 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRussian Language Datasets in the Digitial Humanities Domain and Their Evaluation with Word Embeddings
Mar 04, 2019
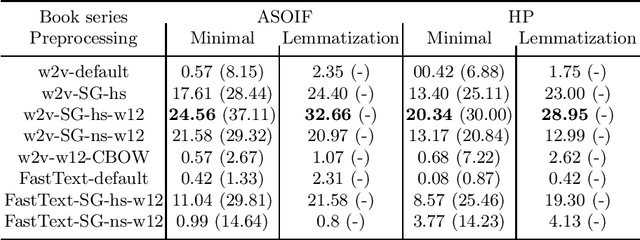


In this paper, we present Russian language datasets in the digital humanities domain for the evaluation of word embedding techniques or similar language modeling and feature learning algorithms. The datasets are split into two task types, word intrusion and word analogy, and contain 31362 task units in total. The characteristics of the tasks and datasets are that they build upon small, domain-specific corpora, and that the datasets contain a high number of named entities. The datasets were created manually for two fantasy novel book series ("A Song of Ice and Fire" and "Harry Potter"). We provide baseline evaluations with popular word embedding models trained on the book corpora for the given tasks, both for the Russian and English language versions of the datasets. Finally, we compare and analyze the results and discuss specifics of Russian language with regards to the problem setting.