 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Transformer to 1M tokens and beyond with RMT
Apr 19, 2023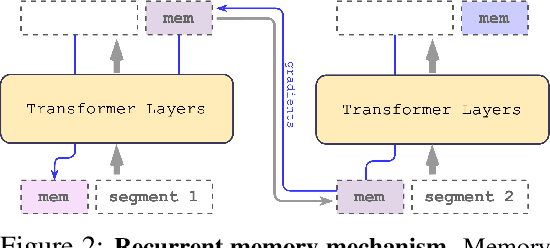
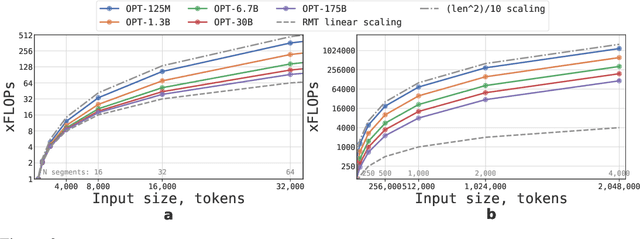
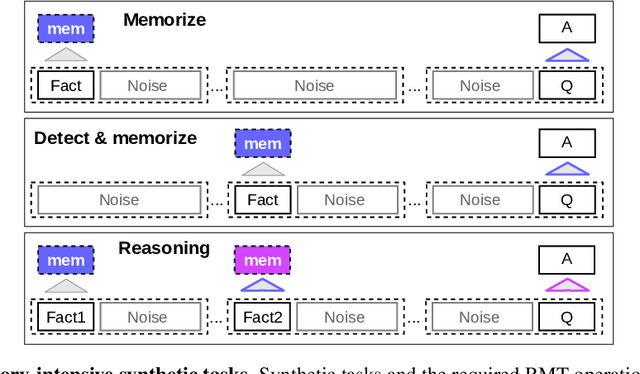
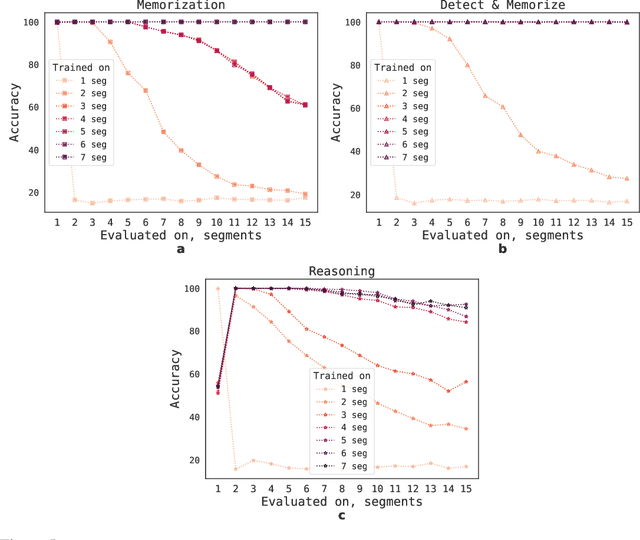
This technical report presents the application of a recurrent memory to extend the context length of BERT, one of the most effective Transformer-based models in natural language processing. By leveraging the Recurrent Memory Transformer architecture, we have successfully increased the model's effective context length to an unprecedented two million tokens, while maintaining high memory retrieval accuracy. Our method allows for the storage and processing of both local and global information and enables information flow between segments of the input sequence through the use of recurrence. Our experiments demonstrate the effectiveness of our approach, which holds significant potential to enhance long-term dependency handling in natural language understanding and generation tasks as well as enable large-scale context processing for memory-intensive applications.
