Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUTMN at SemEval-2020 Task 11: A Kitchen Solution to Automatic Propaganda Detection
Aug 22, 2020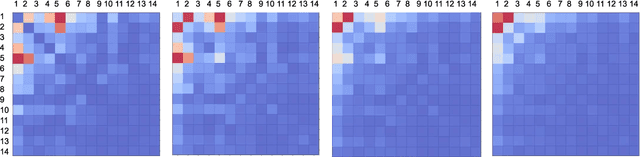

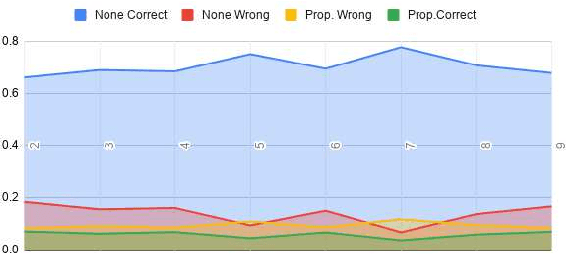
The article describes a fast solution to propaganda detection at SemEval-2020 Task 11, based onfeature adjustment. We use per-token vectorization of features and a simple Logistic Regressionclassifier to quickly test different hypotheses about our data. We come up with what seems to usthe best solution, however, we are unable to align it with the result of the metric suggested by theorganizers of the task. We test how our system handles class and feature imbalance by varying thenumber of samples of two classes (Propaganda and None) in the training set, the size of a contextwindow in which a token is vectorized and combination of vectorization means. The result of oursystem at SemEval2020 Task 11 is F-score=0.37.
* 5 pages -- the article proper; 2 pages -- references; 3 figures
Via