 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMol-LLM: Generalist Molecular LLM with Improved Graph Utilization
Feb 05, 2025



Recent advances in Large Language Models (LLMs) have motivated the development of general LLMs for molecular tasks. While several studies have demonstrated that fine-tuned LLMs can achieve impressive benchmark performances, they are far from genuine generalist molecular LLMs due to a lack of fundamental understanding of molecular structure. Specifically, when given molecular task instructions, LLMs trained with naive next-token prediction training assign similar likelihood scores to both original and negatively corrupted molecules, revealing their lack of molecular structure understanding that is crucial for reliable and general molecular LLMs. To overcome this limitation and obtain a true generalist molecular LLM, we introduce a novel multi-modal training method based on a thorough multi-modal instruction tuning as well as a molecular structure preference optimization between chosen and rejected graphs. On various molecular benchmarks, the proposed generalist molecular LLM, called Mol-LLM, achieves state-of-the-art performances among generalist LLMs on most tasks, at the same time, surpassing or comparable to state-of-the-art specialist LLMs. Moreover, Mol-LLM also shows superior generalization performances in reaction prediction tasks, demonstrating the effect of the molecular structure understanding for generalization perspective.
A Deep Reinforcement Learning Approach for Solving the Traveling Salesman Problem with Drone
Dec 31, 2021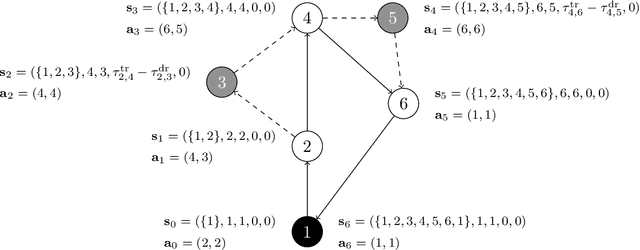
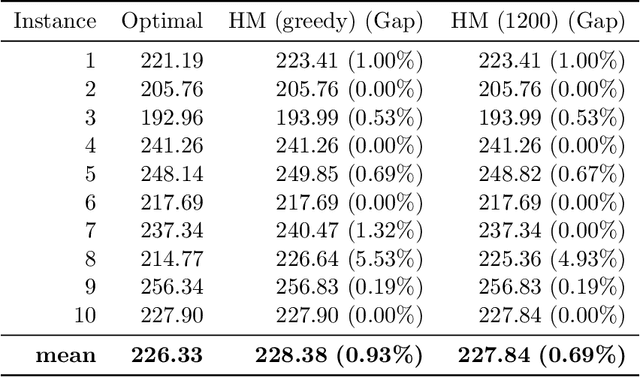
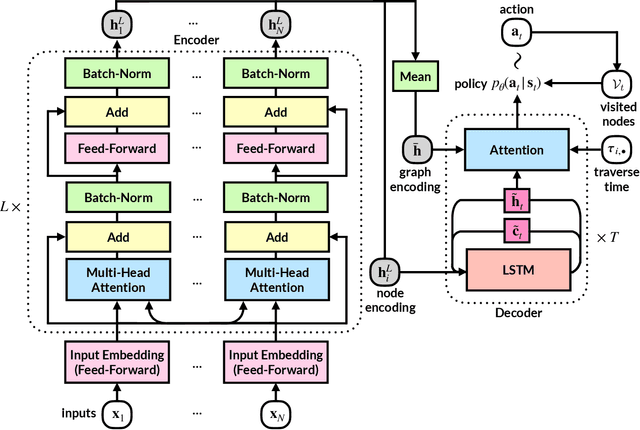
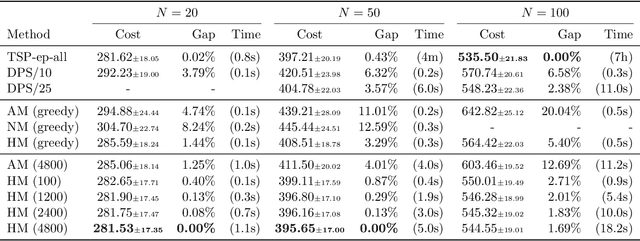
Reinforcement learning has recently shown promise in learning quality solutions in many combinatorial optimization problems. In particular, the attention-based encoder-decoder models show high effectiveness on various routing problems, including the Traveling Salesman Problem (TSP). Unfortunately, they perform poorly for the TSP with Drone (TSP-D), requiring routing a heterogeneous fleet of vehicles in coordination -- a truck and a drone. In TSP-D, the two vehicles are moving in tandem and may need to wait at a node for the other vehicle to join. State-less attention-based decoder fails to make such coordination between vehicles. We propose an attention encoder-LSTM decoder hybrid model, in which the decoder's hidden state can represent the sequence of actions made. We empirically demonstrate that such a hybrid model improves upon a purely attention-based model for both solution quality and computational efficiency. Our experiments on the min-max Capacitated Vehicle Routing Problem (mmCVRP) also confirm that the hybrid model is more suitable for coordinated routing of multiple vehicles than the attention-based model.