 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLAF: A Plug-and-Play Framework for Enhanced Multi-object Multi-part Scene Parsing
Nov 05, 2024Multi-object multi-part scene segmentation is a challenging task whose complexity scales exponentially with part granularity and number of scene objects. To address the task, we propose a plug-and-play approach termed OLAF. First, we augment the input (RGB) with channels containing object-based structural cues (fg/bg mask, boundary edge mask). We propose a weight adaptation technique which enables regular (RGB) pre-trained models to process the augmented (5-channel) input in a stable manner during optimization. In addition, we introduce an encoder module termed LDF to provide low-level dense feature guidance. This assists segmentation, particularly for smaller parts. OLAF enables significant mIoU gains of $\mathbf{3.3}$ (Pascal-Parts-58), $\mathbf{3.5}$ (Pascal-Parts-108) over the SOTA model. On the most challenging variant (Pascal-Parts-201), the gain is $\mathbf{4.0}$. Experimentally, we show that OLAF's broad applicability enables gains across multiple architectures (CNN, U-Net, Transformer) and datasets. The code is available at olafseg.github.io
Solving Vision Tasks with Simple Photoreceptors Instead of Cameras
Jun 17, 2024A de facto standard in solving computer vision problems is to use a common high-resolution camera and choose its placement on an agent (i.e., position and orientation) based on human intuition. On the other hand, extremely simple and well-designed visual sensors found throughout nature allow many organisms to perform diverse, complex behaviors. In this work, motivated by these examples, we raise the following questions: 1. How effective simple visual sensors are in solving vision tasks? 2. What role does their design play in their effectiveness? We explore simple sensors with resolutions as low as one-by-one pixel, representing a single photoreceptor First, we demonstrate that just a few photoreceptors can be enough to solve many tasks, such as visual navigation and continuous control, reasonably well, with performance comparable to that of a high-resolution camera. Second, we show that the design of these simple visual sensors plays a crucial role in their ability to provide useful information and successfully solve these tasks. To find a well-performing design, we present a computational design optimization algorithm and evaluate its effectiveness across different tasks and domains, showing promising results. Finally, we perform a human survey to evaluate the effectiveness of intuitive designs devised manually by humans, showing that the computationally found design is among the best designs in most cases.
Robustifying Deep Vision Models Through Shape Sensitization
Nov 14, 2022Recent work has shown that deep vision models tend to be overly dependent on low-level or "texture" features, leading to poor generalization. Various data augmentation strategies have been proposed to overcome this so-called texture bias in DNNs. We propose a simple, lightweight adversarial augmentation technique that explicitly incentivizes the network to learn holistic shapes for accurate prediction in an object classification setting. Our augmentations superpose edgemaps from one image onto another image with shuffled patches, using a randomly determined mixing proportion, with the image label of the edgemap image. To classify these augmented images, the model needs to not only detect and focus on edges but distinguish between relevant and spurious edges. We show that our augmentations significantly improve classification accuracy and robustness measures on a range of datasets and neural architectures. As an example, for ViT-S, We obtain absolute gains on classification accuracy gains up to 6%. We also obtain gains of up to 28% and 8.5% on natural adversarial and out-of-distribution datasets like ImageNet-A (for ViT-B) and ImageNet-R (for ViT-S), respectively. Analysis using a range of probe datasets shows substantially increased shape sensitivity in our trained models, explaining the observed improvement in robustness and classification accuracy.
