 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuCoLA: Russian Corpus of Linguistic Acceptability
Oct 23, 2022



Linguistic acceptability (LA) attracts the attention of the research community due to its many uses, such as testing the grammatical knowledge of language models and filtering implausible texts with acceptability classifiers. However, the application scope of LA in languages other than English is limited due to the lack of high-quality resources. To this end, we introduce the Russian Corpus of Linguistic Acceptability (RuCoLA), built from the ground up under the well-established binary LA approach. RuCoLA consists of $9.8$k in-domain sentences from linguistic publications and $3.6$k out-of-domain sentences produced by generative models. The out-of-domain set is created to facilitate the practical use of acceptability for improving language generation. Our paper describes the data collection protocol and presents a fine-grained analysis of acceptability classification experiments with a range of baseline approaches. In particular, we demonstrate that the most widely used language models still fall behind humans by a large margin, especially when detecting morphological and semantic errors. We release RuCoLA, the code of experiments, and a public leaderboard (rucola-benchmark.com) to assess the linguistic competence of language models for Russian.
Findings of the The RuATD Shared Task 2022 on Artificial Text Detection in Russian
Jun 03, 2022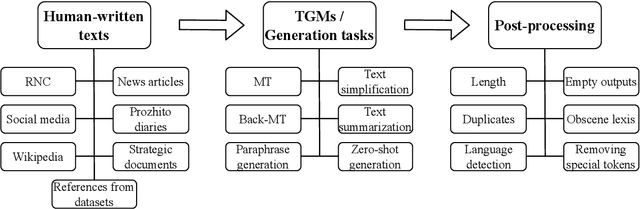
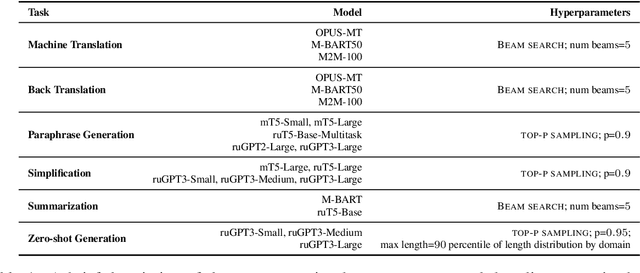
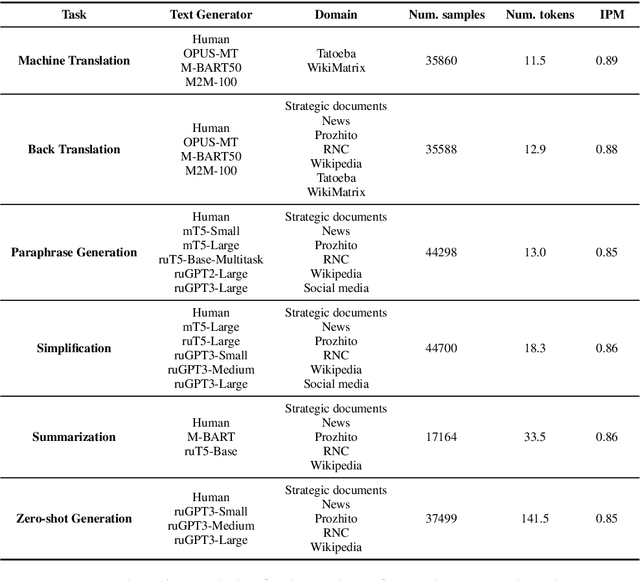
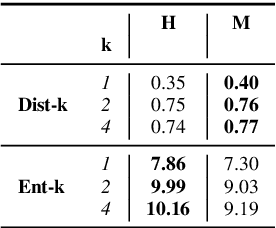
We present the shared task on artificial text detection in Russian, which is organized as a part of the Dialogue Evaluation initiative, held in 2022. The shared task dataset includes texts from 14 text generators, i.e., one human writer and 13 text generative models fine-tuned for one or more of the following generation tasks: machine translation, paraphrase generation, text summarization, text simplification. We also consider back-translation and zero-shot generation approaches. The human-written texts are collected from publicly available resources across multiple domains. The shared task consists of two sub-tasks: (i) to determine if a given text is automatically generated or written by a human; (ii) to identify the author of a given text. The first task is framed as a binary classification problem. The second task is a multi-class classification problem. We provide count-based and BERT-based baselines, along with the human evaluation on the first sub-task. A total of 30 and 8 systems have been submitted to the binary and multi-class sub-tasks, correspondingly. Most teams outperform the baselines by a wide margin. We publicly release our codebase, human evaluation results, and other materials in our GitHub repository (https://github.com/dialogue-evaluation/RuATD).
Russian News Clustering and Headline Selection Shared Task
May 08, 2021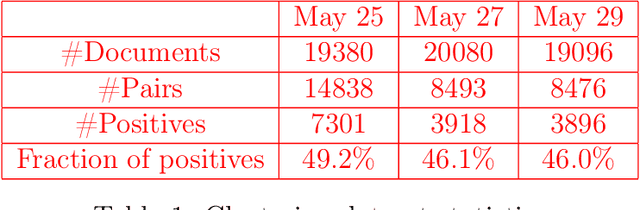



