 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsycho-linguistic Experiment on Universal Semantic Components of Verbal Humor: System Description and Annotation
Jul 10, 2024

Objective criteria for universal semantic components that distinguish a humorous utterance from a non-humorous one are presently under debate. In this article, we give an in-depth observation of our system of self-paced reading for annotation of humor, that collects readers' annotations while they open a text word by word. The system registers keys that readers press to open the next word, choose a class (humorous versus non-humorous texts), change their choice. We also touch upon our psycho-linguistic experiment conducted with the system and the data collected during it.
A Russian Jeopardy! Data Set for Question-Answering Systems
Dec 04, 2021
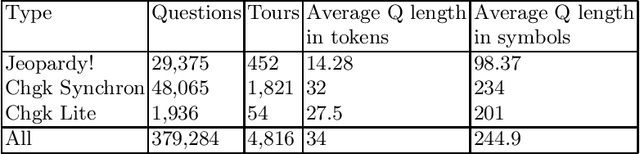
Question answering (QA) is one of the most common NLP tasks that relates to named entity recognition, fact extraction, semantic search and some other fields. In industry, it is much appreciated in chatbots and corporate information systems. It is also a challenging task that attracted the attention of a very general audience at the quiz show Jeopardy! In this article we describe a Jeopardy!-like Russian QA data set collected from the official Russian quiz database Chgk (che ge ka). The data set includes 379,284 quiz-like questions with 29,375 from the Russian analogue of Jeopardy! - "Own Game". We observe its linguistic features and the related QA-task. We conclude about perspectives of a QA competition based on the data set collected from this database.
Towards annotation of text worlds in a literary work
Nov 14, 2021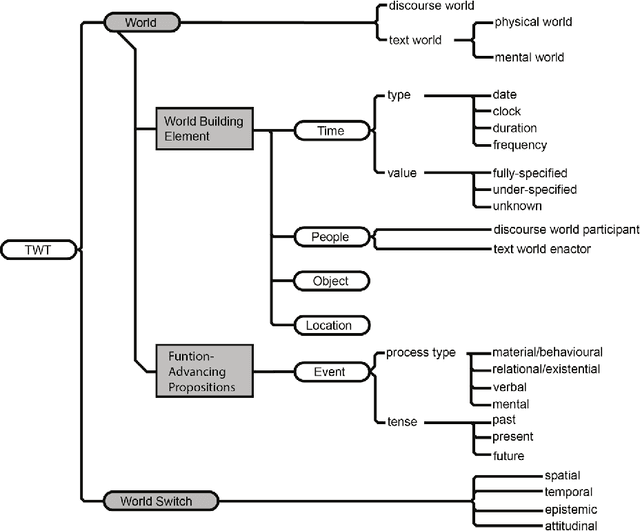
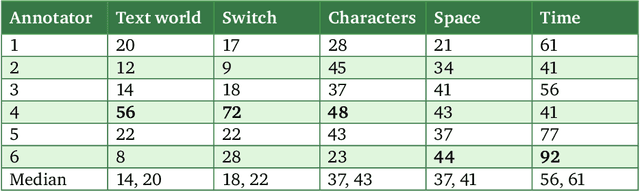

