 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Cross-Lingual Transfer in Legal Domain Using Transformer Models
Dec 11, 2021
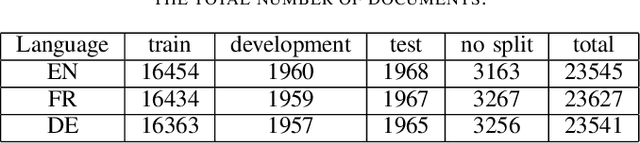
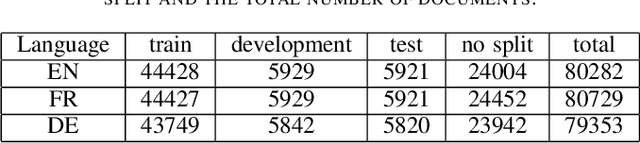

Zero-shot cross-lingual transfer is an important feature in modern NLP models and architectures to support low-resource languages. In this work, We study zero-shot cross-lingual transfer from English to French and German under Multi-Label Text Classification, where we train a classifier using English training set, and we test using French and German test sets. We extend EURLEX57K dataset, the English dataset for topic classification of legal documents, with French and German official translation. We investigate the effect of using some training techniques, namely Gradual Unfreezing and Language Model finetuning, on the quality of zero-shot cross-lingual transfer. We find that Language model finetuning of multi-lingual pre-trained model (M-DistilBERT, M-BERT) leads to 32.0-34.94%, 76.15-87.54% relative improvement on French and German test sets correspondingly. Also, Gradual unfreezing of pre-trained model's layers during training results in relative improvement of 38-45% for French and 58-70% for German. Compared to training a model in Joint Training scheme using English, French and German training sets, zero-shot BERT-based classification model reaches 86% of the performance achieved by jointly-trained BERT-based classification model.
Large Scale Legal Text Classification Using Transformer Models
Oct 24, 2020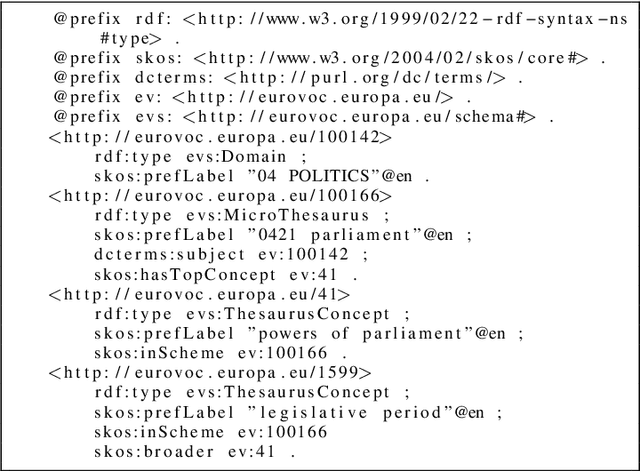
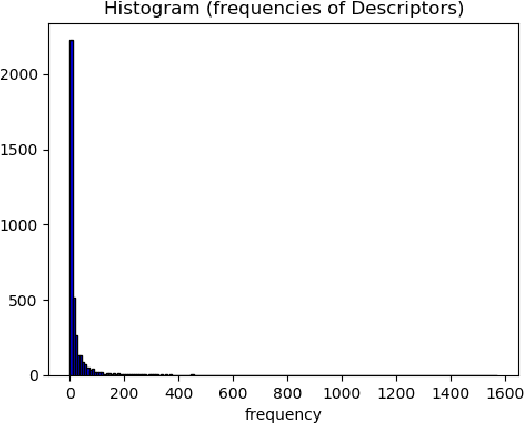
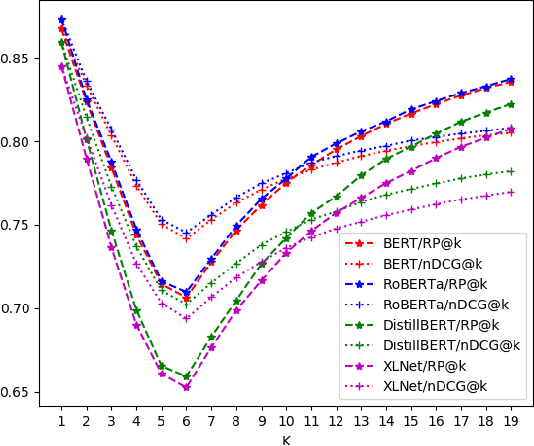
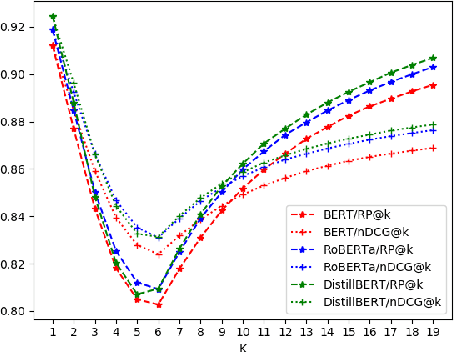
