 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionFrames: Efficient Architectural Aspects for Text-to-Video Generation Pipeline
Nov 22, 2023


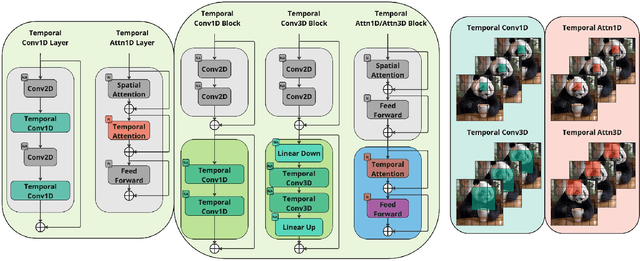
Multimedia generation approaches occupy a prominent place in artificial intelligence research. Text-to-image models achieved high-quality results over the last few years. However, video synthesis methods recently started to develop. This paper presents a new two-stage latent diffusion text-to-video generation architecture based on the text-to-image diffusion model. The first stage concerns keyframes synthesis to figure the storyline of a video, while the second one is devoted to interpolation frames generation to make movements of the scene and objects smooth. We compare several temporal conditioning approaches for keyframes generation. The results show the advantage of using separate temporal blocks over temporal layers in terms of metrics reflecting video generation quality aspects and human preference. The design of our interpolation model significantly reduces computational costs compared to other masked frame interpolation approaches. Furthermore, we evaluate different configurations of MoVQ-based video decoding scheme to improve consistency and achieve higher PSNR, SSIM, MSE, and LPIPS scores. Finally, we compare our pipeline with existing solutions and achieve top-2 scores overall and top-1 among open-source solutions: CLIPSIM = 0.2976 and FVD = 433.054. Project page: https://ai-forever.github.io/kandinsky-video/
Zero-Shot Cross-Lingual Transfer in Legal Domain Using Transformer Models
Dec 11, 2021
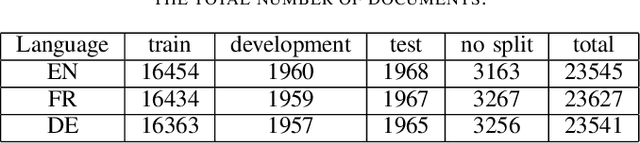

