 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheX-GPT: Harnessing Large Language Models for Enhanced Chest X-ray Report Labeling
Jan 21, 2024



Free-text radiology reports present a rich data source for various medical tasks, but effectively labeling these texts remains challenging. Traditional rule-based labeling methods fall short of capturing the nuances of diverse free-text patterns. Moreover, models using expert-annotated data are limited by data scarcity and pre-defined classes, impacting their performance, flexibility and scalability. To address these issues, our study offers three main contributions: 1) We demonstrate the potential of GPT as an adept labeler using carefully designed prompts. 2) Utilizing only the data labeled by GPT, we trained a BERT-based labeler, CheX-GPT, which operates faster and more efficiently than its GPT counterpart. 3) To benchmark labeler performance, we introduced a publicly available expert-annotated test set, MIMIC-500, comprising 500 cases from the MIMIC validation set. Our findings demonstrate that CheX-GPT not only excels in labeling accuracy over existing models, but also showcases superior efficiency, flexibility, and scalability, supported by our introduction of the MIMIC-500 dataset for robust benchmarking. Code and models are available at https://github.com/kakaobrain/CheXGPT.
CXR-CLIP: Toward Large Scale Chest X-ray Language-Image Pre-training
Oct 20, 2023A large-scale image-text pair dataset has greatly contributed to the development of vision-language pre-training (VLP) models, which enable zero-shot or few-shot classification without costly annotation. However, in the medical domain, the scarcity of data remains a significant challenge for developing a powerful VLP model. In this paper, we tackle the lack of image-text data in chest X-ray by expanding image-label pair as image-text pair via general prompt and utilizing multiple images and multiple sections in a radiologic report. We also design two contrastive losses, named ICL and TCL, for learning study-level characteristics of medical images and reports, respectively. Our model outperforms the state-of-the-art models trained under the same conditions. Also, enlarged dataset improve the discriminative power of our pre-trained model for classification, while sacrificing marginal retrieval performance. Code is available at https://github.com/kakaobrain/cxr-clip.
AdaIN-Switchable CycleGAN for Efficient Unsupervised Low-Dose CT Denoising
Aug 13, 2020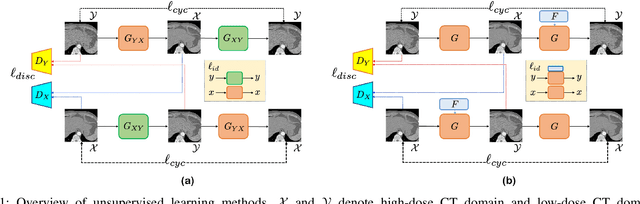
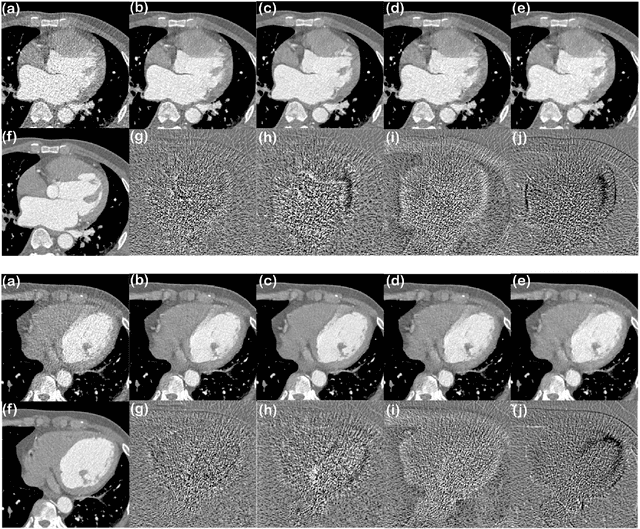
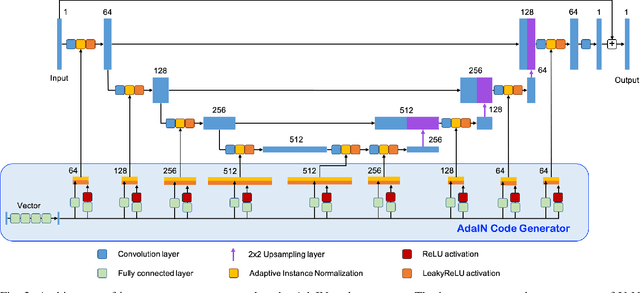
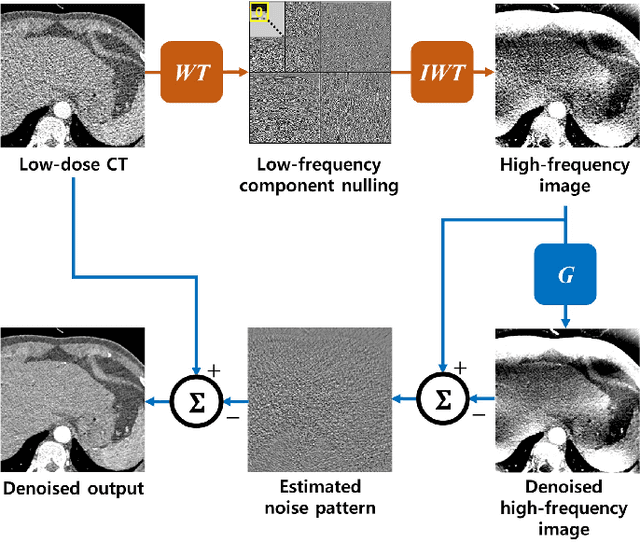
Recently, deep learning approaches have been extensively studied for low-dose CT denoising thanks to its superior performance despite the fast computational time. In particular, cycleGAN has been demonstrated as a powerful unsupervised learning scheme to improve the low-dose CT image quality without requiring matched high-dose reference data. Unfortunately, one of the main limitations of the cycleGAN approach is that it requires two deep neural network generators at the training phase, although only one of them is used at the inference phase. The secondary auxiliary generator is needed to enforce the cycle-consistency, but the additional memory requirement and increases of the learnable parameters are the main huddles for cycleGAN training. To address this issue, here we propose a novel cycleGAN architecture using a single switchable generator. In particular, a single generator is implemented using adaptive instance normalization (AdaIN) layers so that the baseline generator converting a low-dose CT image to a routine-dose CT image can be switched to a generator converting high-dose to low-dose by simply changing the AdaIN code. Thanks to the shared baseline network, the additional memory requirement and weight increases are minimized, and the training can be done more stably even with small training data. Experimental results show that the proposed method outperforms the previous cycleGAN approaches while using only about half the parameters.
Unsupervised CT Metal Artifact Learning using Attention-guided beta-CycleGAN
Jul 07, 2020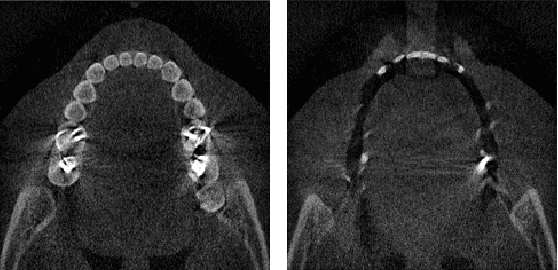

