 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdChecked: Detecting Previously Fact-Checked Claims in Social Media
Oct 10, 2022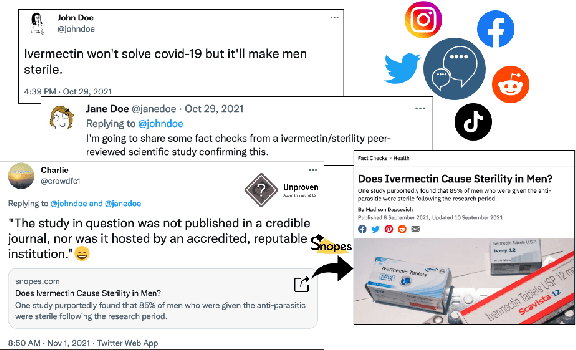
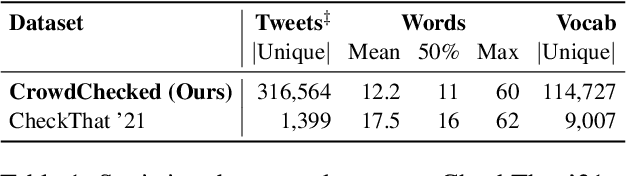
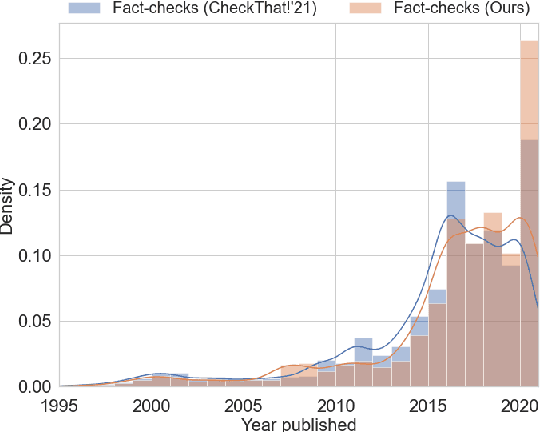
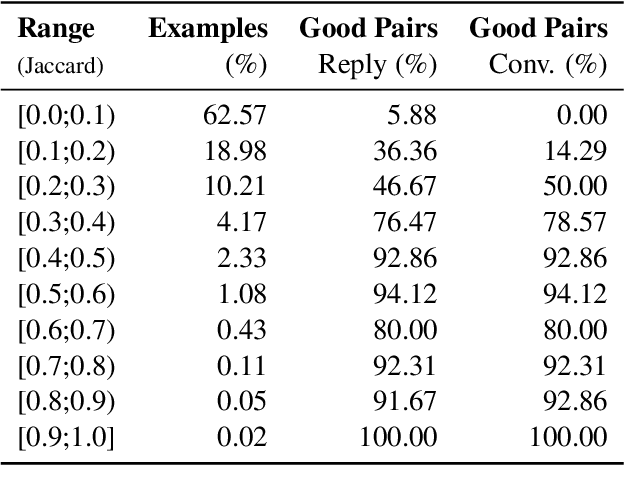
While there has been substantial progress in developing systems to automate fact-checking, they still lack credibility in the eyes of the users. Thus, an interesting approach has emerged: to perform automatic fact-checking by verifying whether an input claim has been previously fact-checked by professional fact-checkers and to return back an article that explains their decision. This is a sensible approach as people trust manual fact-checking, and as many claims are repeated multiple times. Yet, a major issue when building such systems is the small number of known tweet--verifying article pairs available for training. Here, we aim to bridge this gap by making use of crowd fact-checking, i.e., mining claims in social media for which users have responded with a link to a fact-checking article. In particular, we mine a large-scale collection of 330,000 tweets paired with a corresponding fact-checking article. We further propose an end-to-end framework to learn from this noisy data based on modified self-adaptive training, in a distant supervision scenario. Our experiments on the CLEF'21 CheckThat! test set show improvements over the state of the art by two points absolute. Our code and datasets are available at https://github.com/mhardalov/crowdchecked-claims
* Accepted to AACL-IJCNLP 2022 (Main Conference)
Batch-Softmax Contrastive Loss for Pairwise Sentence Scoring Tasks
Oct 10, 2021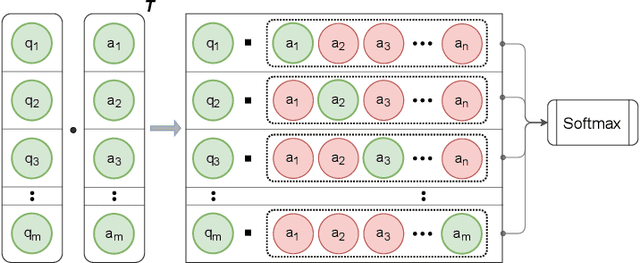
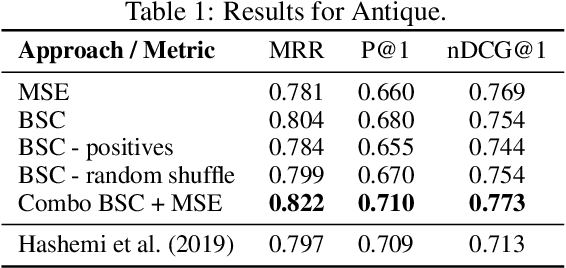
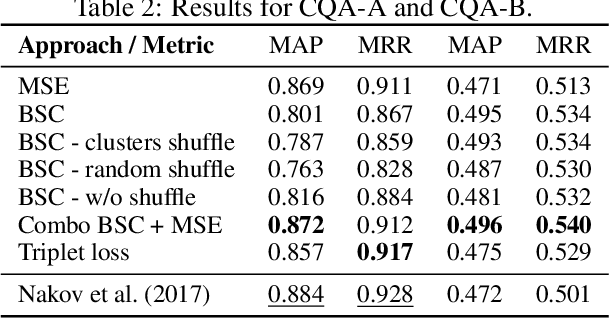
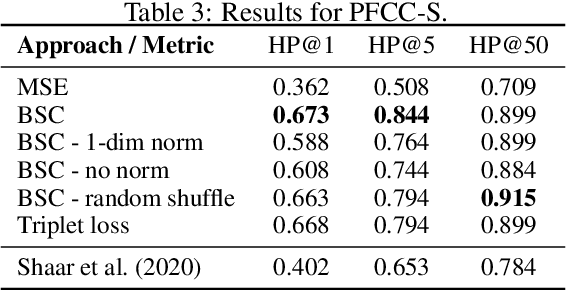
