 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Social Network Pages by Interests of Their Followers
Oct 17, 2017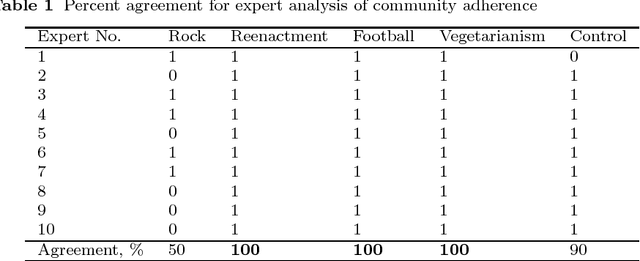
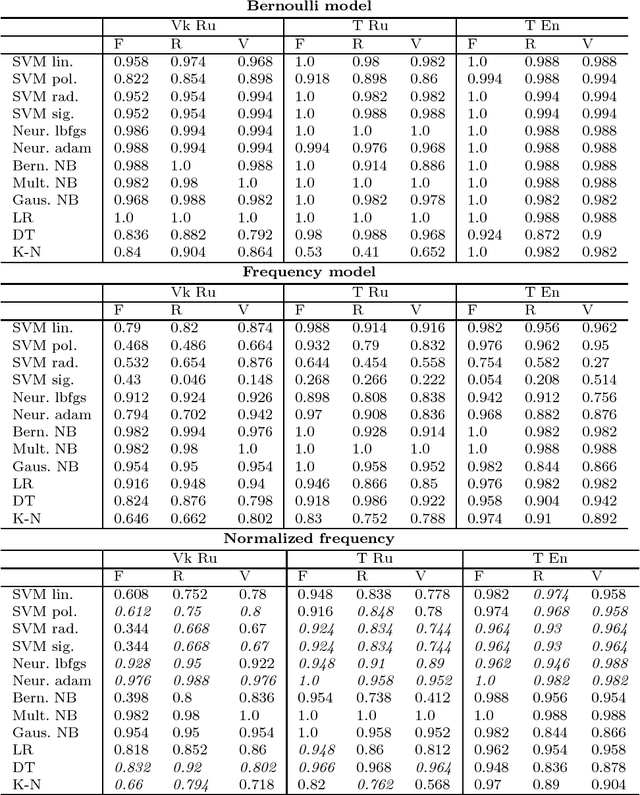

Being a matter of cognition, user interests should be apt to classification independent of the language of users, social network and content of interest itself. To prove it, we analyze a collection of English and Russian Twitter and Vkontakte community pages by interests of their followers. First, we create a model of Major Interests (MaIs) with the help of expert analysis and then classify a set of pages using machine learning algorithms (SVM, Neural Network, Naive Bayes, and some other). We take three interest domains that are typical of both English and Russian-speaking communities: football, rock music, vegetarianism. The results of classification show a greater correlation between Russian-Vkontakte and Russian-Twitter pages while English-Twitterpages appear to provide the highest score.
PunFields at SemEval-2017 Task 7: Employing Roget's Thesaurus in Automatic Pun Recognition and Interpretation
Jul 18, 2017



The article describes a model of automatic interpretation of English puns, based on Roget's Thesaurus, and its implementation, PunFields. In a pun, the algorithm discovers two groups of words that belong to two main semantic fields. The fields become a semantic vector based on which an SVM classifier learns to recognize puns. A rule-based model is then applied for recognition of intentionally ambiguous (target) words and their definitions. In SemEval Task 7 PunFields shows a considerably good result in pun classification, but requires improvement in searching for the target word and its definition.
Detecting Intentional Lexical Ambiguity in English Puns
Jul 18, 2017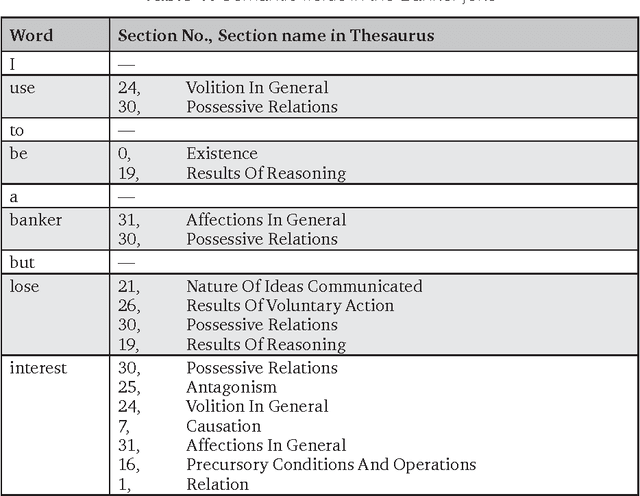
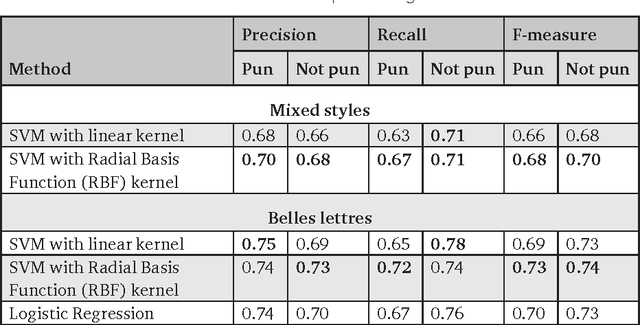
The article describes a model of automatic analysis of puns, where a word is intentionally used in two meanings at the same time (the target word). We employ Roget's Thesaurus to discover two groups of words which, in a pun, form around two abstract bits of meaning (semes). They become a semantic vector, based on which an SVM classifier learns to recognize puns, reaching a score 0.73 for F-measure. We apply several rule-based methods to locate intentionally ambiguous (target) words, based on structural and semantic criteria. It appears that the structural criterion is more effective, although it possibly characterizes only the tested dataset. The results we get correlate with the results of other teams at SemEval-2017 competition (Task 7 Detection and Interpretation of English Puns) considering effects of using supervised learning models and word statistics.