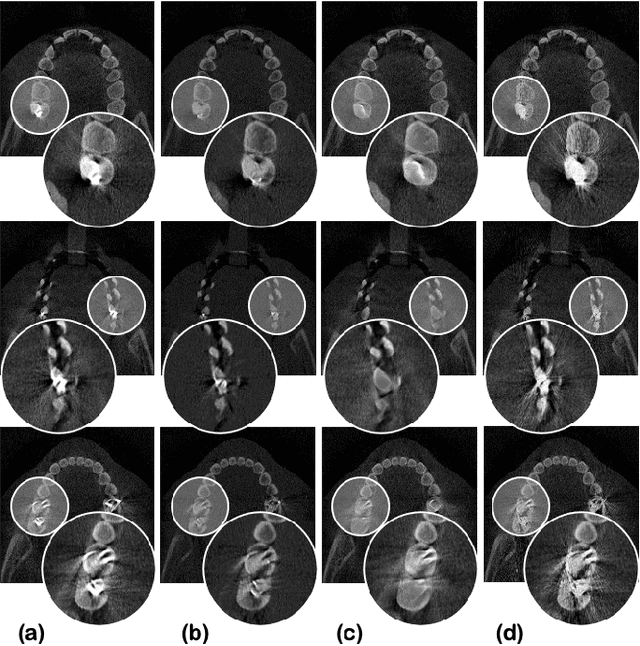
Metal artifact reduction (MAR) is one of the most important research topics in computed tomography (CT). With the advance of deep learning technology for image reconstruction,various deep learning methods have been also suggested for metal artifact removal, among which supervised learning methods are most popular. However, matched non-metal and metal image pairs are difficult to obtain in real CT acquisition. Recently, a promising unsupervised learning for MAR was proposed using feature disentanglement, but the resulting network architecture is complication and difficult to handle large size clinical images. To address this, here we propose a much simpler and much effective unsupervised MAR method for CT. The proposed method is based on a novel beta-cycleGAN architecture derived from the optimal transport theory for appropriate feature space disentanglement. Another important contribution is to show that attention mechanism is the key element to effectively remove the metal artifacts. Specifically, by adding the convolutional block attention module (CBAM) layers with a proper disentanglement parameter, experimental results confirm that we can get more improved MAR that preserves the detailed texture of the original image.
Deep Learning Interior Tomography for Region-of-Interest Reconstruction
Jan 03, 2018

