 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERA: A Comprehensive LLM Evaluation in Russian
Jan 12, 2024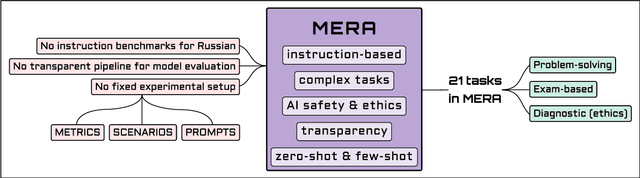
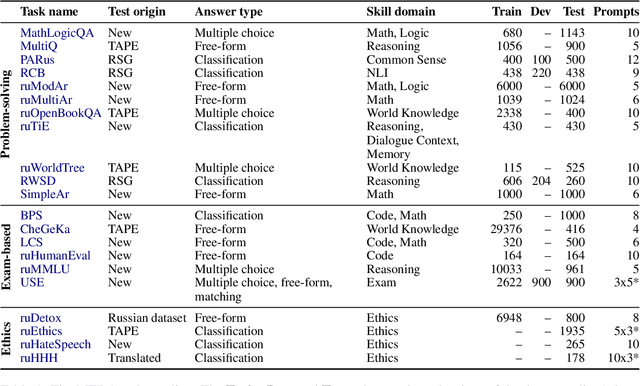

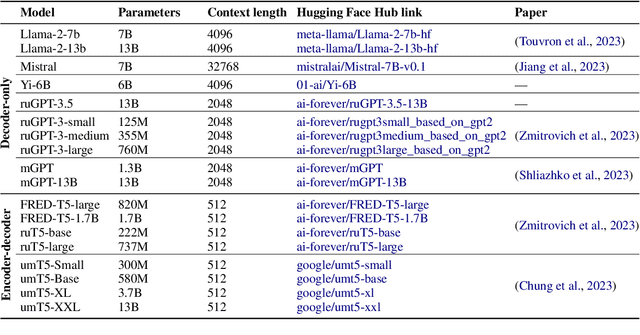
Over the past few years, one of the most notable advancements in AI research has been in foundation models (FMs), headlined by the rise of language models (LMs). As the models' size increases, LMs demonstrate enhancements in measurable aspects and the development of new qualitative features. However, despite researchers' attention and the rapid growth in LM application, the capabilities, limitations, and associated risks still need to be better understood. To address these issues, we introduce an open Multimodal Evaluation of Russian-language Architectures (MERA), a new instruction benchmark for evaluating foundation models oriented towards the Russian language. The benchmark encompasses 21 evaluation tasks for generative models in 11 skill domains and is designed as a black-box test to ensure the exclusion of data leakage. The paper introduces a methodology to evaluate FMs and LMs in zero- and few-shot fixed instruction settings that can be extended to other modalities. We propose an evaluation methodology, an open-source code base for the MERA assessment, and a leaderboard with a submission system. We evaluate open LMs as baselines and find that they are still far behind the human level. We publicly release MERA to guide forthcoming research, anticipate groundbreaking model features, standardize the evaluation procedure, and address potential societal drawbacks.
A Methodology for Generative Spelling Correction via Natural Spelling Errors Emulation across Multiple Domains and Languages
Aug 18, 2023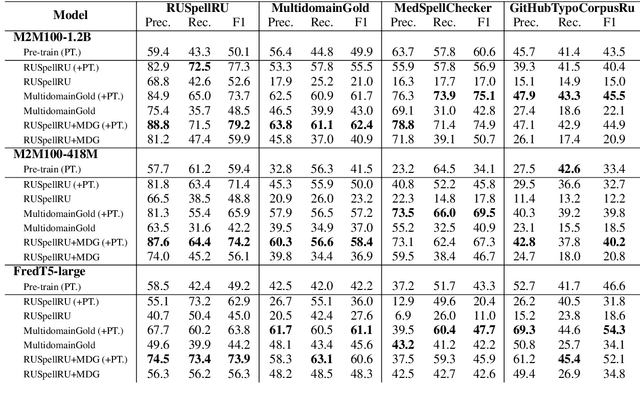
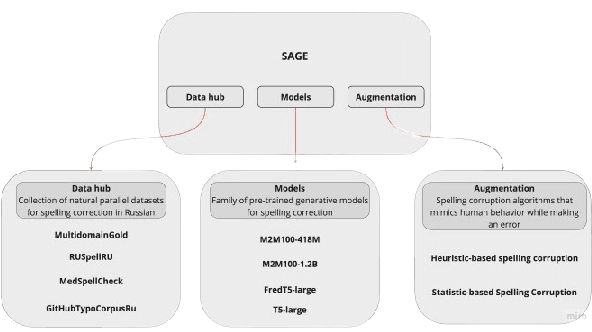
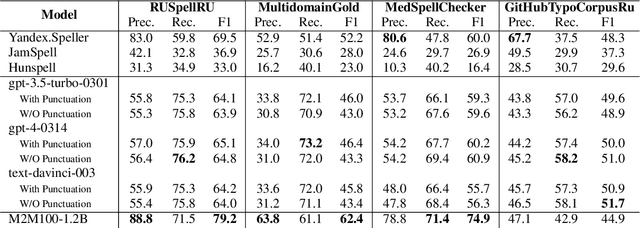
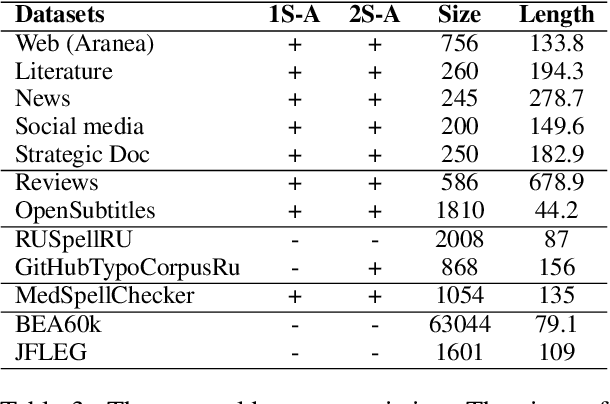
Modern large language models demonstrate impressive capabilities in text generation and generalization. However, they often struggle with solving text editing tasks, particularly when it comes to correcting spelling errors and mistypings. In this paper, we present a methodology for generative spelling correction (SC), which was tested on English and Russian languages and potentially can be extended to any language with minor changes. Our research mainly focuses on exploring natural spelling errors and mistypings in texts and studying the ways those errors can be emulated in correct sentences to effectively enrich generative models' pre-train procedure. We investigate the impact of such emulations and the models' abilities across different text domains. In this work, we investigate two spelling corruption techniques: 1) first one mimics human behavior when making a mistake through leveraging statistics of errors from particular dataset and 2) second adds the most common spelling errors, keyboard miss clicks, and some heuristics within the texts. We conducted experiments employing various corruption strategies, models' architectures and sizes on the pre-training and fine-tuning stages and evaluated the models using single-domain and multi-domain test sets. As a practical outcome of our work, we introduce SAGE (Spell checking via Augmentation and Generative distribution Emulation) is a library for automatic generative SC that includes a family of pre-trained generative models and built-in augmentation algorithms.