Recurrent Memory Transformer
Jul 14, 2022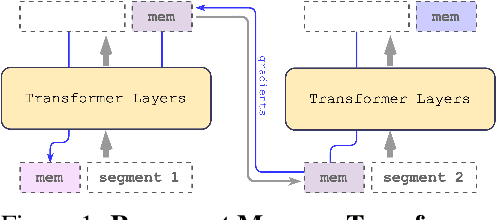

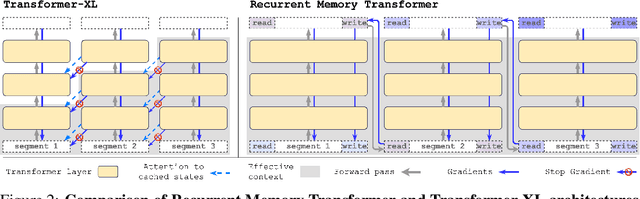
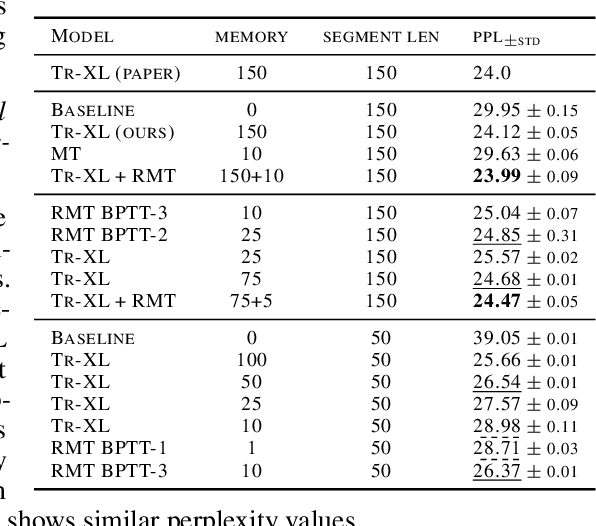
Transformer-based models show their effectiveness across multiple domains and tasks. The self-attention allows to combine information from all sequence elements into context-aware representations. However, global and local information has to be stored mostly in the same element-wise representations. Moreover, the length of an input sequence is limited by quadratic computational complexity of self-attention. In this work, we propose and study a memory-augmented segment-level recurrent Transformer (Recurrent Memory Transformer). Memory allows to store and process local and global information as well as to pass information between segments of the long sequence with the help of recurrence. We implement a memory mechanism with no changes to Transformer model by adding special memory tokens to the input or output sequence. Then Transformer is trained to control both memory operations and sequence representations processing. Results of experiments show that our model performs on par with the Transformer-XL on language modeling for smaller memory sizes and outperforms it for tasks that require longer sequence processing. We show that adding memory tokens to Tr-XL is able to improve it performance. This makes Recurrent Memory Transformer a promising architecture for applications that require learning of long-term dependencies and general purpose in memory processing, such as algorithmic tasks and reasoning.
Memory Transformer
Jun 20, 2020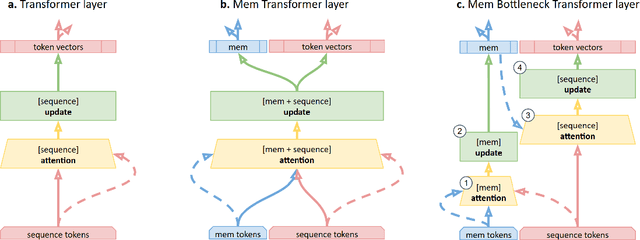
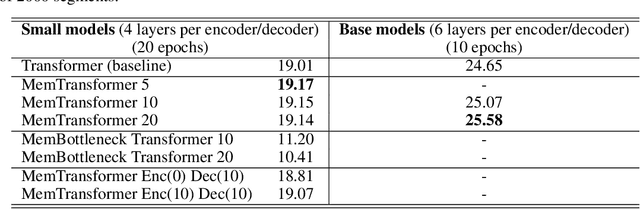

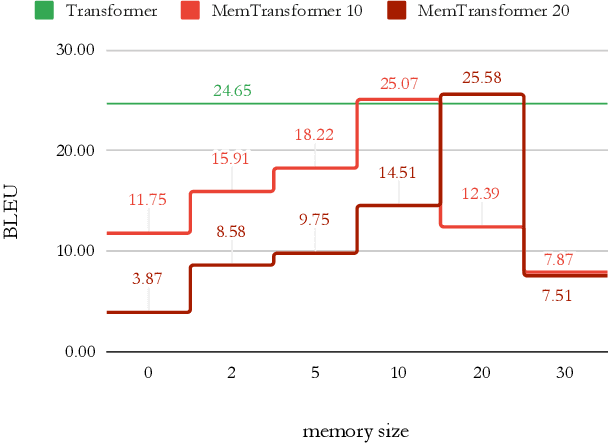
Transformer-based models have achieved state-of-the-art results in many natural language processing (NLP) tasks. The self-attention architecture allows us to combine information from all elements of a sequence into context-aware representations. However, all-to-all attention severely hurts the scaling of the model to large sequences. Another limitation is that information about the context is stored in the same element-wise representations. This makes the processing of properties related to the sequence as a whole more difficult. Adding trainable memory to selectively store local as well as global representations of a sequence is a promising direction to improve the Transformer model. Memory-augmented neural networks (MANNs) extend traditional neural architectures with general-purpose memory for representations. MANNs have demonstrated the capability to learn simple algorithms like Copy or Reverse and can be successfully trained via backpropagation on diverse tasks from question answering to language modeling outperforming RNNs and LSTMs of comparable complexity. In this work, we propose and study two extensions of the Transformer baseline (1) by adding memory tokens to store non-local representations, and (2) creating memory bottleneck for the global information. We evaluate these memory augmented Transformers on machine translation task and demonstrate that memory size positively correlates with the model performance. Attention patterns over the memory suggest that it improves the model's ability to process a global context. We expect that the application of Memory Transformer architectures to the tasks of language modeling, reading comprehension, and text summarization, as well as other NLP tasks that require the processing of long contexts will contribute to solving challenging problems of natural language understanding and generation.
