 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThreshold-aware Learning to Generate Feasible Solutions for Mixed Integer Programs
Aug 01, 2023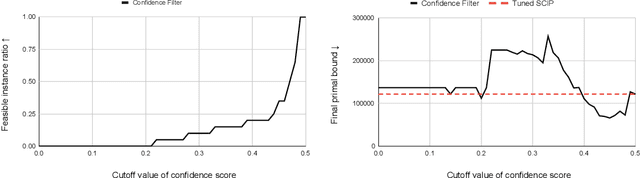

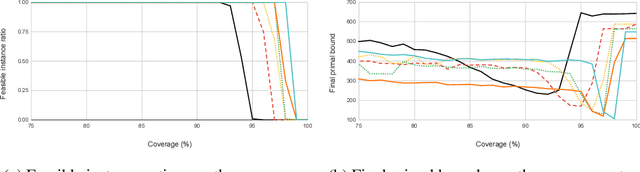
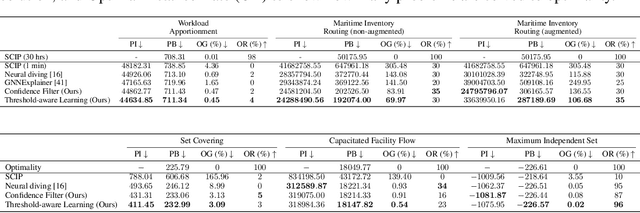
Finding a high-quality feasible solution to a combinatorial optimization (CO) problem in a limited time is challenging due to its discrete nature. Recently, there has been an increasing number of machine learning (ML) methods for addressing CO problems. Neural diving (ND) is one of the learning-based approaches to generating partial discrete variable assignments in Mixed Integer Programs (MIP), a framework for modeling CO problems. However, a major drawback of ND is a large discrepancy between the ML and MIP objectives, i.e., variable value classification accuracy over primal bound. Our study investigates that a specific range of variable assignment rates (coverage) yields high-quality feasible solutions, where we suggest optimizing the coverage bridges the gap between the learning and MIP objectives. Consequently, we introduce a post-hoc method and a learning-based approach for optimizing the coverage. A key idea of our approach is to jointly learn to restrict the coverage search space and to predict the coverage in the learned search space. Experimental results demonstrate that learning a deep neural network to estimate the coverage for finding high-quality feasible solutions achieves state-of-the-art performance in NeurIPS ML4CO datasets. In particular, our method shows outstanding performance in the workload apportionment dataset, achieving the optimality gap of 0.45%, a ten-fold improvement over SCIP within the one-minute time limit.
Confidence Threshold Neural Diving
Feb 15, 2022



Finding a better feasible solution in a shorter time is an integral part of solving Mixed Integer Programs. We present a post-hoc method based on Neural Diving to build heuristics more flexibly. We hypothesize that variables with higher confidence scores are more definite to be included in the optimal solution. For our hypothesis, we provide empirical evidence that confidence threshold technique produces partial solutions leading to final solutions with better primal objective values. Our method won 2nd place in the primal task on the NeurIPS 2021 ML4CO competition. Also, our method shows the best score among other learning-based methods in the competition.
A Deep Reinforcement Learning Approach for Solving the Traveling Salesman Problem with Drone
Dec 31, 2021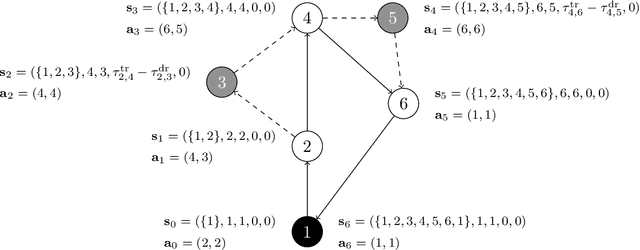
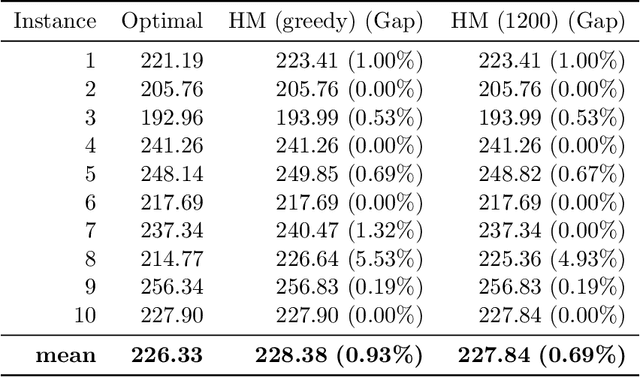
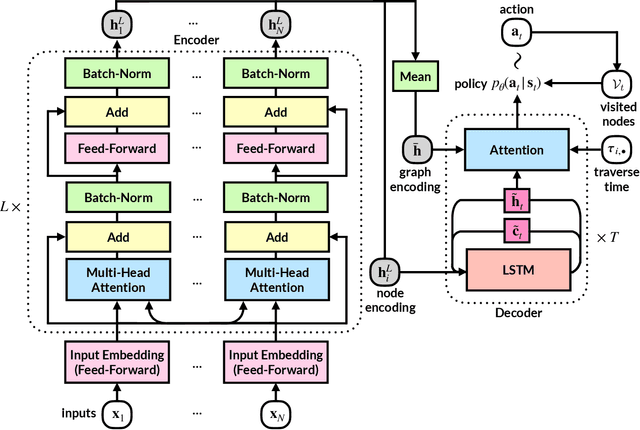
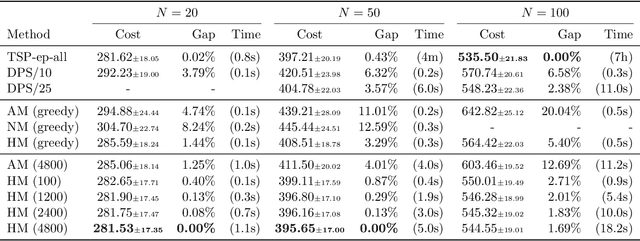
Reinforcement learning has recently shown promise in learning quality solutions in many combinatorial optimization problems. In particular, the attention-based encoder-decoder models show high effectiveness on various routing problems, including the Traveling Salesman Problem (TSP). Unfortunately, they perform poorly for the TSP with Drone (TSP-D), requiring routing a heterogeneous fleet of vehicles in coordination -- a truck and a drone. In TSP-D, the two vehicles are moving in tandem and may need to wait at a node for the other vehicle to join. State-less attention-based decoder fails to make such coordination between vehicles. We propose an attention encoder-LSTM decoder hybrid model, in which the decoder's hidden state can represent the sequence of actions made. We empirically demonstrate that such a hybrid model improves upon a purely attention-based model for both solution quality and computational efficiency. Our experiments on the min-max Capacitated Vehicle Routing Problem (mmCVRP) also confirm that the hybrid model is more suitable for coordinated routing of multiple vehicles than the attention-based model.