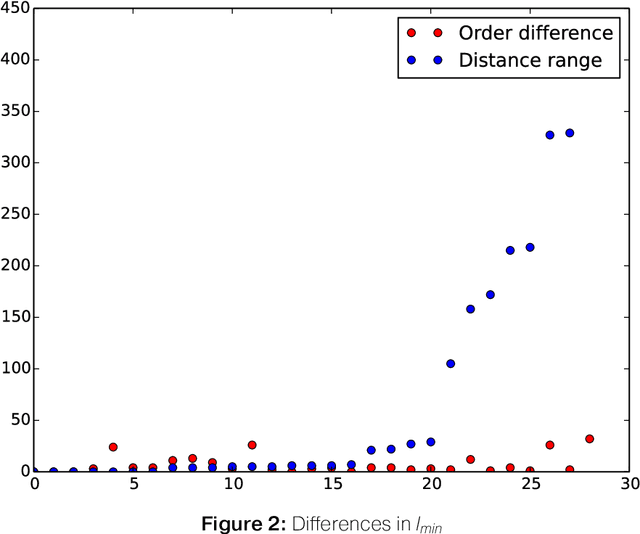
Literary texts are usually rich in meanings and their interpretation complicates corpus studies and automatic processing. There have been several attempts to create collections of literary texts with annotation of literary elements like the author's speech, characters, events, scenes etc. However, they resulted in small collections and standalone rules for annotation. The present article describes an experiment on lexical annotation of text worlds in a literary work and quantitative methods of their comparison. The experiment shows that for a well-agreed tag assignment annotation rules should be set much more strictly. However, if borders between text worlds and other elements are the result of a subjective interpretation, they should be modeled as fuzzy entities.
UTMN at SemEval-2020 Task 11: A Kitchen Solution to Automatic Propaganda Detection
Aug 22, 2020

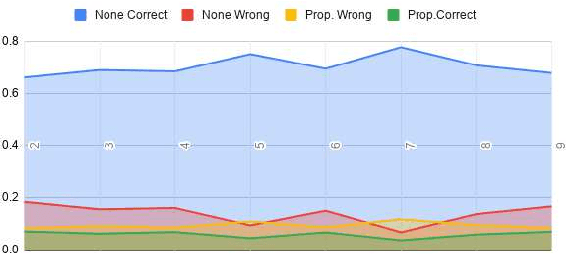
The article describes a fast solution to propaganda detection at SemEval-2020 Task 11, based onfeature adjustment. We use per-token vectorization of features and a simple Logistic Regressionclassifier to quickly test different hypotheses about our data. We come up with what seems to usthe best solution, however, we are unable to align it with the result of the metric suggested by theorganizers of the task. We test how our system handles class and feature imbalance by varying thenumber of samples of two classes (Propaganda and None) in the training set, the size of a contextwindow in which a token is vectorized and combination of vectorization means. The result of oursystem at SemEval2020 Task 11 is F-score=0.37.
A Comparative Analysis of Social Network Pages by Interests of Their Followers
Oct 17, 2017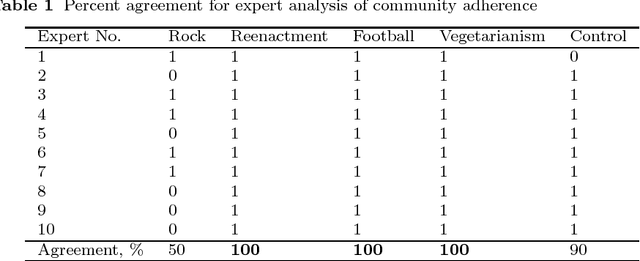
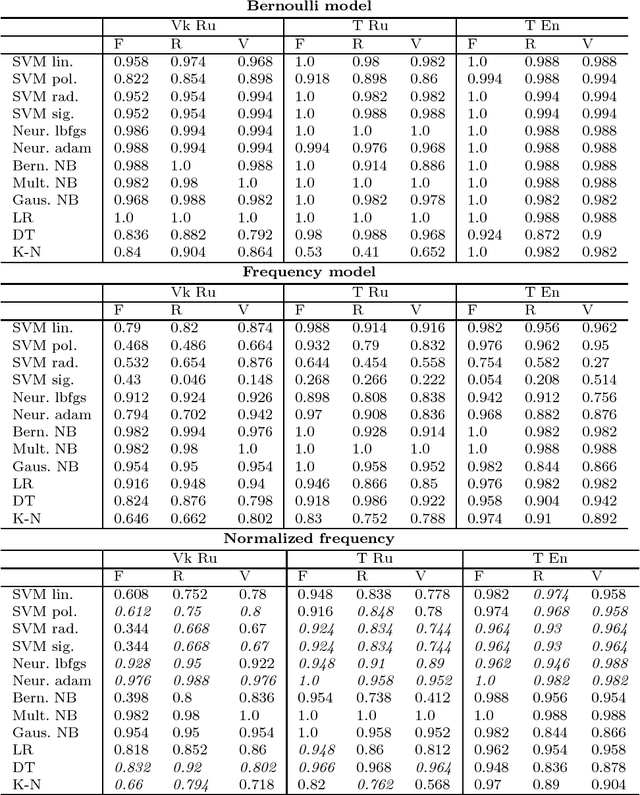

