 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuREBus: a Case Study of Joint Named Entity Recognition and Relation Extraction from e-Government Domain
Oct 29, 2020

We show-case an application of information extraction methods, such as named entity recognition (NER) and relation extraction (RE) to a novel corpus, consisting of documents, issued by a state agency. The main challenges of this corpus are: 1) the annotation scheme differs greatly from the one used for the general domain corpora, and 2) the documents are written in a language other than English. Unlike expectations, the state-of-the-art transformer-based models show modest performance for both tasks, either when approached sequentially, or in an end-to-end fashion. Our experiments have demonstrated that fine-tuning on a large unlabeled corpora does not automatically yield significant improvement and thus we may conclude that more sophisticated strategies of leveraging unlabelled texts are demanded. In this paper, we describe the whole developed pipeline, starting from text annotation, baseline development, and designing a shared task in hopes of improving the baseline. Eventually, we realize that the current NER and RE technologies are far from being mature and do not overcome so far challenges like ours.
So What's the Plan? Mining Strategic Planning Documents
Jul 07, 2020

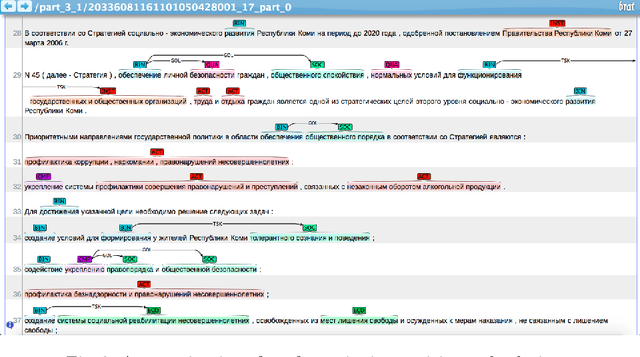
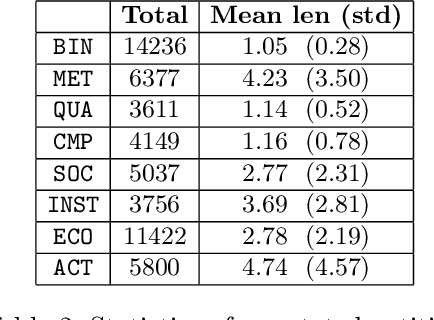
In this paper we present a corpus of Russian strategic planning documents, RuREBus. This project is grounded both from language technology and e-government perspectives. Not only new language sources and tools are being developed, but also their applications to e-goverment research. We demonstrate the pipeline for creating a text corpus from scratch. First, the annotation schema is designed. Next texts are marked up using human-in-the-loop strategy, so that preliminary annotations are derived from a machine learning model and are manually corrected. The amount of annotated texts is large enough to showcase what insights can be gained from RuREBus.