Large multi-label text classification is a challenging Natural Language Processing (NLP) problem that is concerned with text classification for datasets with thousands of labels. We tackle this problem in the legal domain, where datasets, such as JRC-Acquis and EURLEX57K labeled with the EuroVoc vocabulary were created within the legal information systems of the European Union. The EuroVoc taxonomy includes around 7000 concepts. In this work, we study the performance of various recent transformer-based models in combination with strategies such as generative pretraining, gradual unfreezing and discriminative learning rates in order to reach competitive classification performance, and present new state-of-the-art results of 0.661 (F1) for JRC-Acquis and 0.754 for EURLEX57K. Furthermore, we quantify the impact of individual steps, such as language model fine-tuning or gradual unfreezing in an ablation study, and provide reference dataset splits created with an iterative stratification algorithm.
Russian Natural Language Generation: Creation of a Language Modelling Dataset and Evaluation with Modern Neural Architectures
May 05, 2020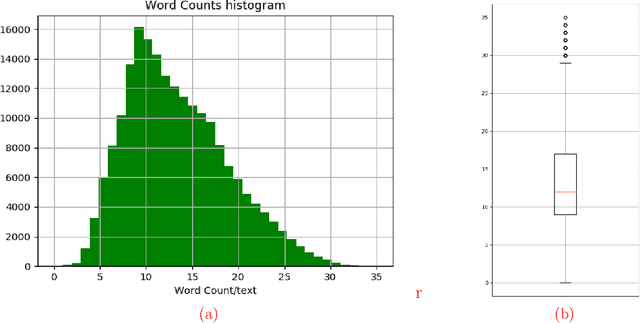
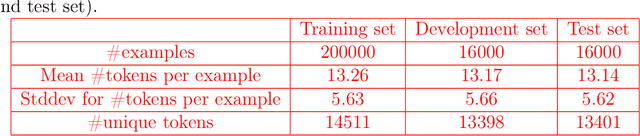


Generating coherent, grammatically correct, and meaningful text is very challenging, however, it is crucial to many modern NLP systems. So far, research has mostly focused on English language, for other languages both standardized datasets, as well as experiments with state-of-the-art models, are rare. In this work, we i) provide a novel reference dataset for Russian language modeling, ii) experiment with popular modern methods for text generation, namely variational autoencoders, and generative adversarial networks, which we trained on the new dataset. We evaluate the generated text regarding metrics such as perplexity, grammatical correctness and lexical diversity.