FLOAT: Factorized Learning of Object Attributes for Improved Multi-object Multi-part Scene Parsing
Mar 30, 2022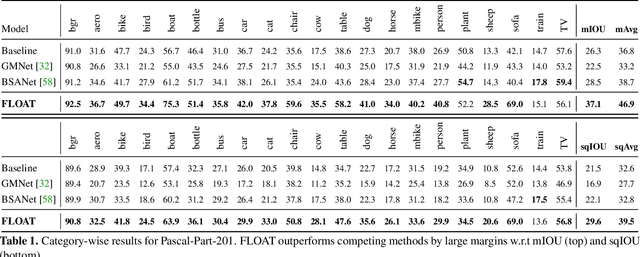
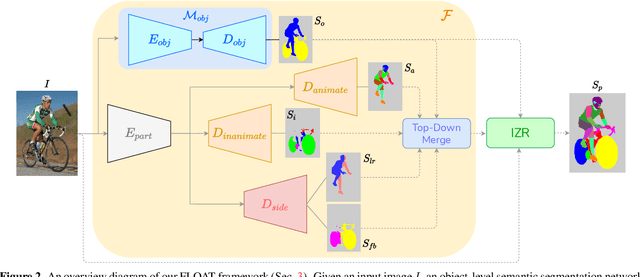
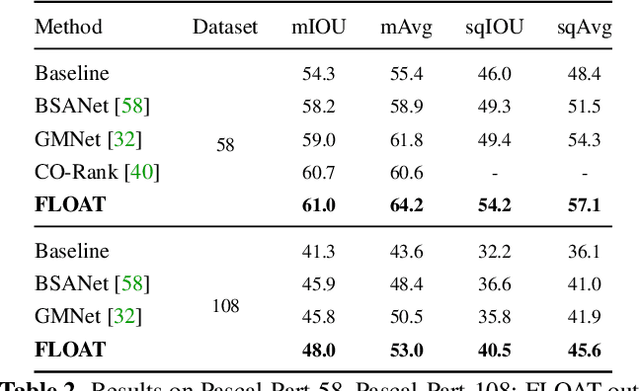
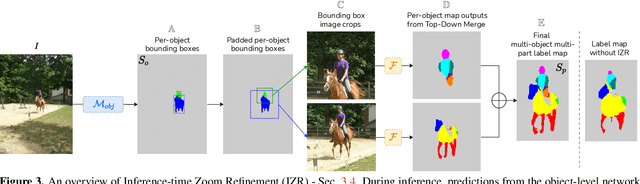
Multi-object multi-part scene parsing is a challenging task which requires detecting multiple object classes in a scene and segmenting the semantic parts within each object. In this paper, we propose FLOAT, a factorized label space framework for scalable multi-object multi-part parsing. Our framework involves independent dense prediction of object category and part attributes which increases scalability and reduces task complexity compared to the monolithic label space counterpart. In addition, we propose an inference-time 'zoom' refinement technique which significantly improves segmentation quality, especially for smaller objects/parts. Compared to state of the art, FLOAT obtains an absolute improvement of 2.0% for mean IOU (mIOU) and 4.8% for segmentation quality IOU (sqIOU) on the Pascal-Part-58 dataset. For the larger Pascal-Part-108 dataset, the improvements are 2.1% for mIOU and 3.9% for sqIOU. We incorporate previously excluded part attributes and other minor parts of the Pascal-Part dataset to create the most comprehensive and challenging version which we dub Pascal-Part-201. FLOAT obtains improvements of 8.6% for mIOU and 7.5% for sqIOU on the new dataset, demonstrating its parsing effectiveness across a challenging diversity of objects and parts. The code and datasets are available at floatseg.github.io.
How much complexity does an RNN architecture need to learn syntax-sensitive dependencies?
May 25, 2020


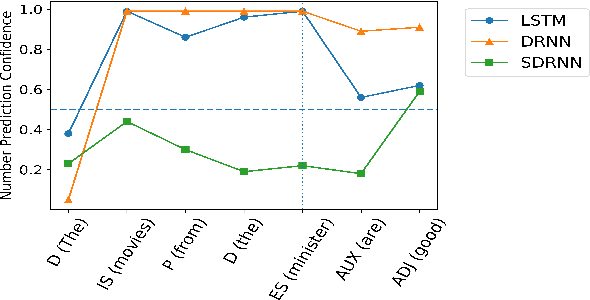
Long short-term memory (LSTM) networks and their variants are capable of encapsulating long-range dependencies, which is evident from their performance on a variety of linguistic tasks. On the other hand, simple recurrent networks (SRNs), which appear more biologically grounded in terms of synaptic connections, have generally been less successful at capturing long-range dependencies as well as the loci of grammatical errors in an unsupervised setting. In this paper, we seek to develop models that bridge the gap between biological plausibility and linguistic competence. We propose a new architecture, the Decay RNN, which incorporates the decaying nature of neuronal activations and models the excitatory and inhibitory connections in a population of neurons. Besides its biological inspiration, our model also shows competitive performance relative to LSTMs on subject-verb agreement, sentence grammaticality, and language modeling tasks. These results provide some pointers towards probing the nature of the inductive biases required for RNN architectures to model linguistic phenomena successfully.