The use of contrastive loss for representation learning has become prominent in computer vision, and it is now getting attention in Natural Language Processing (NLP). Here, we explore the idea of using a batch-softmax contrastive loss when fine-tuning large-scale pre-trained transformer models to learn better task-specific sentence embeddings for pairwise sentence scoring tasks. We introduce and study a number of variations in the calculation of the loss as well as in the overall training procedure; in particular, we find that data shuffling can be quite important. Our experimental results show sizable improvements on a number of datasets and pairwise sentence scoring tasks including classification, ranking, and regression. Finally, we offer detailed analysis and discussion, which should be useful for researchers aiming to explore the utility of contrastive loss in NLP.
WhatTheWikiFact: Fact-Checking Claims Against Wikipedia
Apr 16, 2021
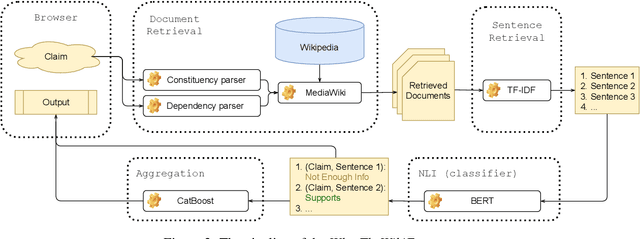
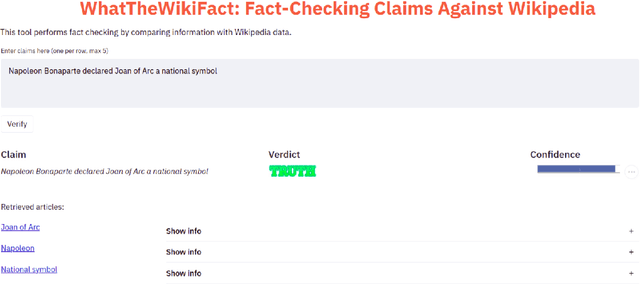
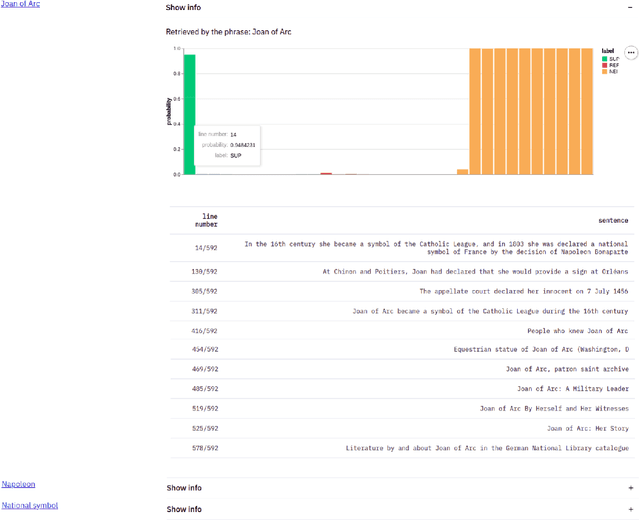
The rise of Internet has made it a major source of information. Unfortunately, not all information online is true, and thus a number of fact-checking initiatives have been launched, both manual and automatic. Here, we present our contribution in this regard: WhatTheWikiFact, a system for automatic claim verification using Wikipedia. The system predicts the veracity of an input claim, and it further shows the evidence it has retrieved as part of the verification process. It shows confidence scores and a list of relevant Wikipedia articles, together with detailed information about each article, including the phrase used to retrieve it, the most relevant sentences it contains, and their stances with respect to the input claim, with associated probabilities.
