Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Word Stress Detection in Russian
Paper and Code
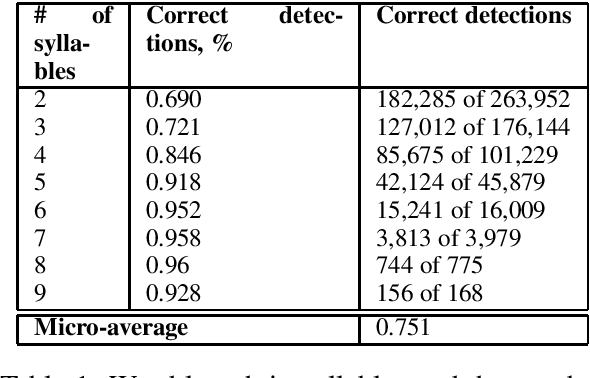
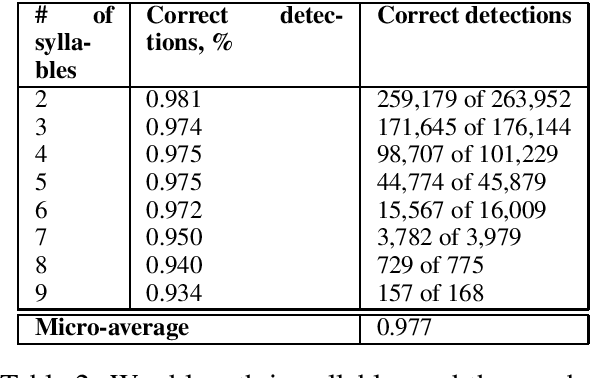
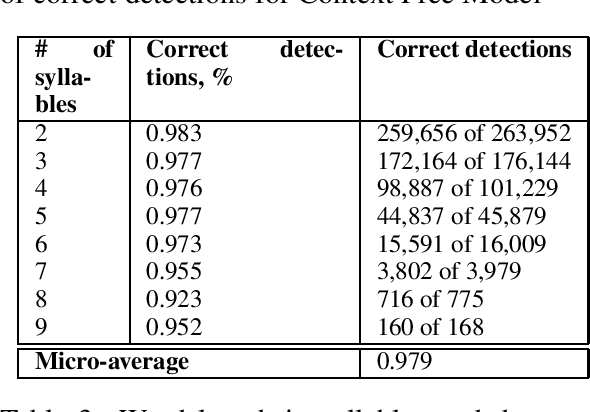
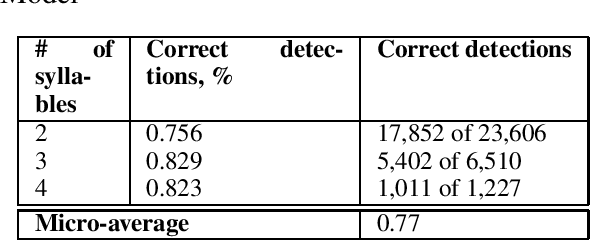
In this study we address the problem of automated word stress detection in Russian using character level models and no part-speech-taggers. We use a simple bidirectional RNN with LSTM nodes and achieve the accuracy of 90% or higher. We experiment with two training datasets and show that using the data from an annotated corpus is much more efficient than using a dictionary, since it allows us to take into account word frequencies and the morphological context of the word.
* Published in Proceedings of the First Workshop on Subword and
Character Level Models in NLP, pages 31 35, Copenhagen, Denmark, September 7,
2017 * SCLeM 2017
View paper on