 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Model Robustness across Concurrent Distribution Shifts
Jan 08, 2025


Machine learning models, meticulously optimized for source data, often fail to predict target data when faced with distribution shifts (DSs). Previous benchmarking studies, though extensive, have mainly focused on simple DSs. Recognizing that DSs often occur in more complex forms in real-world scenarios, we broadened our study to include multiple concurrent shifts, such as unseen domain shifts combined with spurious correlations. We evaluated 26 algorithms that range from simple heuristic augmentations to zero-shot inference using foundation models, across 168 source-target pairs from eight datasets. Our analysis of over 100K models reveals that (i) concurrent DSs typically worsen performance compared to a single shift, with certain exceptions, (ii) if a model improves generalization for one distribution shift, it tends to be effective for others, and (iii) heuristic data augmentations achieve the best overall performance on both synthetic and real-world datasets.
Self-Knowledge Distillation via Dropout
Aug 11, 2022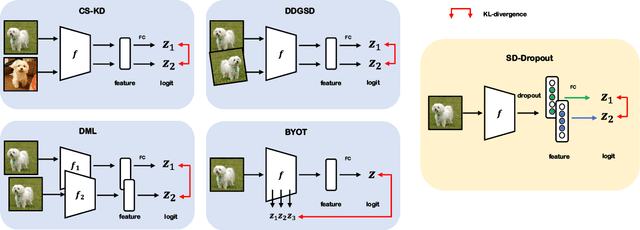
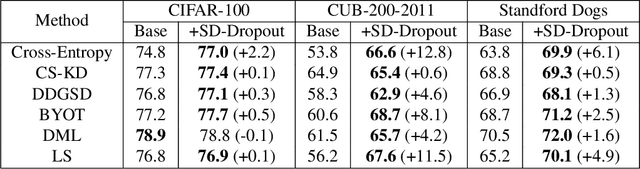
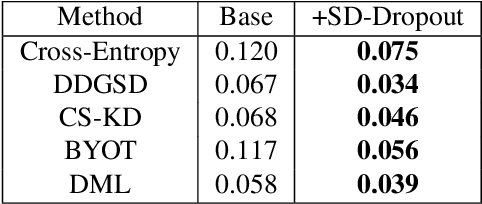

To boost the performance, deep neural networks require deeper or wider network structures that involve massive computational and memory costs. To alleviate this issue, the self-knowledge distillation method regularizes the model by distilling the internal knowledge of the model itself. Conventional self-knowledge distillation methods require additional trainable parameters or are dependent on the data. In this paper, we propose a simple and effective self-knowledge distillation method using a dropout (SD-Dropout). SD-Dropout distills the posterior distributions of multiple models through a dropout sampling. Our method does not require any additional trainable modules, does not rely on data, and requires only simple operations. Furthermore, this simple method can be easily combined with various self-knowledge distillation approaches. We provide a theoretical and experimental analysis of the effect of forward and reverse KL-divergences in our work. Extensive experiments on various vision tasks, i.e., image classification, object detection, and distribution shift, demonstrate that the proposed method can effectively improve the generalization of a single network. Further experiments show that the proposed method also improves calibration performance, adversarial robustness, and out-of-distribution detection ability.