Transformers: "The End of History" for NLP?
Apr 09, 2021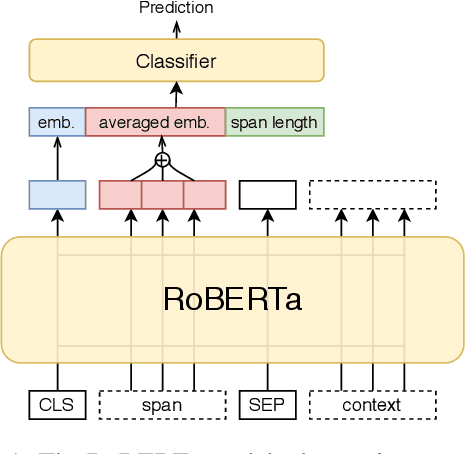
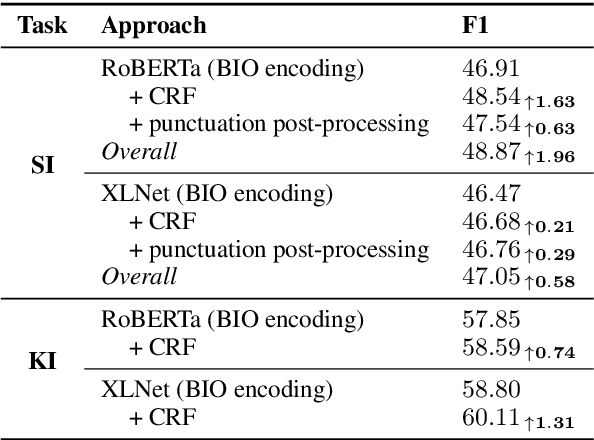

Recent advances in neural architectures, such as the Transformer, coupled with the emergence of large-scale pre-trained models such as BERT, have revolutionized the field of Natural Language Processing (NLP), pushing the state-of-the-art for a number of NLP tasks. A rich family of variations of these models has been proposed, such as RoBERTa, ALBERT, and XLNet, but fundamentally, they all remain limited in their ability to model certain kinds of information, and they cannot cope with certain information sources, which was easy for pre-existing models. Thus, here we aim to shed some light on some important theoretical limitations of pre-trained BERT-style models that are inherent in the general Transformer architecture. First, we demonstrate in practice on two general types of tasks -- segmentation and segment labeling -- and four datasets that these limitations are indeed harmful and that addressing them, even in some very simple and naive ways, can yield sizable improvements over vanilla RoBERTa and XLNet. Then, we offer a more general discussion on desiderata for future additions to the Transformer architecture that would increase its expressiveness, which we hope could help in the design of the next generation of deep NLP architectures.
