 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPE: Assessing Few-shot Russian Language Understanding
Oct 23, 2022Recent advances in zero-shot and few-shot learning have shown promise for a scope of research and practical purposes. However, this fast-growing area lacks standardized evaluation suites for non-English languages, hindering progress outside the Anglo-centric paradigm. To address this line of research, we propose TAPE (Text Attack and Perturbation Evaluation), a novel benchmark that includes six more complex NLU tasks for Russian, covering multi-hop reasoning, ethical concepts, logic and commonsense knowledge. The TAPE's design focuses on systematic zero-shot and few-shot NLU evaluation: (i) linguistic-oriented adversarial attacks and perturbations for analyzing robustness, and (ii) subpopulations for nuanced interpretation. The detailed analysis of testing the autoregressive baselines indicates that simple spelling-based perturbations affect the performance the most, while paraphrasing the input has a more negligible effect. At the same time, the results demonstrate a significant gap between the neural and human baselines for most tasks. We publicly release TAPE (tape-benchmark.com) to foster research on robust LMs that can generalize to new tasks when little to no supervision is available.
Towards annotation of text worlds in a literary work
Nov 14, 2021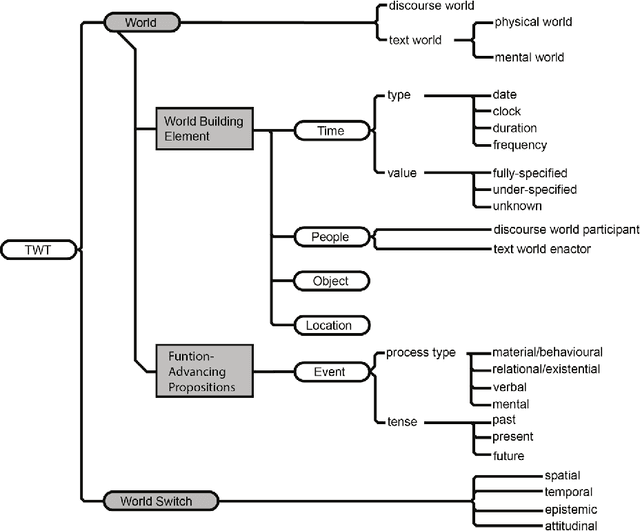
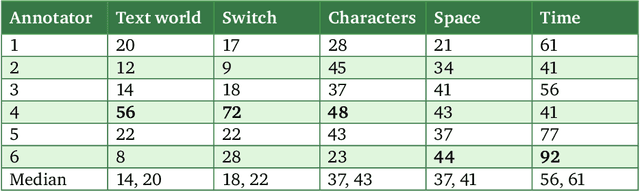

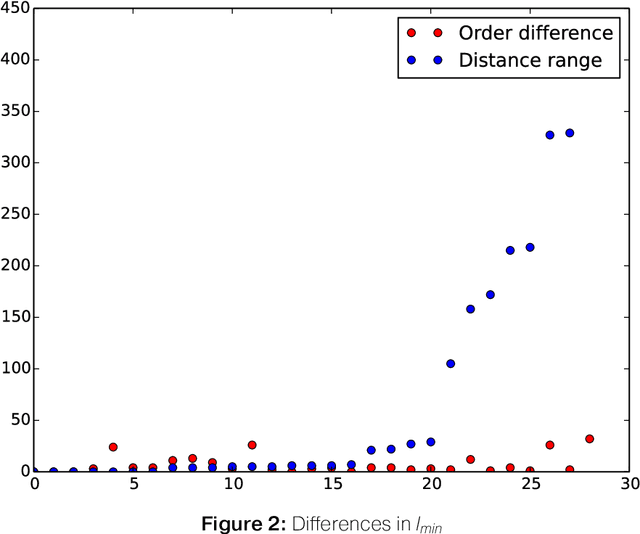
Literary texts are usually rich in meanings and their interpretation complicates corpus studies and automatic processing. There have been several attempts to create collections of literary texts with annotation of literary elements like the author's speech, characters, events, scenes etc. However, they resulted in small collections and standalone rules for annotation. The present article describes an experiment on lexical annotation of text worlds in a literary work and quantitative methods of their comparison. The experiment shows that for a well-agreed tag assignment annotation rules should be set much more strictly. However, if borders between text worlds and other elements are the result of a subjective interpretation, they should be modeled as fuzzy entities.