 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Word Stress Detection in Russian
Jul 12, 2019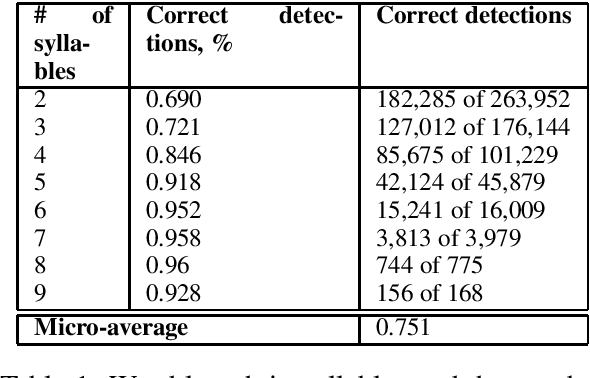
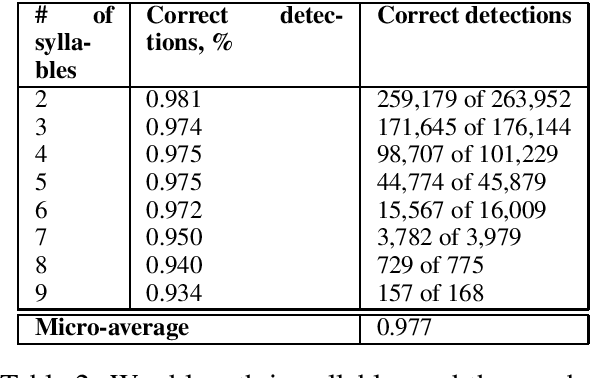
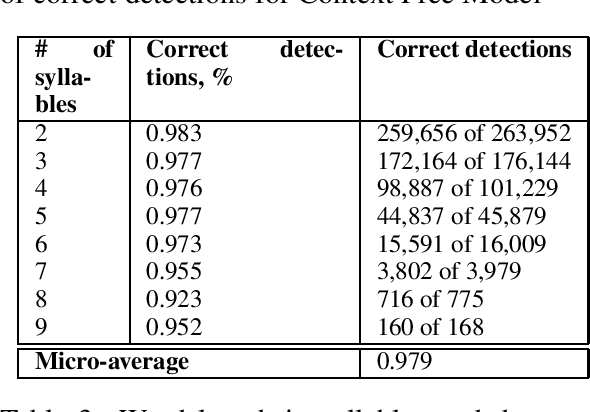
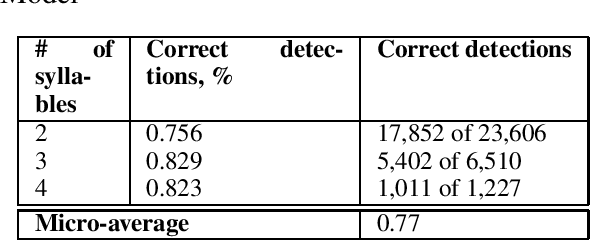
In this study we address the problem of automated word stress detection in Russian using character level models and no part-speech-taggers. We use a simple bidirectional RNN with LSTM nodes and achieve the accuracy of 90% or higher. We experiment with two training datasets and show that using the data from an annotated corpus is much more efficient than using a dictionary, since it allows us to take into account word frequencies and the morphological context of the word.
