 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuBLiMP: Russian Benchmark of Linguistic Minimal Pairs
Jun 27, 2024Minimal pairs are a well-established approach to evaluating the grammatical knowledge of language models. However, existing resources for minimal pairs address a limited number of languages and lack diversity of language-specific grammatical phenomena. This paper introduces the Russian Benchmark of Linguistic Minimal Pairs (RuBLiMP), which includes 45k pairs of sentences that differ in grammaticality and isolate a morphological, syntactic, or semantic phenomenon. In contrast to existing benchmarks of linguistic minimal pairs, RuBLiMP is created by applying linguistic perturbations to automatically annotated sentences from open text corpora and carefully curating test data. We describe the data collection protocol and present the results of evaluating 25 language models in various scenarios. We find that the widely used language models for Russian are sensitive to morphological and agreement-oriented contrasts but fall behind humans on phenomena requiring understanding of structural relations, negation, transitivity, and tense. RuBLiMP, the codebase, and other materials are publicly available.
LUNA: A Framework for Language Understanding and Naturalness Assessment
Jan 09, 2024
The evaluation of Natural Language Generation (NLG) models has gained increased attention, urging the development of metrics that evaluate various aspects of generated text. LUNA addresses this challenge by introducing a unified interface for 20 NLG evaluation metrics. These metrics are categorized based on their reference-dependence and the type of text representation they employ, from string-based n-gram overlap to the utilization of static embeddings and pre-trained language models. The straightforward design of LUNA allows for easy extension with novel metrics, requiring just a few lines of code. LUNA offers a user-friendly tool for evaluating generated texts.
A Family of Pretrained Transformer Language Models for Russian
Sep 19, 2023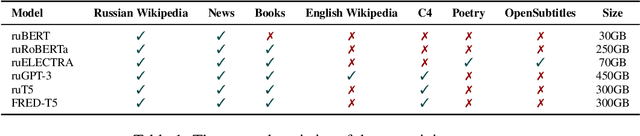
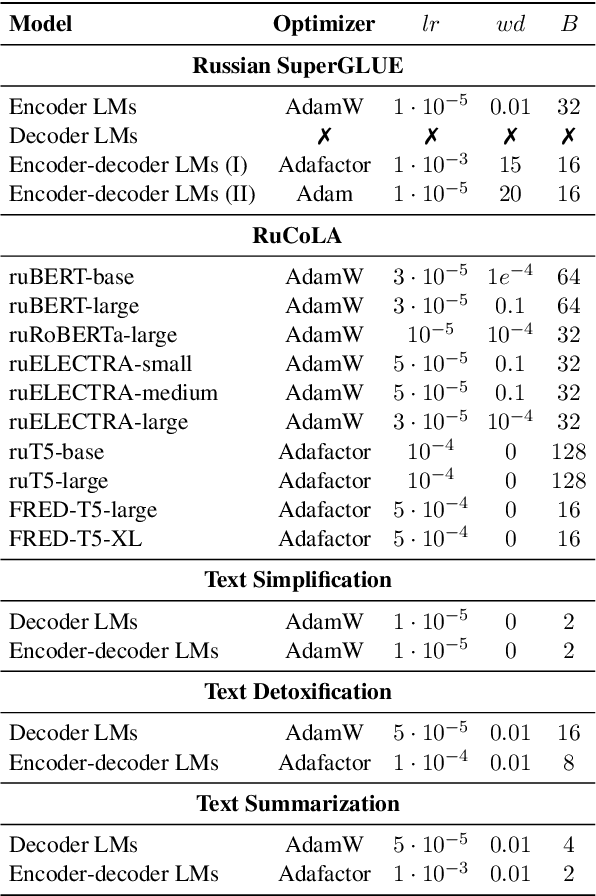
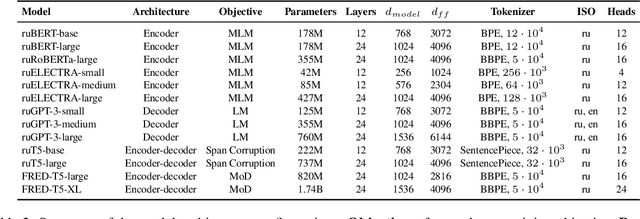
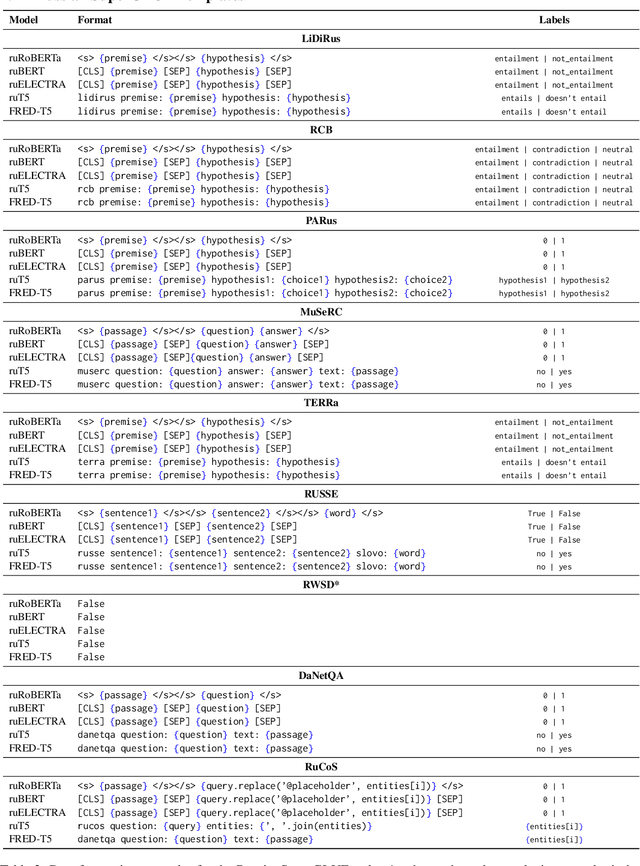
Nowadays, Transformer language models (LMs) represent a fundamental component of the NLP research methodologies and applications. However, the development of such models specifically for the Russian language has received little attention. This paper presents a collection of 13 Russian Transformer LMs based on the encoder (ruBERT, ruRoBERTa, ruELECTRA), decoder (ruGPT-3), and encoder-decoder (ruT5, FRED-T5) models in multiple sizes. Access to these models is readily available via the HuggingFace platform. We provide a report of the model architecture design and pretraining, and the results of evaluating their generalization abilities on Russian natural language understanding and generation datasets and benchmarks. By pretraining and releasing these specialized Transformer LMs, we hope to broaden the scope of the NLP research directions and enable the development of industrial solutions for the Russian language.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
TAPE: Assessing Few-shot Russian Language Understanding
