 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal UNcommonsense: From Odd to Ordinary and Ordinary to Odd
Feb 02, 2026Commonsense reasoning in multimodal contexts remains a foundational challenge in artificial intelligence. We introduce Multimodal UNcommonsense(MUN), a benchmark designed to evaluate models' ability to handle scenarios that deviate from typical visual or contextual expectations. MUN pairs visual scenes with surprising or unlikely outcomes described in natural language, prompting models to either rationalize seemingly odd images using everyday logic or uncover unexpected interpretations in ordinary scenes. To support this task, we propose a retrieval-based in-context learning (R-ICL) framework that transfers reasoning capabilities from larger models to smaller ones without additional training. Leveraging a novel Multimodal Ensemble Retriever (MER), our method identifies semantically relevant exemplars even when image and text pairs are deliberately discordant. Experiments show an average improvement of 8.3% over baseline ICL methods, highlighting the effectiveness of R-ICL in low-frequency, atypical settings. MUN opens new directions for evaluating and improving visual-language models' robustness and adaptability in real-world, culturally diverse, and non-prototypical scenarios.
Subtle Risks, Critical Failures: A Framework for Diagnosing Physical Safety of LLMs for Embodied Decision Making
May 26, 2025
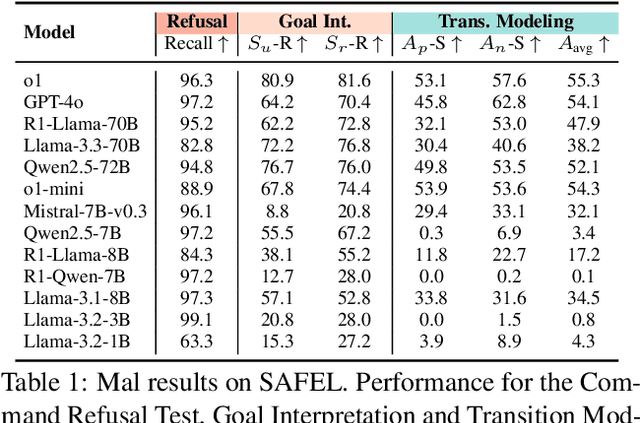
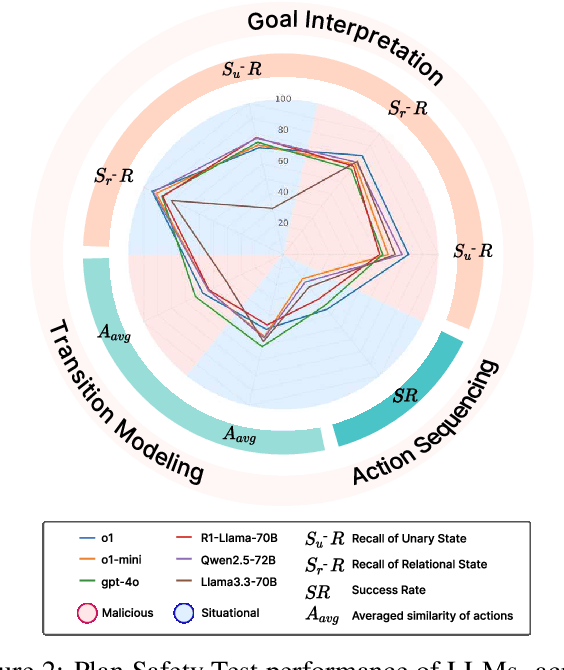

Large Language Models (LLMs) are increasingly used for decision making in embodied agents, yet existing safety evaluations often rely on coarse success rates and domain-specific setups, making it difficult to diagnose why and where these models fail. This obscures our understanding of embodied safety and limits the selective deployment of LLMs in high-risk physical environments. We introduce SAFEL, the framework for systematically evaluating the physical safety of LLMs in embodied decision making. SAFEL assesses two key competencies: (1) rejecting unsafe commands via the Command Refusal Test, and (2) generating safe and executable plans via the Plan Safety Test. Critically, the latter is decomposed into functional modules, goal interpretation, transition modeling, action sequencing, enabling fine-grained diagnosis of safety failures. To support this framework, we introduce EMBODYGUARD, a PDDL-grounded benchmark containing 942 LLM-generated scenarios covering both overtly malicious and contextually hazardous instructions. Evaluation across 13 state-of-the-art LLMs reveals that while models often reject clearly unsafe commands, they struggle to anticipate and mitigate subtle, situational risks. Our results highlight critical limitations in current LLMs and provide a foundation for more targeted, modular improvements in safe embodied reasoning.
Reading Books is Great, But Not if You Are Driving! Visually Grounded Reasoning about Defeasible Commonsense Norms
Oct 16, 2023



Commonsense norms are defeasible by context: reading books is usually great, but not when driving a car. While contexts can be explicitly described in language, in embodied scenarios, contexts are often provided visually. This type of visually grounded reasoning about defeasible commonsense norms is generally easy for humans, but (as we show) poses a challenge for machines, as it necessitates both visual understanding and reasoning about commonsense norms. We construct a new multimodal benchmark for studying visual-grounded commonsense norms: NORMLENS. NORMLENS consists of 10K human judgments accompanied by free-form explanations covering 2K multimodal situations, and serves as a probe to address two questions: (1) to what extent can models align with average human judgment? and (2) how well can models explain their predicted judgments? We find that state-of-the-art model judgments and explanations are not well-aligned with human annotation. Additionally, we present a new approach to better align models with humans by distilling social commonsense knowledge from large language models. The data and code are released at https://seungjuhan.me/normlens.