* SCLeM 2017
Char-RNN for Word Stress Detection in East Slavic Languages
Jun 10, 2019

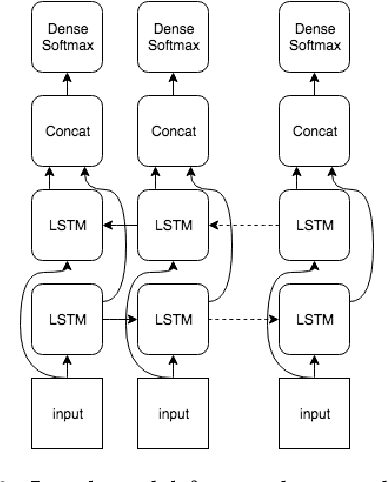
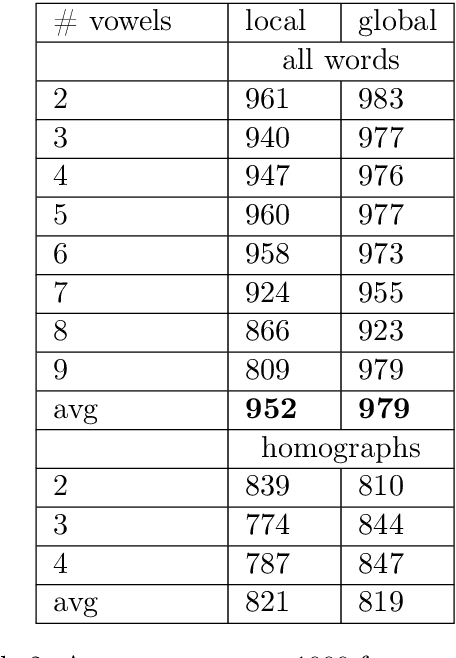
We explore how well a sequence labeling approach, namely, recurrent neural network, is suited for the task of resource-poor and POS tagging free word stress detection in the Russian, Ukranian, Belarusian languages. We present new datasets, annotated with the word stress, for the three languages and compare several RNN models trained on three languages and explore possible applications of the transfer learning for the task. We show that it is possible to train a model in a cross-lingual setting and that using additional languages improves the quality of the results.
* Proceedings of the Sixth Workshop on NLP for Similar Languages, Varieties and Dialects at NAACL-2019
Creation and Evaluation of Datasets for Distributional Semantics Tasks in the Digital Humanities Domain
Mar 07, 2019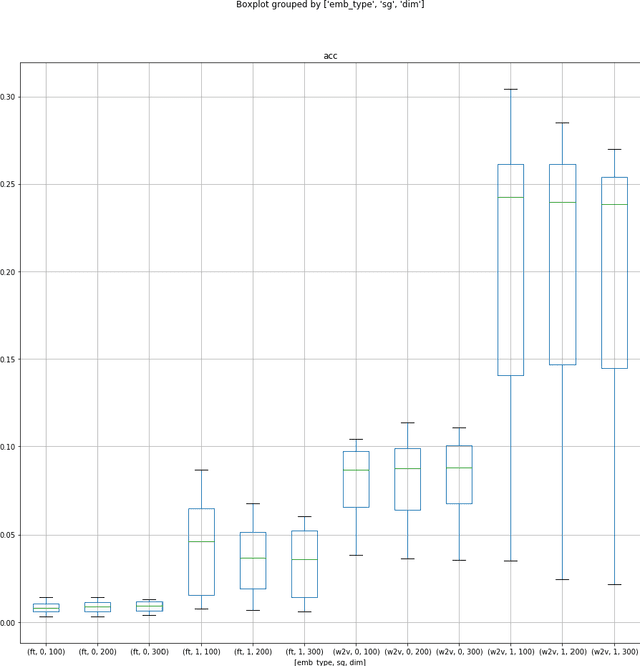

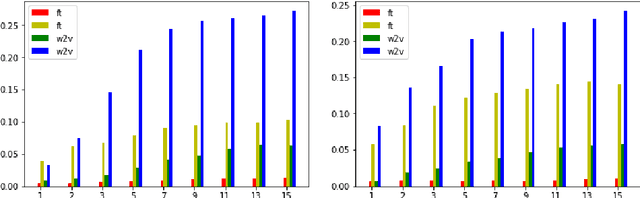
Word embeddings are already well studied in the general domain, usually trained on large text corpora, and have been evaluated for example on word similarity and analogy tasks, but also as an input to downstream NLP processes. In contrast, in this work we explore the suitability of word embedding technologies in the specialized digital humanities domain. After training embedding models of various types on two popular fantasy novel book series, we evaluate their performance on two task types: term analogies, and word intrusion. To this end, we manually construct test datasets with domain experts. Among the contributions are the evaluation of various word embedding techniques on the different task types, with the findings that even embeddings trained on small corpora perform well for example on the word intrusion task. Furthermore, we provide extensive and high-quality datasets in digital humanities for further investigation, as well as the implementation to easily reproduce or extend the experiments.