Oct 23, 2022Recent advances in zero-shot and few-shot learning have shown promise for a scope of research and practical purposes. However, this fast-growing area lacks standardized evaluation suites for non-English languages, hindering progress outside the Anglo-centric paradigm. To address this line of research, we propose TAPE (Text Attack and Perturbation Evaluation), a novel benchmark that includes six more complex NLU tasks for Russian, covering multi-hop reasoning, ethical concepts, logic and commonsense knowledge. The TAPE's design focuses on systematic zero-shot and few-shot NLU evaluation: (i) linguistic-oriented adversarial attacks and perturbations for analyzing robustness, and (ii) subpopulations for nuanced interpretation. The detailed analysis of testing the autoregressive baselines indicates that simple spelling-based perturbations affect the performance the most, while paraphrasing the input has a more negligible effect. At the same time, the results demonstrate a significant gap between the neural and human baselines for most tasks. We publicly release TAPE (tape-benchmark.com) to foster research on robust LMs that can generalize to new tasks when little to no supervision is available.
Shaking Syntactic Trees on the Sesame Street: Multilingual Probing with Controllable Perturbations
Sep 28, 2021



Recent research has adopted a new experimental field centered around the concept of text perturbations which has revealed that shuffled word order has little to no impact on the downstream performance of Transformer-based language models across many NLP tasks. These findings contradict the common understanding of how the models encode hierarchical and structural information and even question if the word order is modeled with position embeddings. To this end, this paper proposes nine probing datasets organized by the type of \emph{controllable} text perturbation for three Indo-European languages with a varying degree of word order flexibility: English, Swedish and Russian. Based on the probing analysis of the M-BERT and M-BART models, we report that the syntactic sensitivity depends on the language and model pre-training objectives. We also find that the sensitivity grows across layers together with the increase of the perturbation granularity. Last but not least, we show that the models barely use the positional information to induce syntactic trees from their intermediate self-attention and contextualized representations.
RuSentEval: Linguistic Source, Encoder Force!
Mar 02, 2021
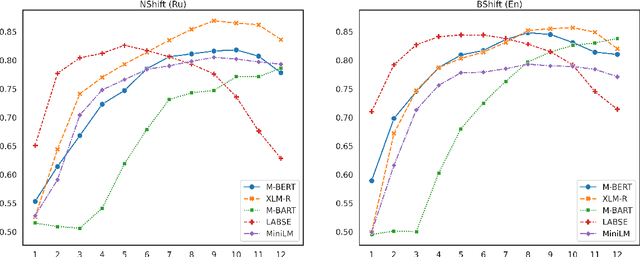
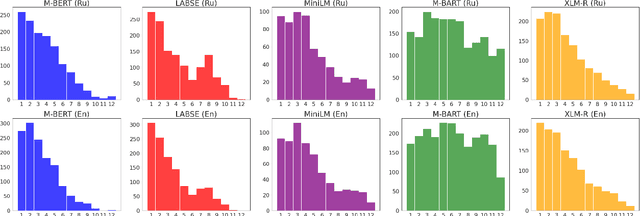

The success of pre-trained transformer language models has brought a great deal of interest on how these models work, and what they learn about language. However, prior research in the field is mainly devoted to English, and little is known regarding other languages. To this end, we introduce RuSentEval, an enhanced set of 14 probing tasks for Russian, including ones that have not been explored yet. We apply a combination of complementary probing methods to explore the distribution of various linguistic properties in five multilingual transformers for two typologically contrasting languages -- Russian and English. Our results provide intriguing findings that contradict the common understanding of how linguistic knowledge is represented, and demonstrate that some properties are learned in a similar manner despite the language differences.