 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAVER: Curious Audiovisual Exploring Robot
Nov 10, 2025Multimodal audiovisual perception can enable new avenues for robotic manipulation, from better material classification to the imitation of demonstrations for which only audio signals are available (e.g., playing a tune by ear). However, to unlock such multimodal potential, robots need to learn the correlations between an object's visual appearance and the sound it generates when they interact with it. Such an active sensorimotor experience requires new interaction capabilities, representations, and exploration methods to guide the robot in efficiently building increasingly rich audiovisual knowledge. In this work, we present CAVER, a novel robot that builds and utilizes rich audiovisual representations of objects. CAVER includes three novel contributions: 1) a novel 3D printed end-effector, attachable to parallel grippers, that excites objects' audio responses, 2) an audiovisual representation that combines local and global appearance information with sound features, and 3) an exploration algorithm that uses and builds the audiovisual representation in a curiosity-driven manner that prioritizes interacting with high uncertainty objects to obtain good coverage of surprising audio with fewer interactions. We demonstrate that CAVER builds rich representations in different scenarios more efficiently than several exploration baselines, and that the learned audiovisual representation leads to significant improvements in material classification and the imitation of audio-only human demonstrations. https://caver-bot.github.io/
Mixed-Initiative Dialog for Human-Robot Collaborative Manipulation
Aug 07, 2025Effective robotic systems for long-horizon human-robot collaboration must adapt to a wide range of human partners, whose physical behavior, willingness to assist, and understanding of the robot's capabilities may change over time. This demands a tightly coupled communication loop that grants both agents the flexibility to propose, accept, or decline requests as they coordinate toward completing the task effectively. We apply a Mixed-Initiative dialog paradigm to Collaborative human-roBot teaming and propose MICoBot, a system that handles the common scenario where both agents, using natural language, take initiative in formulating, accepting, or rejecting proposals on who can best complete different steps of a task. To handle diverse, task-directed dialog, and find successful collaborative strategies that minimize human effort, MICoBot makes decisions at three levels: (1) a meta-planner considers human dialog to formulate and code a high-level collaboration strategy, (2) a planner optimally allocates the remaining steps to either agent based on the robot's capabilities (measured by a simulation-pretrained affordance model) and the human's estimated availability to help, and (3) an action executor decides the low-level actions to perform or words to say to the human. Our extensive evaluations in simulation and real-world -- on a physical robot with 18 unique human participants over 27 hours -- demonstrate the ability of our method to effectively collaborate with diverse human users, yielding significantly improved task success and user experience than a pure LLM baseline and other agent allocation models. See additional videos and materials at https://robin-lab.cs.utexas.edu/MicoBot/.
Why Automate This? Exploring the Connection between Time Use, Well-being and Robot Automation Across Social Groups
Jan 10, 2025

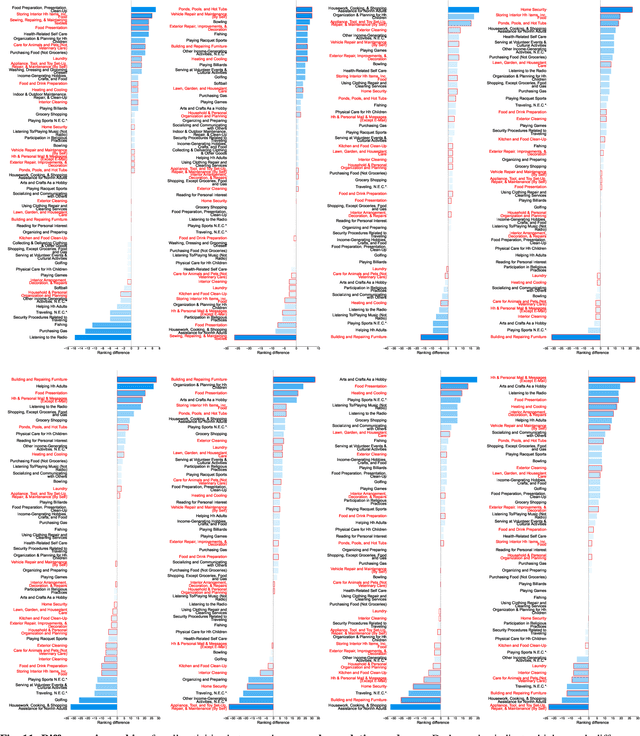
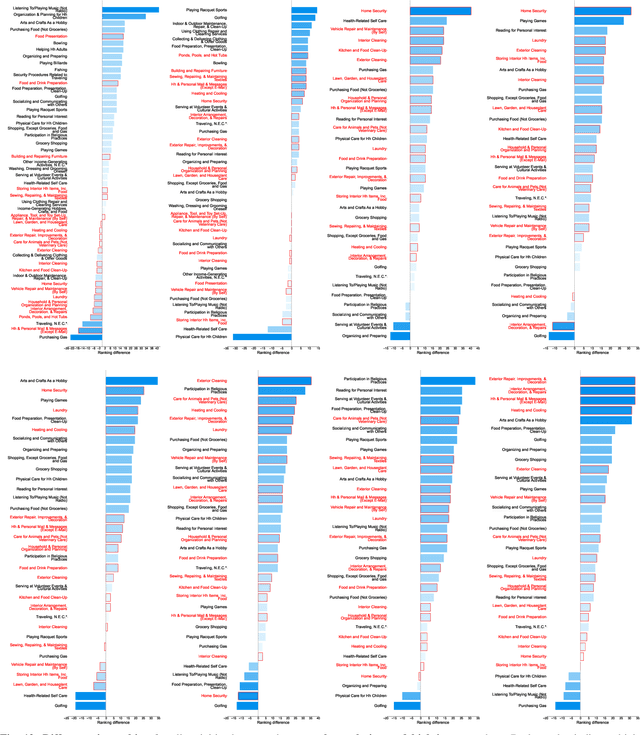
Understanding the motivations underlying the human inclination to automate tasks is vital to developing truly helpful robots integrated into daily life. Accordingly, we ask: are individuals more inclined to automate chores based on the time they consume or the feelings experienced while performing them? This study explores these preferences and whether they vary across different social groups (i.e., gender category and income level). Leveraging data from the BEHAVIOR-1K dataset, the American Time-Use Survey, and the American Time-Use Survey Well-Being Module, we investigate the relationship between the desire for automation, time spent on daily activities, and their associated feelings - Happiness, Meaningfulness, Sadness, Painfulness, Stressfulness, or Tiredness. Our key findings show that, despite common assumptions, time spent does not strongly relate to the desire for automation for the general population. For the feelings analyzed, only happiness and pain are key indicators. Significant differences by gender and economic level also emerged: Women prefer to automate stressful activities, whereas men prefer to automate those that make them unhappy; mid-income individuals prioritize automating less enjoyable and meaningful activities, while low and high-income show no significant correlations. We hope our research helps motivate technologies to develop robots that match the priorities of potential users, moving domestic robotics toward more socially relevant solutions. We open-source all the data, including an online tool that enables the community to replicate our analysis and explore additional trends at https://hri1260.github.io/why-automate-this.
Mitigating Exaggerated Safety in Large Language Models
May 08, 2024