This paper presents the results of the Russian News Clustering and Headline Selection shared task. As a part of it, we propose the tasks of Russian news event detection, headline selection, and headline generation. These tasks are accompanied by datasets and baselines. The presented datasets for event detection and headline selection are the first public Russian datasets for their tasks. The headline generation dataset is based on clustering and provides multiple reference headlines for every cluster, unlike the previous datasets. Finally, the approaches proposed by the shared task participants are reported and analyzed.
RuREBus: a Case Study of Joint Named Entity Recognition and Relation Extraction from e-Government Domain
Oct 29, 2020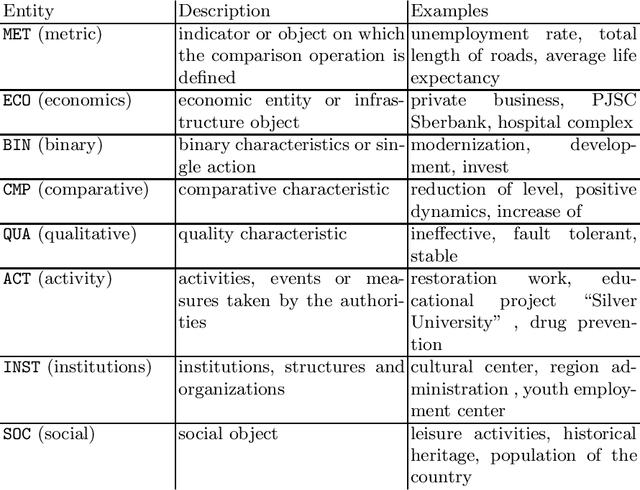

We show-case an application of information extraction methods, such as named entity recognition (NER) and relation extraction (RE) to a novel corpus, consisting of documents, issued by a state agency. The main challenges of this corpus are: 1) the annotation scheme differs greatly from the one used for the general domain corpora, and 2) the documents are written in a language other than English. Unlike expectations, the state-of-the-art transformer-based models show modest performance for both tasks, either when approached sequentially, or in an end-to-end fashion. Our experiments have demonstrated that fine-tuning on a large unlabeled corpora does not automatically yield significant improvement and thus we may conclude that more sophisticated strategies of leveraging unlabelled texts are demanded. In this paper, we describe the whole developed pipeline, starting from text annotation, baseline development, and designing a shared task in hopes of improving the baseline. Eventually, we realize that the current NER and RE technologies are far from being mature and do not overcome so far challenges like ours.
NoPropaganda at SemEval-2020 Task 11: A Borrowed Approach to Sequence Tagging and Text Classification
Jul 25, 2020
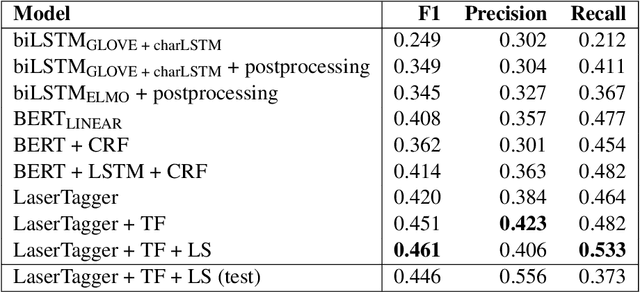
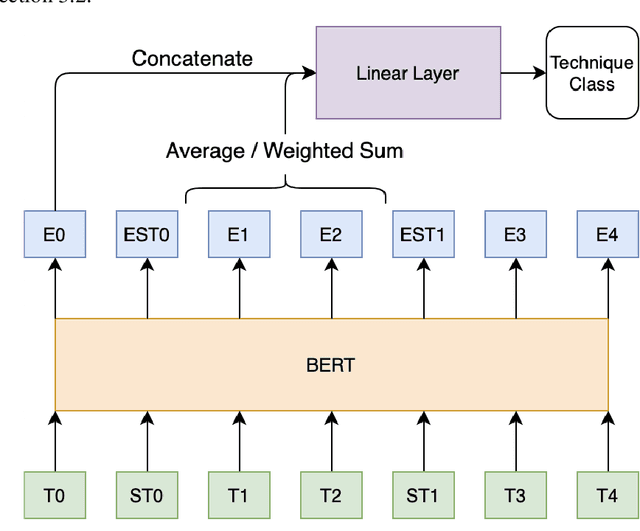

