 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReservoir of Diverse Adaptive Learners and Stacking Fast Hoeffding Drift Detection Methods for Evolving Data Streams
Paper and Code
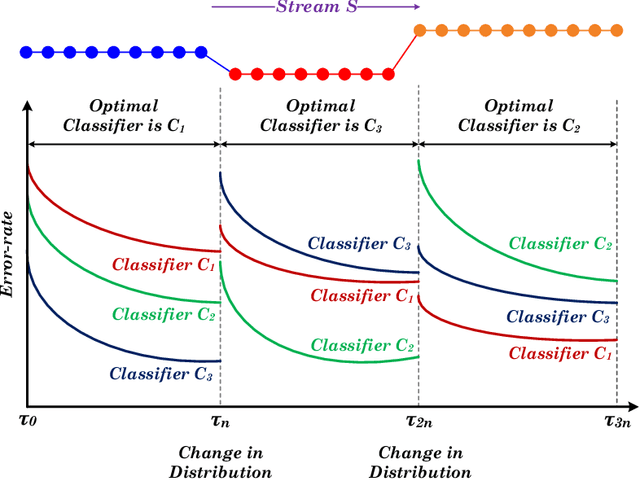
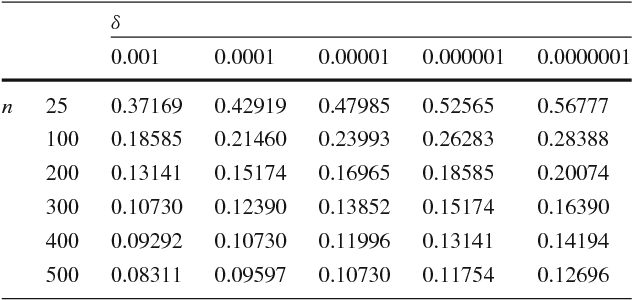
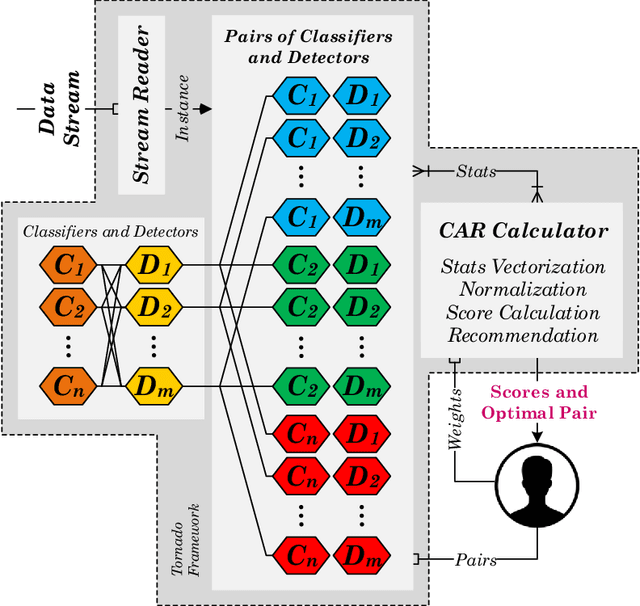
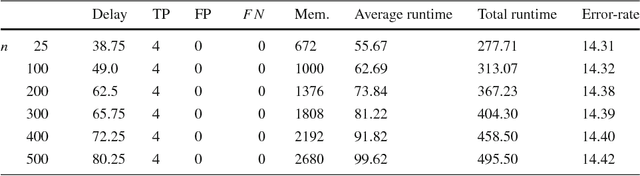
The last decade has seen a surge of interest in adaptive learning algorithms for data stream classification, with applications ranging from predicting ozone level peaks, learning stock market indicators, to detecting computer security violations. In addition, a number of methods have been developed to detect concept drifts in these streams. Consider a scenario where we have a number of classifiers with diverse learning styles and different drift detectors. Intuitively, the current 'best' (classifier, detector) pair is application dependent and may change as a result of the stream evolution. Our research builds on this observation. We introduce the $\mbox{Tornado}$ framework that implements a reservoir of diverse classifiers, together with a variety of drift detection algorithms. In our framework, all (classifier, detector) pairs proceed, in parallel, to construct models against the evolving data streams. At any point in time, we select the pair which currently yields the best performance. We further incorporate two novel stacking-based drift detection methods, namely the $\mbox{FHDDMS}$ and $\mbox{FHDDMS}_{add}$ approaches. The experimental evaluation confirms that the current 'best' (classifier, detector) pair is not only heavily dependent on the characteristics of the stream, but also that this selection evolves as the stream flows. Further, our $\mbox{FHDDMS}$ variants detect concept drifts accurately in a timely fashion while outperforming the state-of-the-art.