 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Knowledge Distillation via Dropout
Aug 11, 2022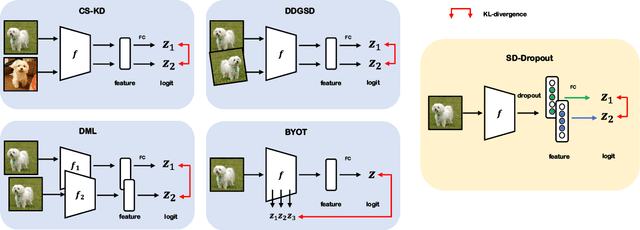
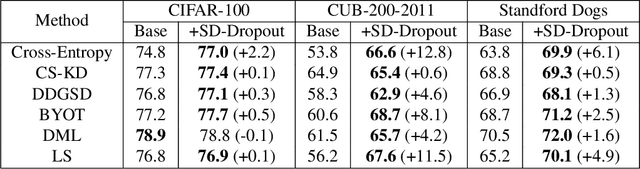
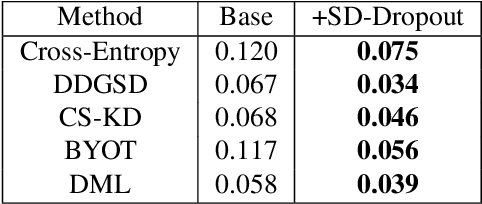

To boost the performance, deep neural networks require deeper or wider network structures that involve massive computational and memory costs. To alleviate this issue, the self-knowledge distillation method regularizes the model by distilling the internal knowledge of the model itself. Conventional self-knowledge distillation methods require additional trainable parameters or are dependent on the data. In this paper, we propose a simple and effective self-knowledge distillation method using a dropout (SD-Dropout). SD-Dropout distills the posterior distributions of multiple models through a dropout sampling. Our method does not require any additional trainable modules, does not rely on data, and requires only simple operations. Furthermore, this simple method can be easily combined with various self-knowledge distillation approaches. We provide a theoretical and experimental analysis of the effect of forward and reverse KL-divergences in our work. Extensive experiments on various vision tasks, i.e., image classification, object detection, and distribution shift, demonstrate that the proposed method can effectively improve the generalization of a single network. Further experiments show that the proposed method also improves calibration performance, adversarial robustness, and out-of-distribution detection ability.
Attention routing between capsules
Aug 06, 2019



In this paper, we propose a new capsule network architecture called Attention Routing CapsuleNet (AR CapsNet). We replace the dynamic routing and squash activation function of the capsule network with dynamic routing (CapsuleNet) with the attention routing and capsule activation. The attention routing is a routing between capsules through an attention module. The attention routing is a fast forward-pass while keeping spatial information. On the other hand, the intuitive interpretation of the dynamic routing is finding a centroid of the prediction capsules. Thus, the squash activation function and its variant focus on preserving a vector orientation. However, the capsule activation focuses on performing a capsule-scale activation function. We evaluate our proposed model on the MNIST, affNIST, and CIFAR-10 classification tasks. The proposed model achieves higher accuracy with fewer parameters (x0.65 in the MNIST, x0.82 in the CIFAR-10) and less training time than CapsuleNet (x0.19 in the MNIST, x0.35 in the CIFAR-10). These results validate that designing a capsule-scale operation is a key factor to implement the capsule concept. Also, our experiment shows that our proposed model is transformation equivariant as CapsuleNet. As we perturb each element of the output capsule, the decoder attached to the output capsules shows global variations. Further experiments show that the difference in the capsule features caused by applying affine transformations on an input image is significantly aligned in one direction.