This paper describes our contribution to SemEval-2020 Task 11: Detection Of Propaganda Techniques In News Articles. We start with simple LSTM baselines and move to an autoregressive transformer decoder to predict long continuous propaganda spans for the first subtask. We also adopt an approach from relation extraction by enveloping spans mentioned above with special tokens for the second subtask of propaganda technique classification. Our models report an F-score of 44.6% and a micro-averaged F-score of 58.2% for those tasks accordingly.
So What's the Plan? Mining Strategic Planning Documents
Jul 07, 2020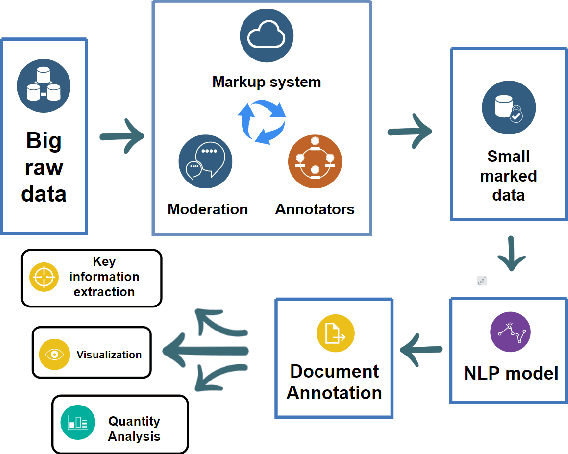

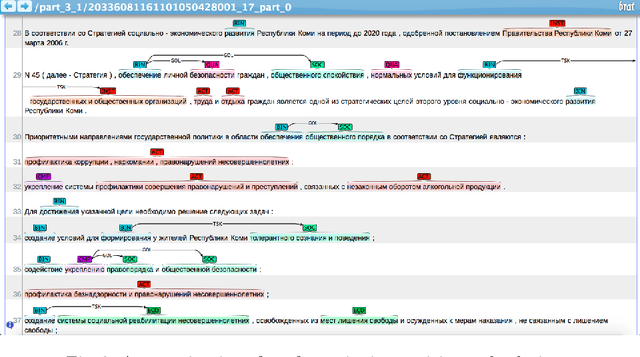
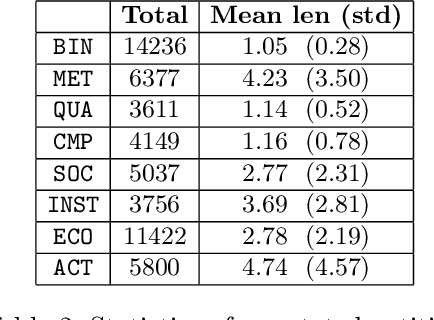
In this paper we present a corpus of Russian strategic planning documents, RuREBus. This project is grounded both from language technology and e-government perspectives. Not only new language sources and tools are being developed, but also their applications to e-goverment research. We demonstrate the pipeline for creating a text corpus from scratch. First, the annotation schema is designed. Next texts are marked up using human-in-the-loop strategy, so that preliminary annotations are derived from a machine learning model and are manually corrected. The amount of annotated texts is large enough to showcase what insights can be gained from RuREBus.
AGRR-2019: A Corpus for Gapping Resolution in Russian
Jun 10, 2019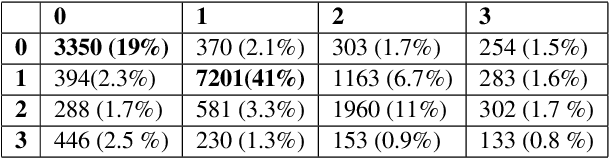
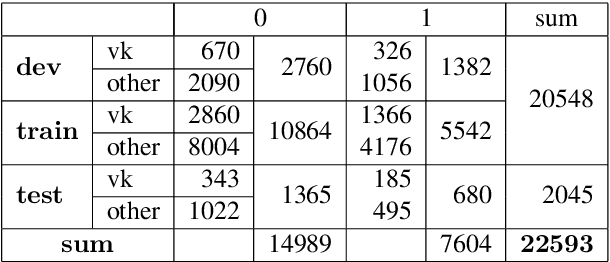
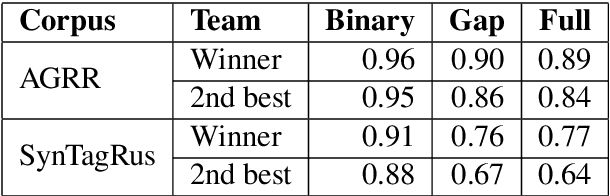
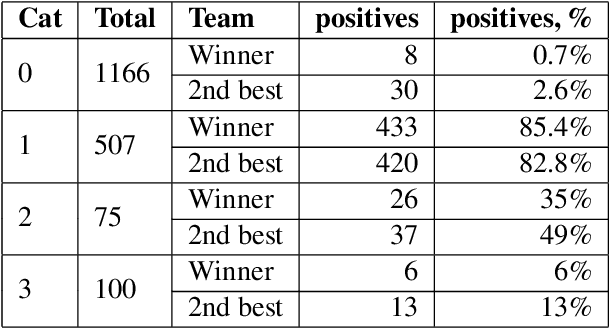
This paper provides a comprehensive overview of the gapping dataset for Russian that consists of 7.5k sentences with gapping (as well as 15k relevant negative sentences) and comprises data from various genres: news, fiction, social media and technical texts. The dataset was prepared for the Automatic Gapping Resolution Shared Task for Russian (AGRR-2019) - a competition aimed at stimulating the development of NLP tools and methods for processing of ellipsis. In this paper, we pay special attention to the gapping resolution methods that were introduced within the shared task as well as an alternative test set that illustrates that our corpus is a diverse and representative subset of Russian language gapping sufficient for effective utilization of machine learning techniques.