Continual and Multi-task Reinforcement Learning With Shared Episodic Memory
May 07, 2019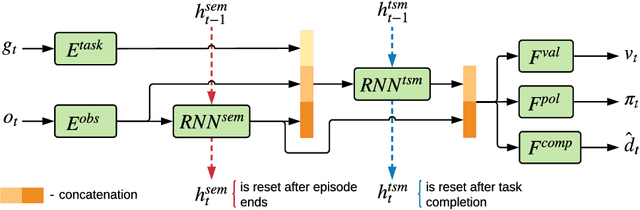


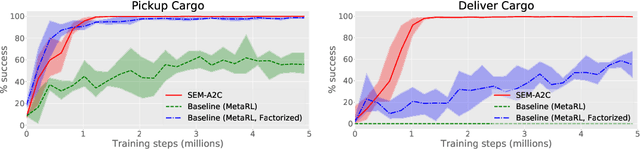
Episodic memory plays an important role in the behavior of animals and humans. It allows the accumulation of information about current state of the environment in a task-agnostic way. This episodic representation can be later accessed by down-stream tasks in order to make their execution more efficient. In this work, we introduce the neural architecture with shared episodic memory (SEM) for learning and the sequential execution of multiple tasks. We explicitly split the encoding of episodic memory and task-specific memory into separate recurrent sub-networks. An agent augmented with SEM was able to effectively reuse episodic knowledge collected during other tasks to improve its policy on a current task in the Taxi problem. Repeated use of episodic representation in continual learning experiments facilitated acquisition of novel skills in the same environment.
Alife Model of Evolutionary Emergence of Purposeful Adaptive Behavior
Oct 08, 2001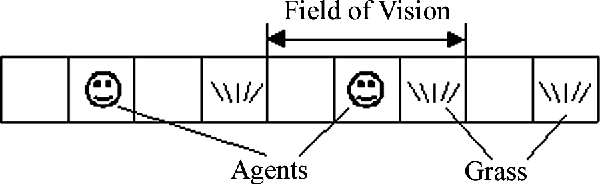
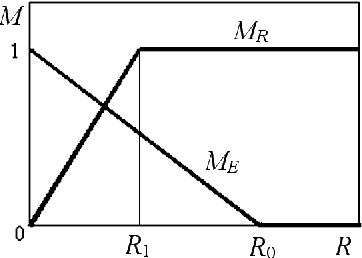
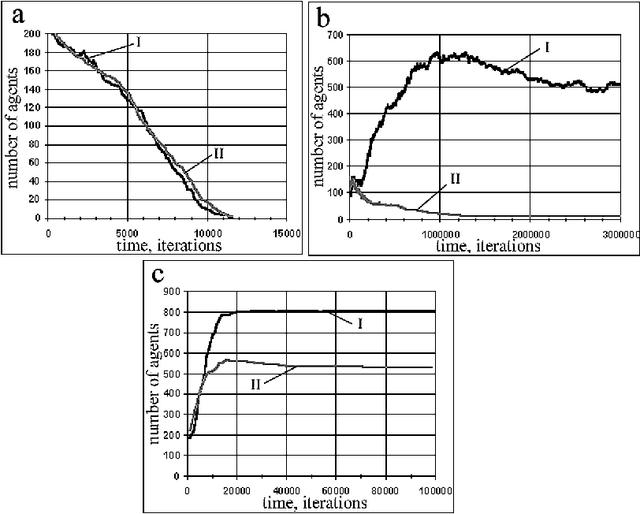
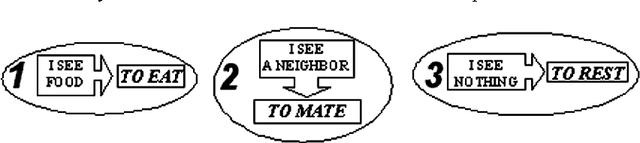
The process of evolutionary emergence of purposeful adaptive behavior is investigated by means of computer simulations. The model proposed implies that there is an evolving population of simple agents, which have two natural needs: energy and reproduction. Any need is characterized quantitatively by a corresponding motivation. Motivations determine goal-directed behavior of agents. The model demonstrates that purposeful behavior does emerge in the simulated evolutionary processes. Emergence of purposefulness is accompanied by origin of a simple hierarchy in the control system of agents.