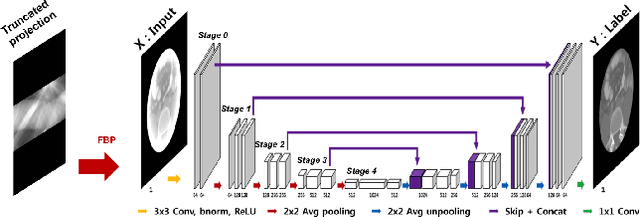

Interior tomography for the region-of-interest (ROI) imaging has advantages of using a small detector and reducing X-ray radiation dose. However, standard analytic reconstruction suffers from severe cupping artifacts due to existence of null space in the truncated Radon transform. Existing penalized reconstruction methods may address this problem but they require extensive computations due to the iterative reconstruction. Inspired by the recent deep learning approaches to low-dose and sparse view CT, here we propose a deep learning architecture that removes null space signals from the FBP reconstruction. Experimental results have shown that the proposed method provides near-perfect reconstruction with about 7-10 dB improvement in PSNR over existing methods in spite of significantly reduced run-time complexity.
Multi-Scale Wavelet Domain Residual Learning for Limited-Angle CT Reconstruction
Mar 04, 2017

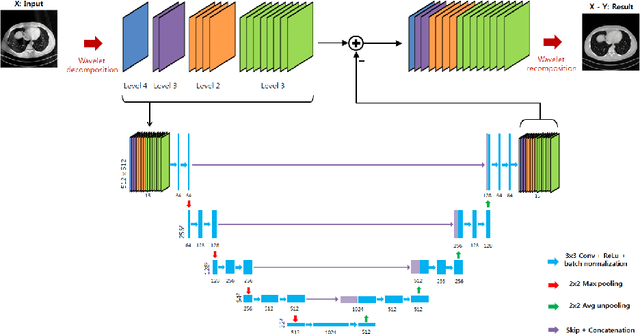
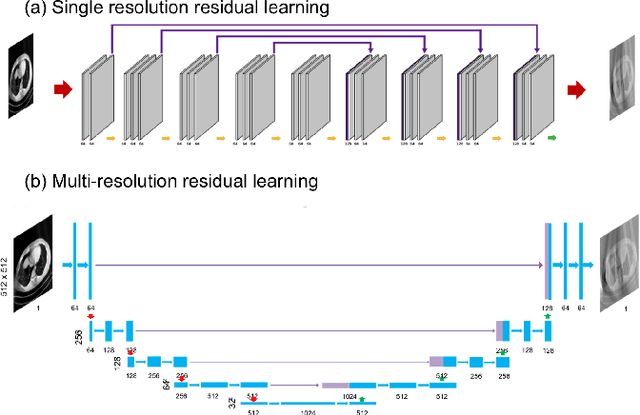
Limited-angle computed tomography (CT) is often used in clinical applications such as C-arm CT for interventional imaging. However, CT images from limited angles suffers from heavy artifacts due to incomplete projection data. Existing iterative methods require extensive calculations but can not deliver satisfactory results. Based on the observation that the artifacts from limited angles have some directional property and are globally distributed, we propose a novel multi-scale wavelet domain residual learning architecture, which compensates for the artifacts. Experiments have shown that the proposed method effectively eliminates artifacts, thereby preserving edge and global structures of the image.