aschern at SemEval-2020 Task 11: It Takes Three to Tango: RoBERTa, CRF, and Transfer Learning
Aug 06, 2020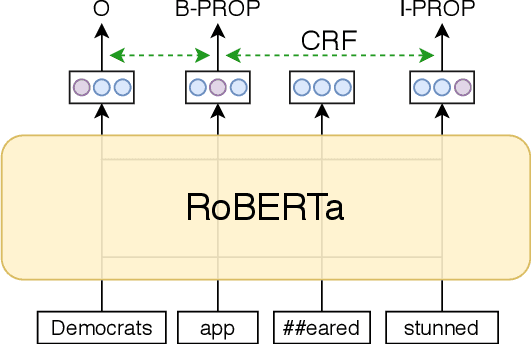

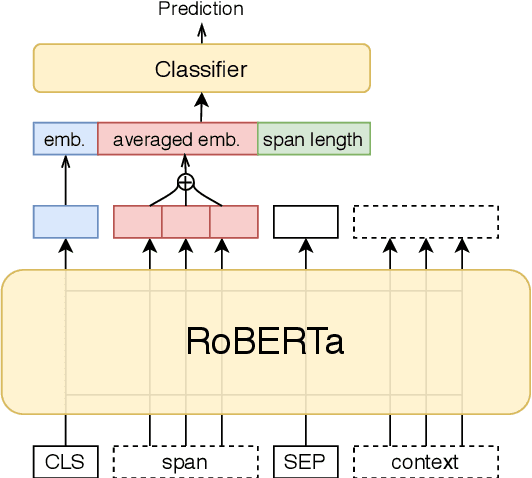
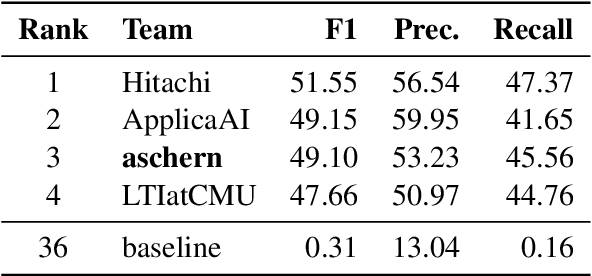
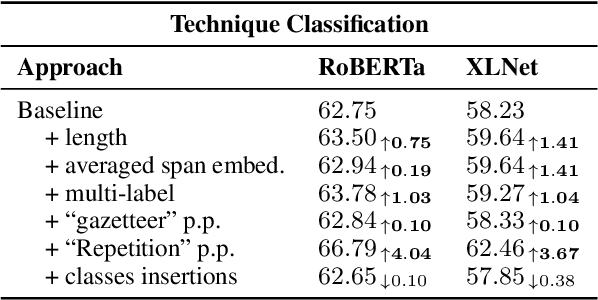
We describe our system for SemEval-2020 Task 11 on Detection of Propaganda Techniques in News Articles. We developed ensemble models using RoBERTa-based neural architectures, additional CRF layers, transfer learning between the two subtasks, and advanced post-processing to handle the multi-label nature of the task, the consistency between nested spans, repetitions, and labels from similar spans in training. We achieved sizable improvements over baseline fine-tuned RoBERTa models, and the official evaluation ranked our system 3rd (almost tied with the 2nd) out of 36 teams on the span identification subtask with an F1 score of 0.491, and 2nd (almost tied with the 1st) out of 31 teams on the technique classification subtask with an F1 score of 0.62.
* propaganda, persuasion, disinformation, fake news
Creation and Evaluation of Datasets for Distributional Semantics Tasks in the Digital Humanities Domain
Mar 07, 2019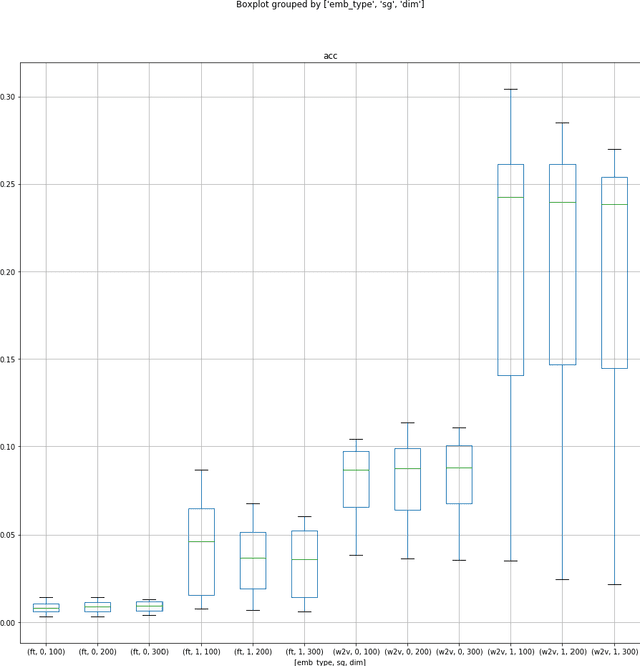

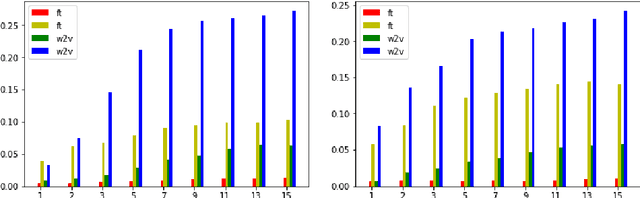
Word embeddings are already well studied in the general domain, usually trained on large text corpora, and have been evaluated for example on word similarity and analogy tasks, but also as an input to downstream NLP processes. In contrast, in this work we explore the suitability of word embedding technologies in the specialized digital humanities domain. After training embedding models of various types on two popular fantasy novel book series, we evaluate their performance on two task types: term analogies, and word intrusion. To this end, we manually construct test datasets with domain experts. Among the contributions are the evaluation of various word embedding techniques on the different task types, with the findings that even embeddings trained on small corpora perform well for example on the word intrusion task. Furthermore, we provide extensive and high-quality datasets in digital humanities for further investigation, as well as the implementation to easily reproduce or extend the experiments.