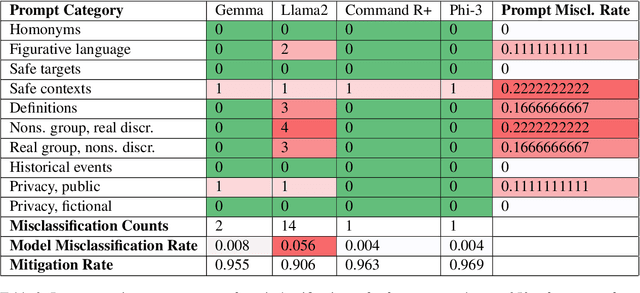
As the popularity of Large Language Models (LLMs) grow, combining model safety with utility becomes increasingly important. The challenge is making sure that LLMs can recognize and decline dangerous prompts without sacrificing their ability to be helpful. The problem of "exaggerated safety" demonstrates how difficult this can be. To reduce excessive safety behaviours -- which was discovered to be 26.1% of safe prompts being misclassified as dangerous and refused -- we use a combination of XSTest dataset prompts as well as interactive, contextual, and few-shot prompting to examine the decision bounds of LLMs such as Llama2, Gemma Command R+, and Phi-3. We find that few-shot prompting works best for Llama2, interactive prompting works best Gemma, and contextual prompting works best for Command R+ and Phi-3. Using a combination of these prompting strategies, we are able to mitigate exaggerated safety behaviors by an overall 92.9% across all LLMs. Our work presents a multiple prompting strategies to jailbreak LLMs' decision-making processes, allowing them to navigate the tight line between refusing unsafe prompts and remaining helpful.
Controlled Training Data Generation with Diffusion Models
Mar 22, 2024In this work, we present a method to control a text-to-image generative model to produce training data specifically "useful" for supervised learning. Unlike previous works that employ an open-loop approach and pre-define prompts to generate new data using either a language model or human expertise, we develop an automated closed-loop system which involves two feedback mechanisms. The first mechanism uses feedback from a given supervised model and finds adversarial prompts that result in image generations that maximize the model loss. While these adversarial prompts result in diverse data informed by the model, they are not informed of the target distribution, which can be inefficient. Therefore, we introduce the second feedback mechanism that guides the generation process towards a certain target distribution. We call the method combining these two mechanisms Guided Adversarial Prompts. We perform our evaluations on different tasks, datasets and architectures, with different types of distribution shifts (spuriously correlated data, unseen domains) and demonstrate the efficiency of the proposed feedback mechanisms compared to open-loop approaches.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
A Comparison of Speech Data Augmentation Methods Using S3PRL Toolkit
Feb 27, 2023



Data augmentations are known to improve robustness in speech-processing tasks. In this study, we summarize and compare different data augmentation strategies using S3PRL toolkit. We explore how HuBERT and wav2vec perform using different augmentation techniques (SpecAugment, Gaussian Noise, Speed Perturbation) for Phoneme Recognition (PR) and Automatic Speech Recognition (ASR) tasks. We evaluate model performance in terms of phoneme error rate (PER) and word error rate (WER). From the experiments, we observed that SpecAugment slightly improves the performance of HuBERT and wav2vec on the original dataset. Also, we show that models trained using the Gaussian Noise and Speed Perturbation dataset are more robust when tested with augmented test sets.