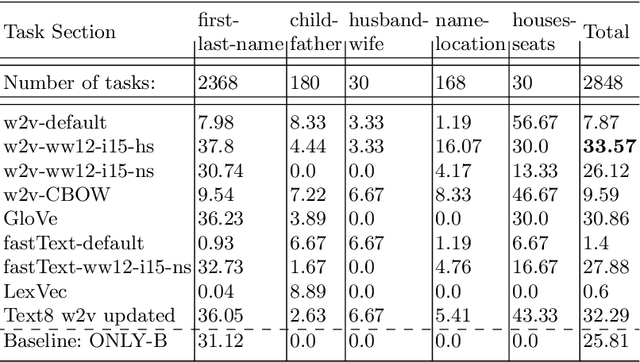
Relation Extraction Datasets in the Digital Humanities Domain and their Evaluation with Word Embeddings
Mar 04, 2019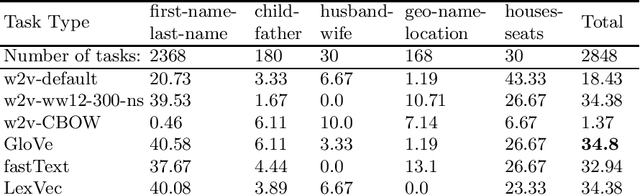
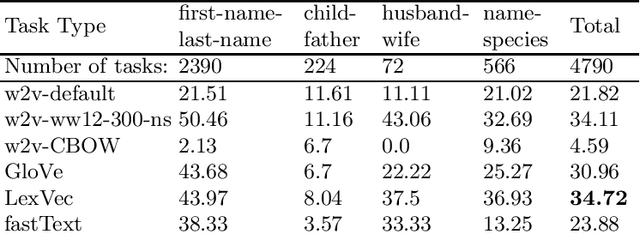
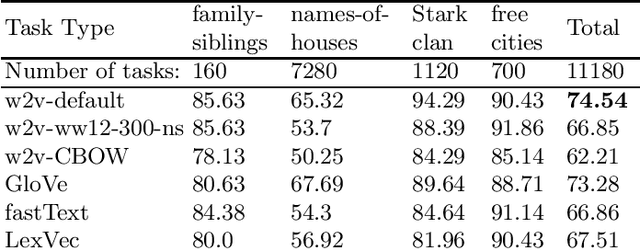
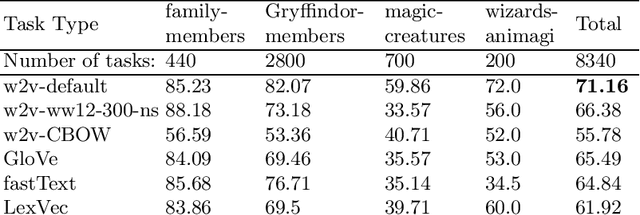
In this research, we manually create high-quality datasets in the digital humanities domain for the evaluation of language models, specifically word embedding models. The first step comprises the creation of unigram and n-gram datasets for two fantasy novel book series for two task types each, analogy and doesn't-match. This is followed by the training of models on the two book series with various popular word embedding model types such as word2vec, GloVe, fastText, or LexVec. Finally, we evaluate the suitability of word embedding models for such specific relation extraction tasks in a situation of comparably small corpus sizes. In the evaluations, we also investigate and analyze particular aspects such as the impact of corpus term frequencies and task difficulty on accuracy. The datasets, and the underlying system and word embedding models are available on github and can be easily extended with new datasets and tasks, be used to reproduce the presented results, or be transferred to other domains.