Being a matter of cognition, user interests should be apt to classification independent of the language of users, social network and content of interest itself. To prove it, we analyze a collection of English and Russian Twitter and Vkontakte community pages by interests of their followers. First, we create a model of Major Interests (MaIs) with the help of expert analysis and then classify a set of pages using machine learning algorithms (SVM, Neural Network, Naive Bayes, and some other). We take three interest domains that are typical of both English and Russian-speaking communities: football, rock music, vegetarianism. The results of classification show a greater correlation between Russian-Vkontakte and Russian-Twitter pages while English-Twitterpages appear to provide the highest score.
PunFields at SemEval-2017 Task 7: Employing Roget's Thesaurus in Automatic Pun Recognition and Interpretation
Jul 18, 2017



The article describes a model of automatic interpretation of English puns, based on Roget's Thesaurus, and its implementation, PunFields. In a pun, the algorithm discovers two groups of words that belong to two main semantic fields. The fields become a semantic vector based on which an SVM classifier learns to recognize puns. A rule-based model is then applied for recognition of intentionally ambiguous (target) words and their definitions. In SemEval Task 7 PunFields shows a considerably good result in pun classification, but requires improvement in searching for the target word and its definition.
Detecting Intentional Lexical Ambiguity in English Puns
Jul 18, 2017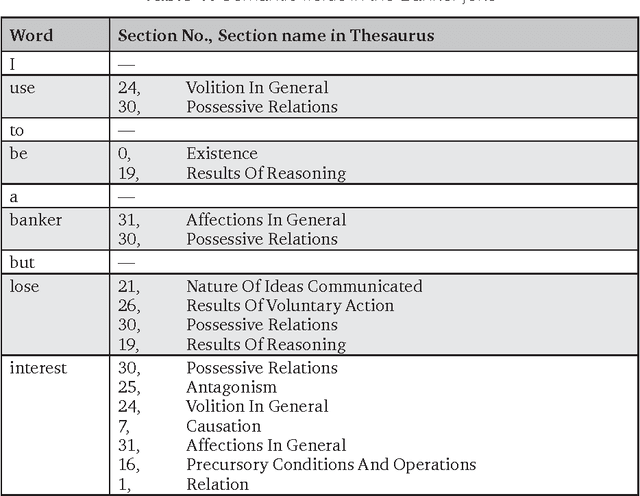
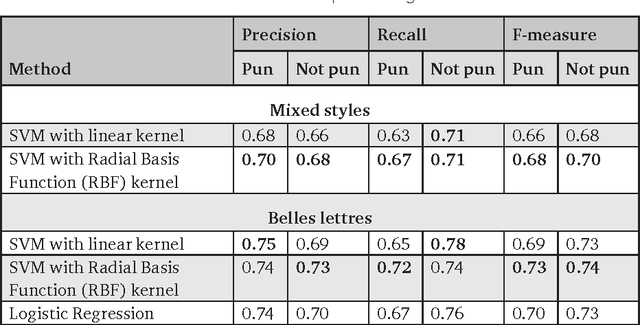
The article describes a model of automatic analysis of puns, where a word is intentionally used in two meanings at the same time (the target word). We employ Roget's Thesaurus to discover two groups of words which, in a pun, form around two abstract bits of meaning (semes). They become a semantic vector, based on which an SVM classifier learns to recognize puns, reaching a score 0.73 for F-measure. We apply several rule-based methods to locate intentionally ambiguous (target) words, based on structural and semantic criteria. It appears that the structural criterion is more effective, although it possibly characterizes only the tested dataset. The results we get correlate with the results of other teams at SemEval-2017 competition (Task 7 Detection and Interpretation of English Puns) considering effects of using supervised learning models and word statistics.