A Comparative Evaluation of Visual and Natural Language Question Answering Over Linked Data
Jul 19, 2019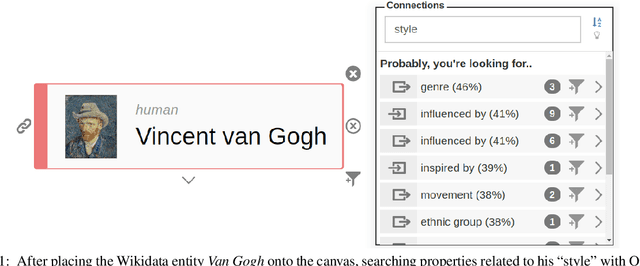


With the growing number and size of Linked Data datasets, it is crucial to make the data accessible and useful for users without knowledge of formal query languages. Two approaches towards this goal are knowledge graph visualization and natural language interfaces. Here, we investigate specifically question answering (QA) over Linked Data by comparing a diagrammatic visual approach with existing natural language-based systems. Given a QA benchmark (QALD7), we evaluate a visual method which is based on iteratively creating diagrams until the answer is found, against four QA systems that have natural language queries as input. Besides other benefits, the visual approach provides higher performance, but also requires more manual input. The results indicate that the methods can be used complementary, and that such a combination has a large positive impact on QA performance, and also facilitates additional features such as data exploration.
Word Similarity Datasets for Thai: Construction and Evaluation
Apr 08, 2019



Distributional semantics in the form of word embeddings are an essential ingredient to many modern natural language processing systems. The quantification of semantic similarity between words can be used to evaluate the ability of a system to perform semantic interpretation. To this end, a number of word similarity datasets have been created for the English language over the last decades. For Thai language few such resources are available. In this work, we create three Thai word similarity datasets by translating and re-rating the popular WordSim-353, SimLex-999 and SemEval-2017-Task-2 datasets. The three datasets contain 1852 word pairs in total and have different characteristics in terms of difficulty, domain coverage, and notion of similarity (relatedness vs.~similarity). These features help to gain a broader picture of the properties of an evaluated word embedding model. We include baseline evaluations with existing Thai embedding models, and identify the high ratio of out-of-vocabulary words as one of the biggest challenges. All datasets, evaluation results, and a tool for easy evaluation of new Thai embedding models are available to the NLP community online.
Creation and Evaluation of Datasets for Distributional Semantics Tasks in the Digital Humanities Domain
Mar 07, 2019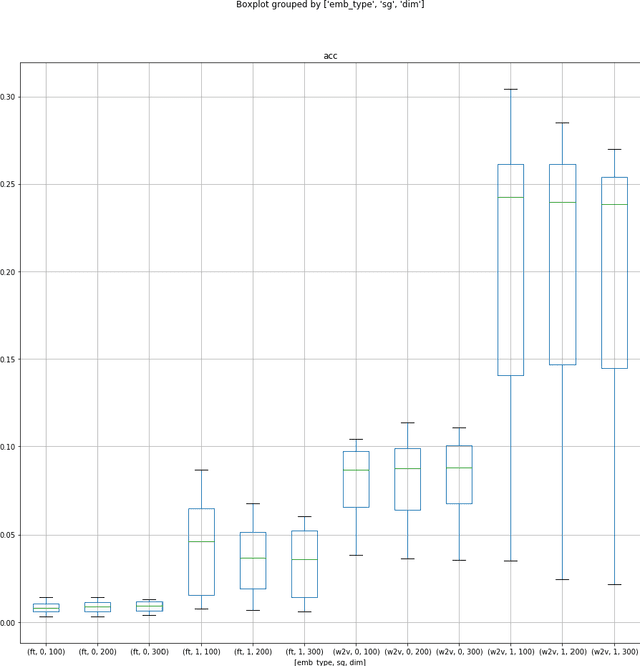

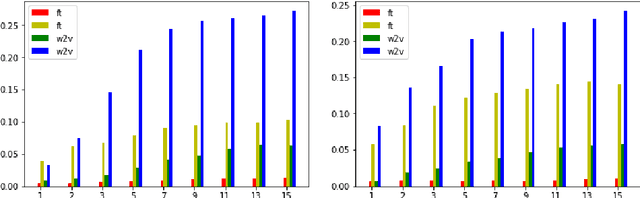
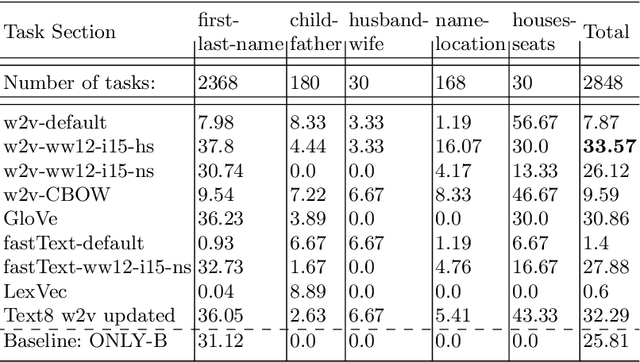
Word embeddings are already well studied in the general domain, usually trained on large text corpora, and have been evaluated for example on word similarity and analogy tasks, but also as an input to downstream NLP processes. In contrast, in this work we explore the suitability of word embedding technologies in the specialized digital humanities domain. After training embedding models of various types on two popular fantasy novel book series, we evaluate their performance on two task types: term analogies, and word intrusion. To this end, we manually construct test datasets with domain experts. Among the contributions are the evaluation of various word embedding techniques on the different task types, with the findings that even embeddings trained on small corpora perform well for example on the word intrusion task. Furthermore, we provide extensive and high-quality datasets in digital humanities for further investigation, as well as the implementation to easily reproduce or extend the experiments.
