 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Vision is the Challenge for Visual Reasoning: A Benchmark for Visual Argument Understanding
Paper and Code
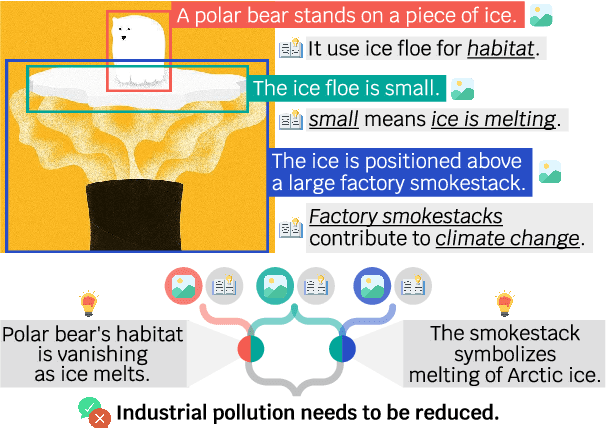
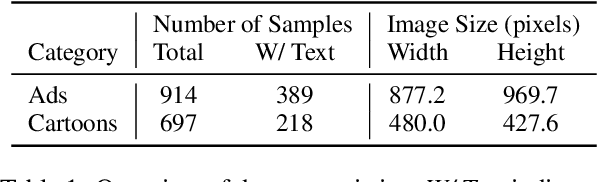


Visual arguments, often used in advertising or social causes, rely on images to persuade viewers to do or believe something. Understanding these arguments requires selective vision: only specific visual stimuli within an image are relevant to the argument, and relevance can only be understood within the context of a broader argumentative structure. While visual arguments are readily appreciated by human audiences, we ask: are today's AI capable of similar understanding? We collect and release VisArgs, an annotated corpus designed to make explicit the (usually implicit) structures underlying visual arguments. VisArgs includes 1,611 images accompanied by three types of textual annotations: 5,112 visual premises (with region annotations), 5,574 commonsense premises, and reasoning trees connecting them to a broader argument. We propose three tasks over VisArgs to probe machine capacity for visual argument understanding: localization of premises, identification of premises, and deduction of conclusions. Experiments demonstrate that 1) machines cannot fully identify the relevant visual cues. The top-performing model, GPT-4-O, achieved an accuracy of only 78.5%, whereas humans reached 98.0%. All models showed a performance drop, with an average decrease in accuracy of 19.5%, when the comparison set was changed from objects outside the image to irrelevant objects within the image. Furthermore, 2) this limitation is the greatest factor impacting their performance in understanding visual arguments. Most models improved the most when given relevant visual premises as additional inputs, compared to other inputs, for deducing the conclusion of the visual argument.