 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUNA: A Framework for Language Understanding and Naturalness Assessment
Jan 09, 2024
The evaluation of Natural Language Generation (NLG) models has gained increased attention, urging the development of metrics that evaluate various aspects of generated text. LUNA addresses this challenge by introducing a unified interface for 20 NLG evaluation metrics. These metrics are categorized based on their reference-dependence and the type of text representation they employ, from string-based n-gram overlap to the utilization of static embeddings and pre-trained language models. The straightforward design of LUNA allows for easy extension with novel metrics, requiring just a few lines of code. LUNA offers a user-friendly tool for evaluating generated texts.
Findings of the The RuATD Shared Task 2022 on Artificial Text Detection in Russian
Jun 03, 2022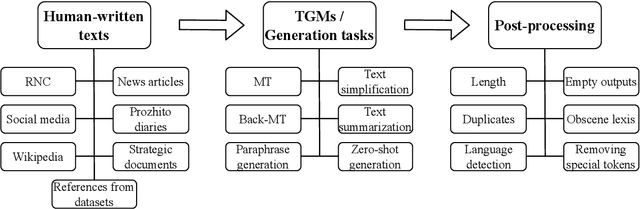
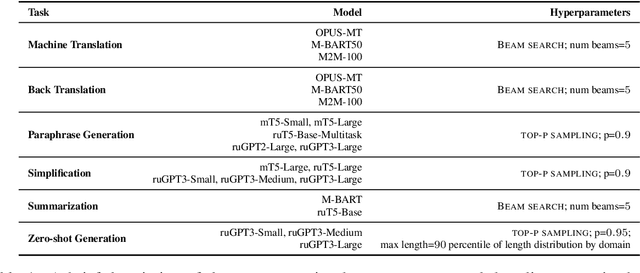
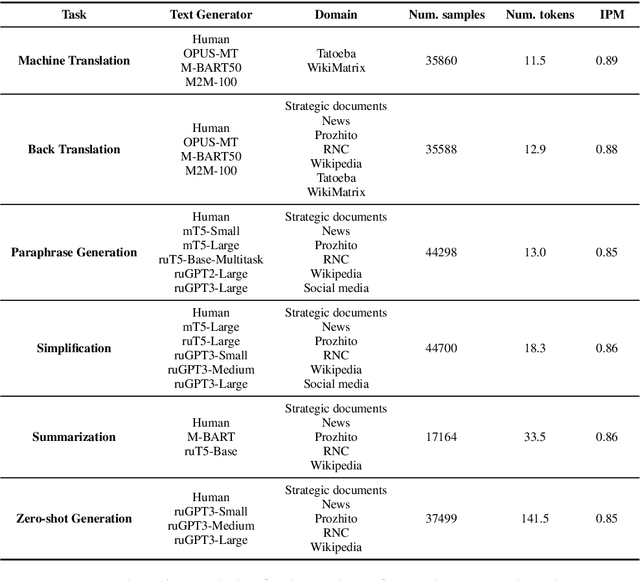
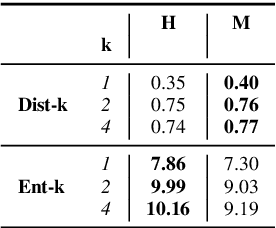
We present the shared task on artificial text detection in Russian, which is organized as a part of the Dialogue Evaluation initiative, held in 2022. The shared task dataset includes texts from 14 text generators, i.e., one human writer and 13 text generative models fine-tuned for one or more of the following generation tasks: machine translation, paraphrase generation, text summarization, text simplification. We also consider back-translation and zero-shot generation approaches. The human-written texts are collected from publicly available resources across multiple domains. The shared task consists of two sub-tasks: (i) to determine if a given text is automatically generated or written by a human; (ii) to identify the author of a given text. The first task is framed as a binary classification problem. The second task is a multi-class classification problem. We provide count-based and BERT-based baselines, along with the human evaluation on the first sub-task. A total of 30 and 8 systems have been submitted to the binary and multi-class sub-tasks, correspondingly. Most teams outperform the baselines by a wide margin. We publicly release our codebase, human evaluation results, and other materials in our GitHub repository (https://github.com/dialogue-evaluation/RuATD).