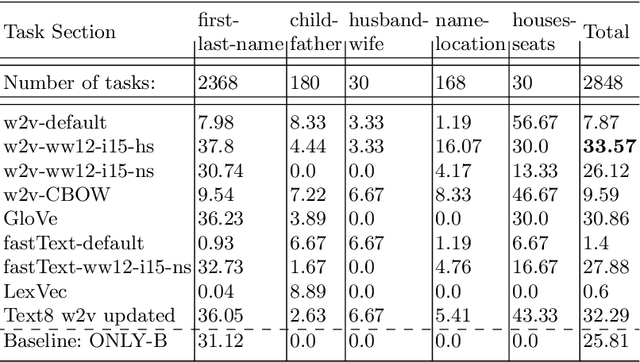
Relation Extraction Datasets in the Digital Humanities Domain and their Evaluation with Word Embeddings
Mar 04, 2019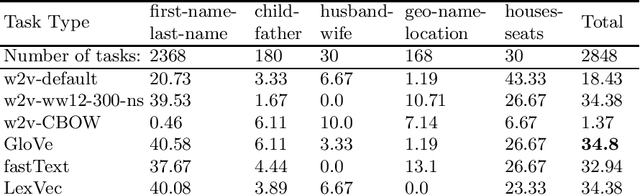
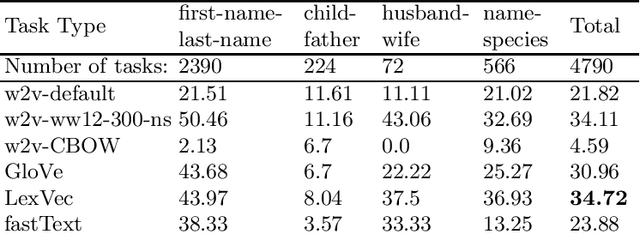
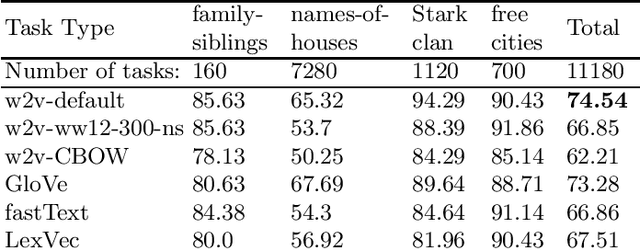
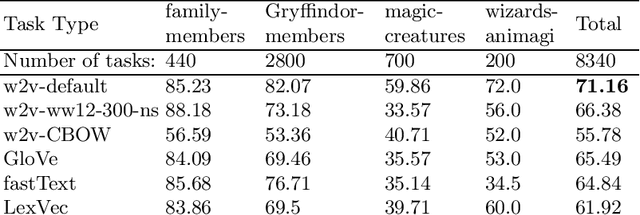
In this research, we manually create high-quality datasets in the digital humanities domain for the evaluation of language models, specifically word embedding models. The first step comprises the creation of unigram and n-gram datasets for two fantasy novel book series for two task types each, analogy and doesn't-match. This is followed by the training of models on the two book series with various popular word embedding model types such as word2vec, GloVe, fastText, or LexVec. Finally, we evaluate the suitability of word embedding models for such specific relation extraction tasks in a situation of comparably small corpus sizes. In the evaluations, we also investigate and analyze particular aspects such as the impact of corpus term frequencies and task difficulty on accuracy. The datasets, and the underlying system and word embedding models are available on github and can be easily extended with new datasets and tasks, be used to reproduce the presented results, or be transferred to other domains.