 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
A Methodology for Generative Spelling Correction via Natural Spelling Errors Emulation across Multiple Domains and Languages
Aug 18, 2023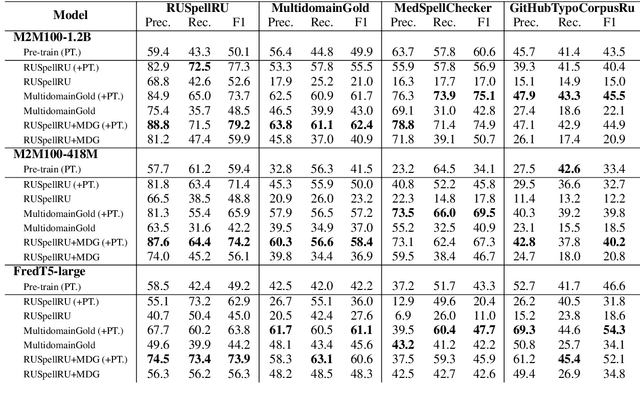
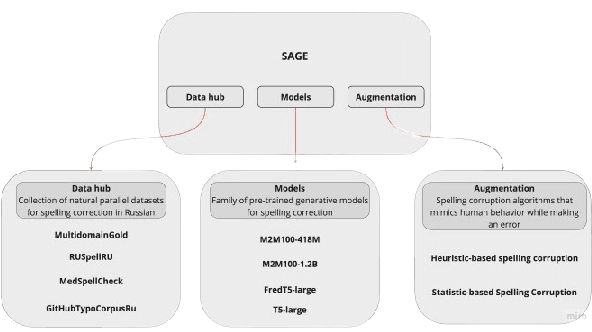
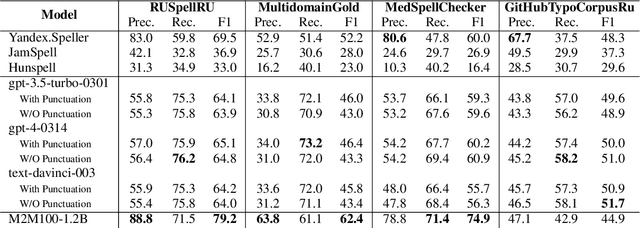
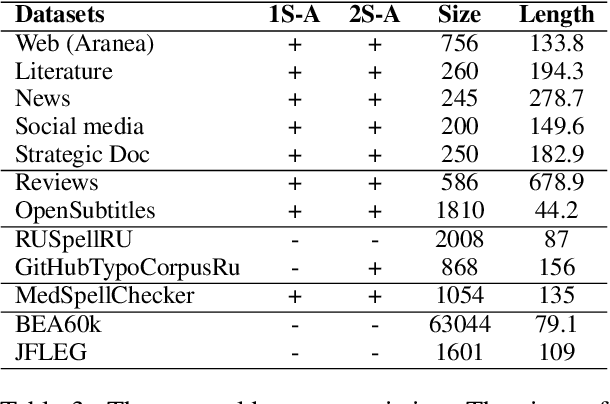
Modern large language models demonstrate impressive capabilities in text generation and generalization. However, they often struggle with solving text editing tasks, particularly when it comes to correcting spelling errors and mistypings. In this paper, we present a methodology for generative spelling correction (SC), which was tested on English and Russian languages and potentially can be extended to any language with minor changes. Our research mainly focuses on exploring natural spelling errors and mistypings in texts and studying the ways those errors can be emulated in correct sentences to effectively enrich generative models' pre-train procedure. We investigate the impact of such emulations and the models' abilities across different text domains. In this work, we investigate two spelling corruption techniques: 1) first one mimics human behavior when making a mistake through leveraging statistics of errors from particular dataset and 2) second adds the most common spelling errors, keyboard miss clicks, and some heuristics within the texts. We conducted experiments employing various corruption strategies, models' architectures and sizes on the pre-training and fine-tuning stages and evaluated the models using single-domain and multi-domain test sets. As a practical outcome of our work, we introduce SAGE (Spell checking via Augmentation and Generative distribution Emulation) is a library for automatic generative SC that includes a family of pre-trained generative models and built-in augmentation algorithms.