 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Interpretable Algorithms by Decompiling Transformers to RASP
Feb 09, 2026Recent work has shown that the computations of Transformers can be simulated in the RASP family of programming languages. These findings have enabled improved understanding of the expressive capacity and generalization abilities of Transformers. In particular, Transformers have been suggested to length-generalize exactly on problems that have simple RASP programs. However, it remains open whether trained models actually implement simple interpretable programs. In this paper, we present a general method to extract such programs from trained Transformers. The idea is to faithfully re-parameterize a Transformer as a RASP program and then apply causal interventions to discover a small sufficient sub-program. In experiments on small Transformers trained on algorithmic and formal language tasks, we show that our method often recovers simple and interpretable RASP programs from length-generalizing transformers. Our results provide the most direct evidence so far that Transformers internally implement simple RASP programs.
Born a Transformer -- Always a Transformer?
May 27, 2025Transformers have theoretical limitations in modeling certain sequence-to-sequence tasks, yet it remains largely unclear if these limitations play a role in large-scale pretrained LLMs, or whether LLMs might effectively overcome these constraints in practice due to the scale of both the models themselves and their pretraining data. We explore how these architectural constraints manifest after pretraining, by studying a family of $\textit{retrieval}$ and $\textit{copying}$ tasks inspired by Liu et al. [2024]. We use the recently proposed C-RASP framework for studying length generalization [Huang et al., 2025b] to provide guarantees for each of our settings. Empirically, we observe an $\textit{induction-versus-anti-induction}$ asymmetry, where pretrained models are better at retrieving tokens to the right (induction) rather than the left (anti-induction) of a query token. This asymmetry disappears upon targeted fine-tuning if length-generalization is guaranteed by theory. Mechanistic analysis reveals that this asymmetry is connected to the differences in the strength of induction versus anti-induction circuits within pretrained Transformers. We validate our findings through practical experiments on real-world tasks demonstrating reliability risks. Our results highlight that pretraining selectively enhances certain Transformer capabilities, but does not overcome fundamental length-generalization limits.
Contextualize-then-Aggregate: Circuits for In-Context Learning in Gemma-2 2B
Mar 31, 2025

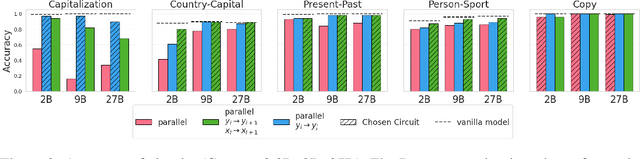

In-Context Learning (ICL) is an intriguing ability of large language models (LLMs). Despite a substantial amount of work on its behavioral aspects and how it emerges in miniature setups, it remains unclear which mechanism assembles task information from the individual examples in a fewshot prompt. We use causal interventions to identify information flow in Gemma-2 2B for five naturalistic ICL tasks. We find that the model infers task information using a two-step strategy we call contextualize-then-aggregate: In the lower layers, the model builds up representations of individual fewshot examples, which are contextualized by preceding examples through connections between fewshot input and output tokens across the sequence. In the higher layers, these representations are aggregated to identify the task and prepare prediction of the next output. The importance of the contextualization step differs between tasks, and it may become more important in the presence of ambiguous examples. Overall, by providing rigorous causal analysis, our results shed light on the mechanisms through which ICL happens in language models.
LUNA: A Framework for Language Understanding and Naturalness Assessment
Jan 09, 2024
The evaluation of Natural Language Generation (NLG) models has gained increased attention, urging the development of metrics that evaluate various aspects of generated text. LUNA addresses this challenge by introducing a unified interface for 20 NLG evaluation metrics. These metrics are categorized based on their reference-dependence and the type of text representation they employ, from string-based n-gram overlap to the utilization of static embeddings and pre-trained language models. The straightforward design of LUNA allows for easy extension with novel metrics, requiring just a few lines of code. LUNA offers a user-friendly tool for evaluating generated texts.