 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuSentEval: Linguistic Source, Encoder Force!
Paper and Code

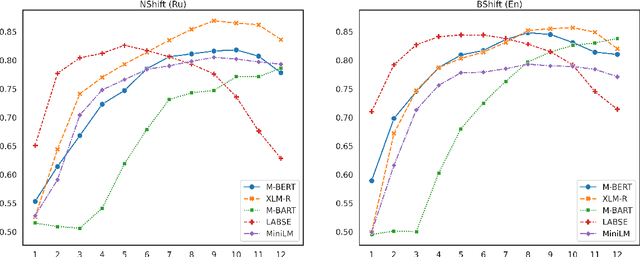
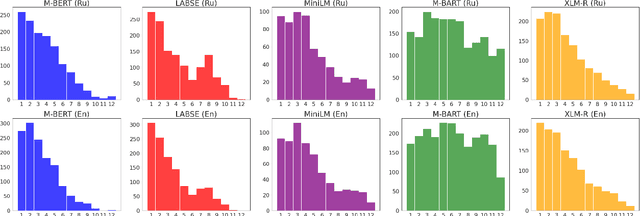

The success of pre-trained transformer language models has brought a great deal of interest on how these models work, and what they learn about language. However, prior research in the field is mainly devoted to English, and little is known regarding other languages. To this end, we introduce RuSentEval, an enhanced set of 14 probing tasks for Russian, including ones that have not been explored yet. We apply a combination of complementary probing methods to explore the distribution of various linguistic properties in five multilingual transformers for two typologically contrasting languages -- Russian and English. Our results provide intriguing findings that contradict the common understanding of how linguistic knowledge is represented, and demonstrate that some properties are learned in a similar manner despite the language differences.