 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Family of Pretrained Transformer Language Models for Russian
Paper and Code
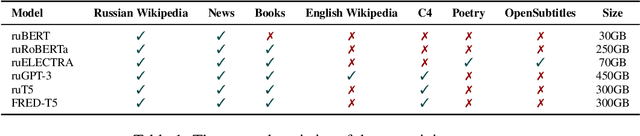
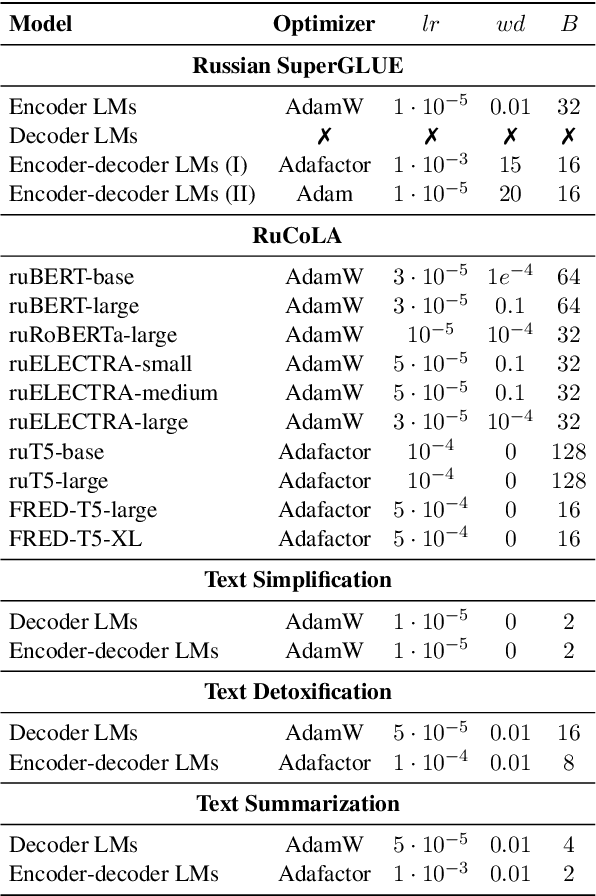
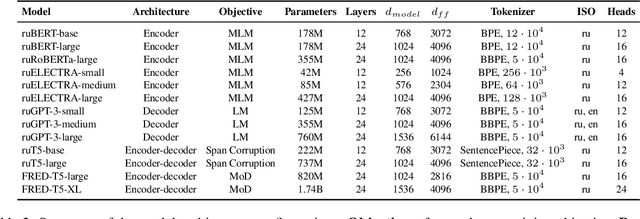
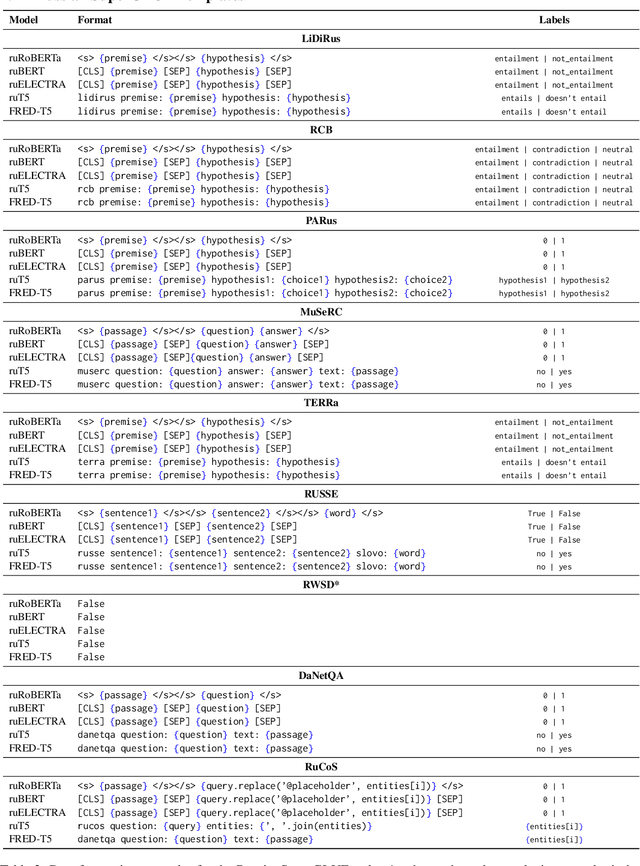
Nowadays, Transformer language models (LMs) represent a fundamental component of the NLP research methodologies and applications. However, the development of such models specifically for the Russian language has received little attention. This paper presents a collection of 13 Russian Transformer LMs based on the encoder (ruBERT, ruRoBERTa, ruELECTRA), decoder (ruGPT-3), and encoder-decoder (ruT5, FRED-T5) models in multiple sizes. Access to these models is readily available via the HuggingFace platform. We provide a report of the model architecture design and pretraining, and the results of evaluating their generalization abilities on Russian natural language understanding and generation datasets and benchmarks. By pretraining and releasing these specialized Transformer LMs, we hope to broaden the scope of the NLP research directions and enable the development of industrial solutions for the Russian language.