Relation Extraction Datasets in the Digital Humanities Domain and their Evaluation with Word Embeddings
Mar 04, 2019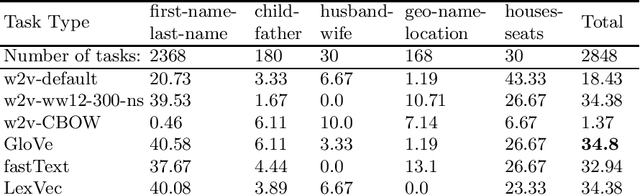
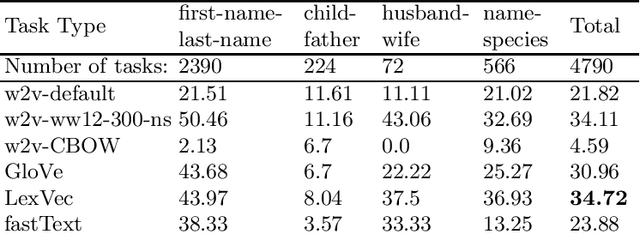
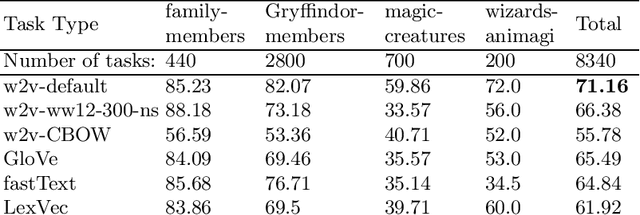
In this research, we manually create high-quality datasets in the digital humanities domain for the evaluation of language models, specifically word embedding models. The first step comprises the creation of unigram and n-gram datasets for two fantasy novel book series for two task types each, analogy and doesn't-match. This is followed by the training of models on the two book series with various popular word embedding model types such as word2vec, GloVe, fastText, or LexVec. Finally, we evaluate the suitability of word embedding models for such specific relation extraction tasks in a situation of comparably small corpus sizes. In the evaluations, we also investigate and analyze particular aspects such as the impact of corpus term frequencies and task difficulty on accuracy. The datasets, and the underlying system and word embedding models are available on github and can be easily extended with new datasets and tasks, be used to reproduce the presented results, or be transferred to other domains.
