 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
The Russian-focused embedders' exploration: ruMTEB benchmark and Russian embedding model design
Aug 22, 2024Embedding models play a crucial role in Natural Language Processing (NLP) by creating text embeddings used in various tasks such as information retrieval and assessing semantic text similarity. This paper focuses on research related to embedding models in the Russian language. It introduces a new Russian-focused embedding model called ru-en-RoSBERTa and the ruMTEB benchmark, the Russian version extending the Massive Text Embedding Benchmark (MTEB). Our benchmark includes seven categories of tasks, such as semantic textual similarity, text classification, reranking, and retrieval. The research also assesses a representative set of Russian and multilingual models on the proposed benchmark. The findings indicate that the new model achieves results that are on par with state-of-the-art models in Russian. We release the model ru-en-RoSBERTa, and the ruMTEB framework comes with open-source code, integration into the original framework and a public leaderboard.
A Family of Pretrained Transformer Language Models for Russian
Sep 19, 2023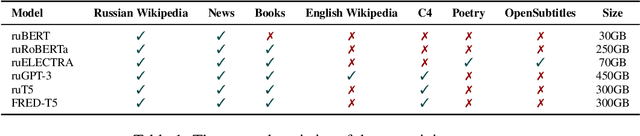
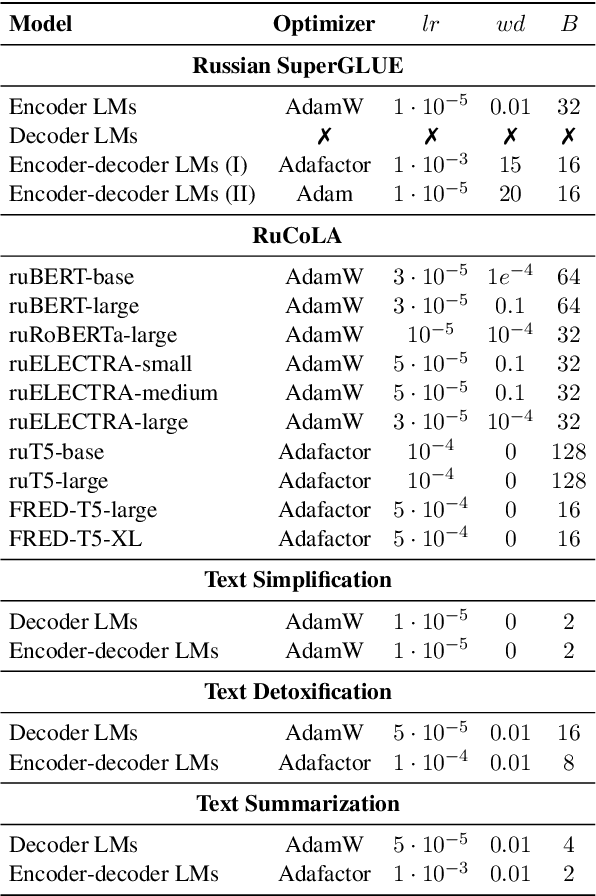
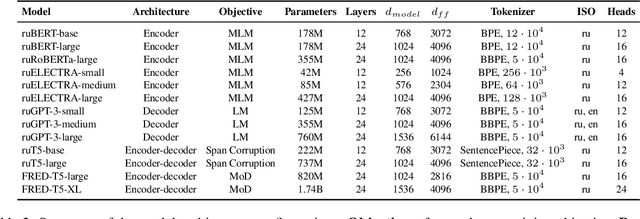
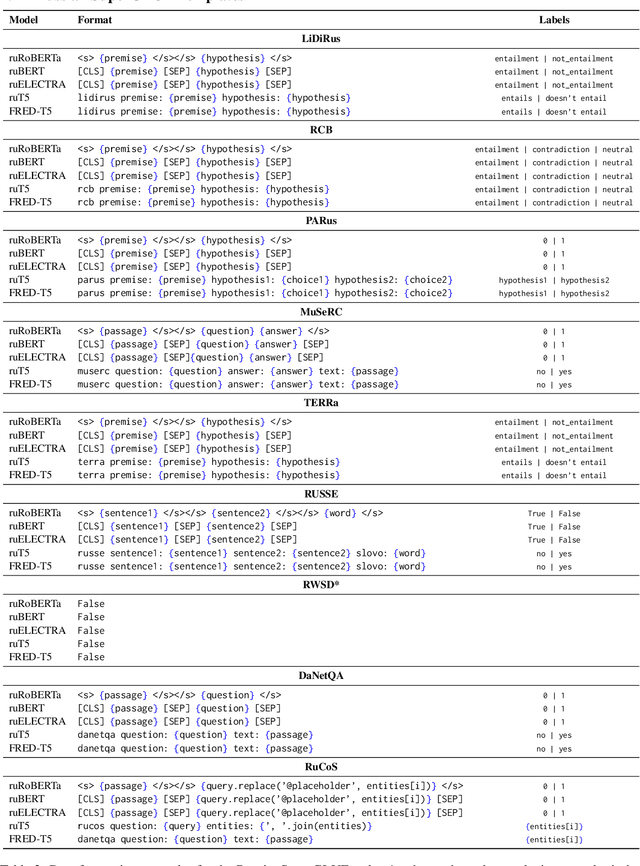
Nowadays, Transformer language models (LMs) represent a fundamental component of the NLP research methodologies and applications. However, the development of such models specifically for the Russian language has received little attention. This paper presents a collection of 13 Russian Transformer LMs based on the encoder (ruBERT, ruRoBERTa, ruELECTRA), decoder (ruGPT-3), and encoder-decoder (ruT5, FRED-T5) models in multiple sizes. Access to these models is readily available via the HuggingFace platform. We provide a report of the model architecture design and pretraining, and the results of evaluating their generalization abilities on Russian natural language understanding and generation datasets and benchmarks. By pretraining and releasing these specialized Transformer LMs, we hope to broaden the scope of the NLP research directions and enable the development of industrial solutions for the Russian language.