 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Ethical Content-Based Detection of Online Influence Campaigns
Paper and Code
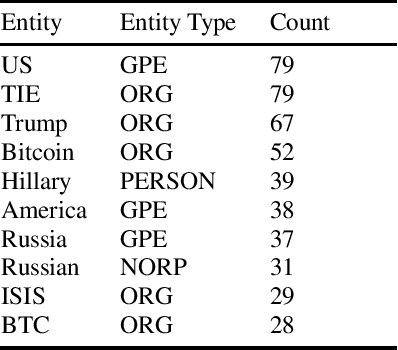


The detection of clandestine efforts to influence users in online communities is a challenging problem with significant active development. We demonstrate that features derived from the text of user comments are useful for identifying suspect activity, but lead to increased erroneous identifications when keywords over-represented in past influence campaigns are present. Drawing on research in native language identification (NLI), we use "named entity masking" (NEM) to create sentence features robust to this shortcoming, while maintaining comparable classification accuracy. We demonstrate that while NEM consistently reduces false positives when key named entities are mentioned, both masked and unmasked models exhibit increased false positive rates on English sentences by Russian native speakers, raising ethical considerations that should be addressed in future research.