient, explainable, and language independent text summarization, it needs to be bolstered to match the performance of deep neural methods.