Zero-shot cross-lingual transfer is an important feature in modern NLP models and architectures to support low-resource languages. In this work, We study zero-shot cross-lingual transfer from English to French and German under Multi-Label Text Classification, where we train a classifier using English training set, and we test using French and German test sets. We extend EURLEX57K dataset, the English dataset for topic classification of legal documents, with French and German official translation. We investigate the effect of using some training techniques, namely Gradual Unfreezing and Language Model finetuning, on the quality of zero-shot cross-lingual transfer. We find that Language model finetuning of multi-lingual pre-trained model (M-DistilBERT, M-BERT) leads to 32.0-34.94%, 76.15-87.54% relative improvement on French and German test sets correspondingly. Also, Gradual unfreezing of pre-trained model's layers during training results in relative improvement of 38-45% for French and 58-70% for German. Compared to training a model in Joint Training scheme using English, French and German training sets, zero-shot BERT-based classification model reaches 86% of the performance achieved by jointly-trained BERT-based classification model.
Large Scale Legal Text Classification Using Transformer Models
Oct 24, 2020
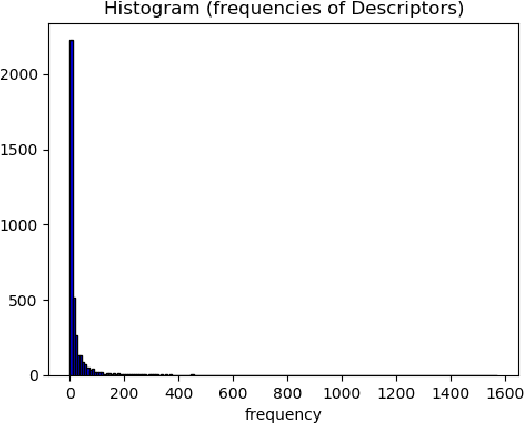
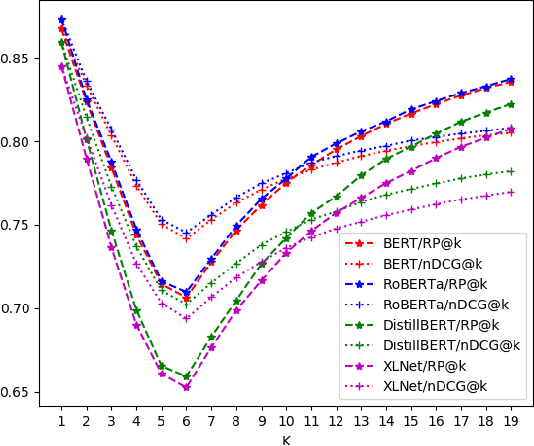
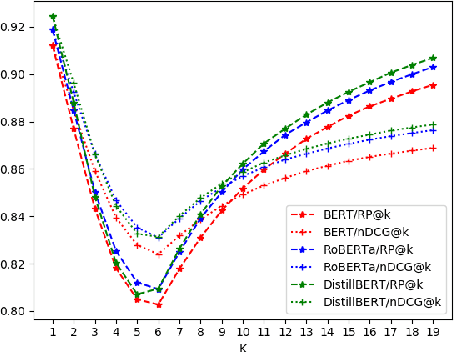
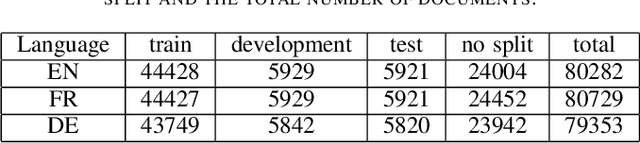
Large multi-label text classification is a challenging Natural Language Processing (NLP) problem that is concerned with text classification for datasets with thousands of labels. We tackle this problem in the legal domain, where datasets, such as JRC-Acquis and EURLEX57K labeled with the EuroVoc vocabulary were created within the legal information systems of the European Union. The EuroVoc taxonomy includes around 7000 concepts. In this work, we study the performance of various recent transformer-based models in combination with strategies such as generative pretraining, gradual unfreezing and discriminative learning rates in order to reach competitive classification performance, and present new state-of-the-art results of 0.661 (F1) for JRC-Acquis and 0.754 for EURLEX57K. Furthermore, we quantify the impact of individual steps, such as language model fine-tuning or gradual unfreezing in an ablation study, and provide reference dataset splits created with an iterative stratification algorithm.
Russian Natural Language Generation: Creation of a Language Modelling Dataset and Evaluation with Modern Neural Architectures
May 05, 2020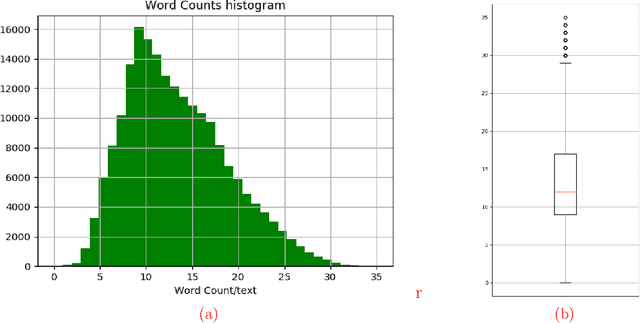
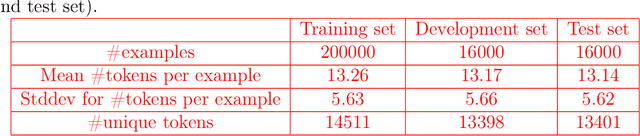


Generating coherent, grammatically correct, and meaningful text is very challenging, however, it is crucial to many modern NLP systems. So far, research has mostly focused on English language, for other languages both standardized datasets, as well as experiments with state-of-the-art models, are rare. In this work, we i) provide a novel reference dataset for Russian language modeling, ii) experiment with popular modern methods for text generation, namely variational autoencoders, and generative adversarial networks, which we trained on the new dataset. We evaluate the generated text regarding metrics such as perplexity, grammatical correctness and lexical diversity.