 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Cross-Lingual Transfer in Legal Domain Using Transformer Models
Paper and Code
Dec 11, 2021
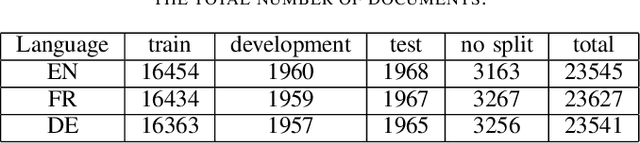
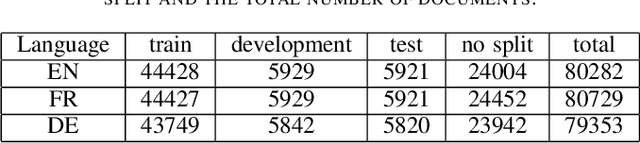

Zero-shot cross-lingual transfer is an important feature in modern NLP models and architectures to support low-resource languages. In this work, We study zero-shot cross-lingual transfer from English to French and German under Multi-Label Text Classification, where we train a classifier using English training set, and we test using French and German test sets. We extend EURLEX57K dataset, the English dataset for topic classification of legal documents, with French and German official translation. We investigate the effect of using some training techniques, namely Gradual Unfreezing and Language Model finetuning, on the quality of zero-shot cross-lingual transfer. We find that Language model finetuning of multi-lingual pre-trained model (M-DistilBERT, M-BERT) leads to 32.0-34.94%, 76.15-87.54% relative improvement on French and German test sets correspondingly. Also, Gradual unfreezing of pre-trained model's layers during training results in relative improvement of 38-45% for French and 58-70% for German. Compared to training a model in Joint Training scheme using English, French and German training sets, zero-shot BERT-based classification model reaches 86% of the performance achieved by jointly-trained BERT-based classification model.