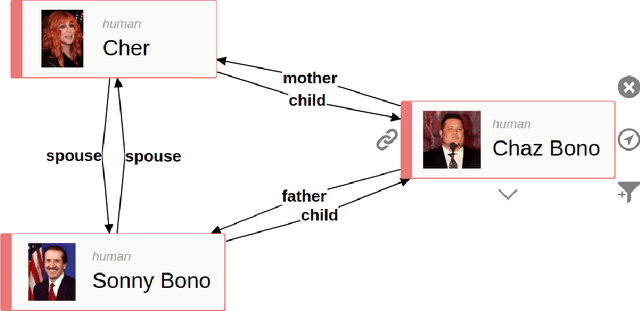
Using Word Embeddings for Visual Data Exploration with Ontodia and Wikidata
Mar 04, 2019
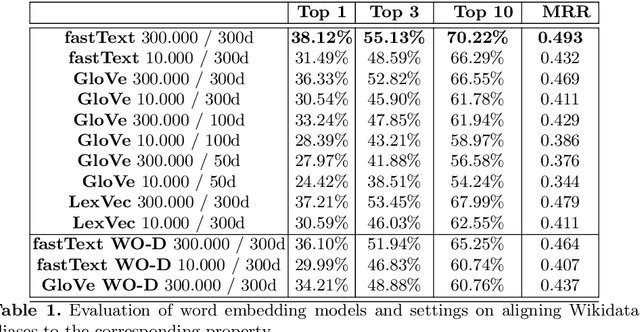
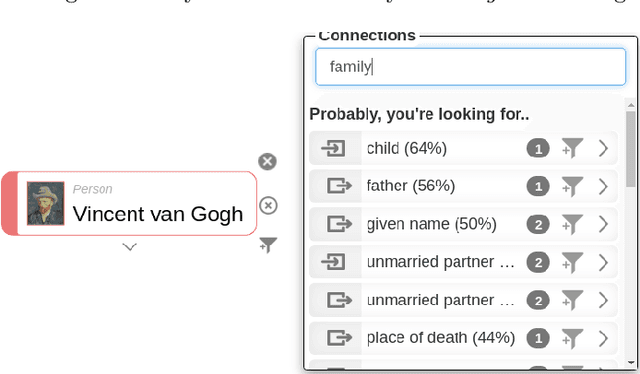

One of the big challenges in Linked Data consumption is to create visual and natural language interfaces to the data usable for non-technical users. Ontodia provides support for diagrammatic data exploration, showcased in this publication in combination with the Wikidata dataset. We present improvements to the natural language interface regarding exploring and querying Linked Data entities. The method uses models of distributional semantics to find and rank entity properties related to user input in Ontodia. Various word embedding types and model settings are evaluated, and the results show that user experience in visual data exploration benefits from the proposed approach.
Russian Language Datasets in the Digitial Humanities Domain and Their Evaluation with Word Embeddings
Mar 04, 2019
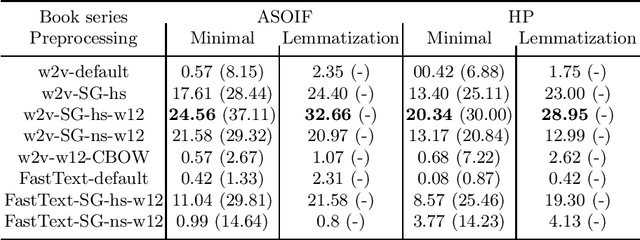


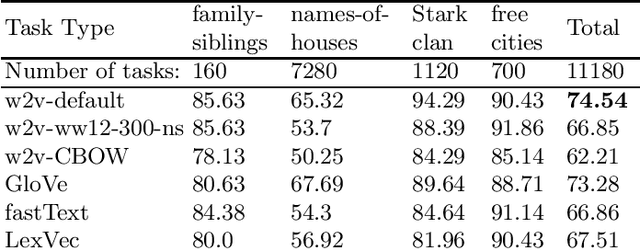
In this paper, we present Russian language datasets in the digital humanities domain for the evaluation of word embedding techniques or similar language modeling and feature learning algorithms. The datasets are split into two task types, word intrusion and word analogy, and contain 31362 task units in total. The characteristics of the tasks and datasets are that they build upon small, domain-specific corpora, and that the datasets contain a high number of named entities. The datasets were created manually for two fantasy novel book series ("A Song of Ice and Fire" and "Harry Potter"). We provide baseline evaluations with popular word embedding models trained on the book corpora for the given tasks, both for the Russian and English language versions of the datasets. Finally, we compare and analyze the results and discuss specifics of Russian language with regards to the problem setting.