 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Trust Your Data: Enhancing Dyna-Style Model-Based Reinforcement Learning With Data Filter
Paper and Code
Oct 16, 2024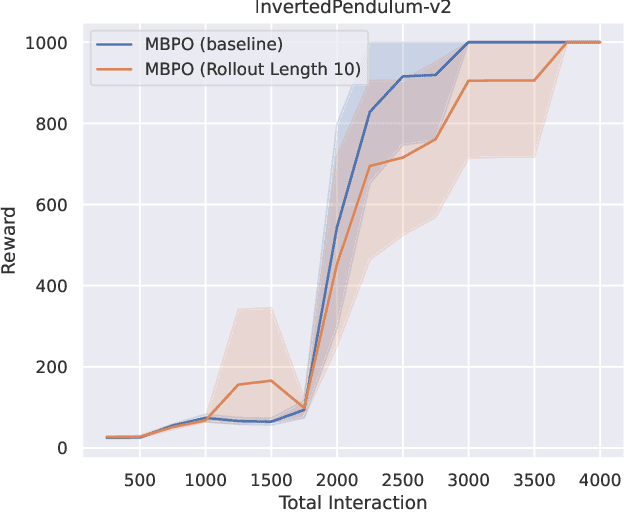

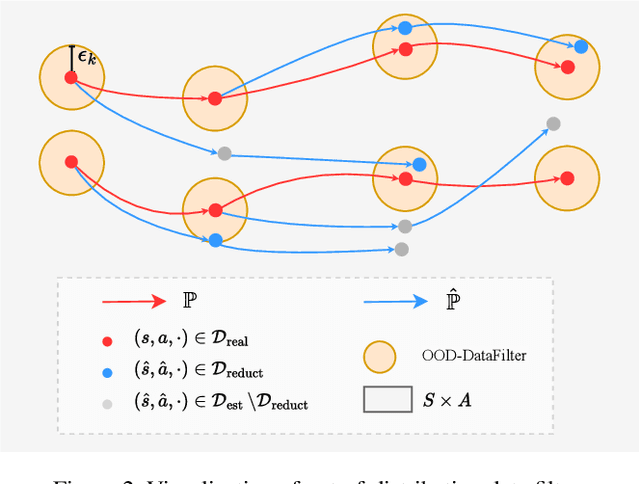
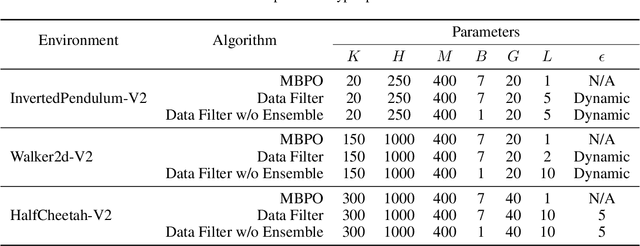
Reinforcement learning (RL) algorithms can be divided into two classes: model-free algorithms, which are sample-inefficient, and model-based algorithms, which suffer from model bias. Dyna-style algorithms combine these two approaches by using simulated data from an estimated environmental model to accelerate model-free training. However, their efficiency is compromised when the estimated model is inaccurate. Previous works address this issue by using model ensembles or pretraining the estimated model with data collected from the real environment, increasing computational and sample complexity. To tackle this issue, we introduce an out-of-distribution (OOD) data filter that removes simulated data from the estimated model that significantly diverges from data collected in the real environment. We show theoretically that this technique enhances the quality of simulated data. With the help of the OOD data filter, the data simulated from the estimated model better mimics the data collected by interacting with the real model. This improvement is evident in the critic updates compared to using the simulated data without the OOD data filter. Our experiment integrates the data filter into the model-based policy optimization (MBPO) algorithm. The results demonstrate that our method requires fewer interactions with the real environment to achieve a higher level of optimality than MBPO, even without a model ensemble.