 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Technical Report for Polyglot-Ko: Open-Source Large-Scale Korean Language Models
Jun 06, 2023Polyglot is a pioneering project aimed at enhancing the non-English language performance of multilingual language models. Despite the availability of various multilingual models such as mBERT (Devlin et al., 2019), XGLM (Lin et al., 2022), and BLOOM (Scao et al., 2022), researchers and developers often resort to building monolingual models in their respective languages due to the dissatisfaction with the current multilingual models non-English language capabilities. Addressing this gap, we seek to develop advanced multilingual language models that offer improved performance in non-English languages. In this paper, we introduce the Polyglot Korean models, which represent a specific focus rather than being multilingual in nature. In collaboration with TUNiB, our team collected 1.2TB of Korean data meticulously curated for our research journey. We made a deliberate decision to prioritize the development of Korean models before venturing into multilingual models. This choice was motivated by multiple factors: firstly, the Korean models facilitated performance comparisons with existing multilingual models; and finally, they catered to the specific needs of Korean companies and researchers. This paper presents our work in developing the Polyglot Korean models, which propose some steps towards addressing the non-English language performance gap in multilingual language models.
Fair Contrastive Learning for Facial Attribute Classification
Mar 30, 2022
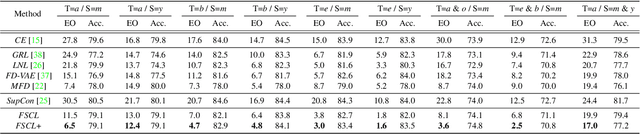
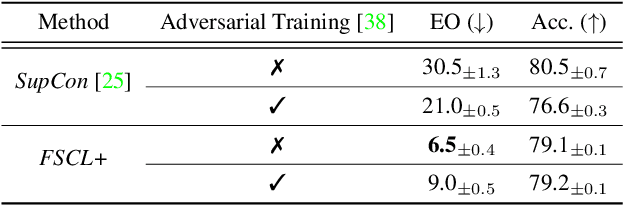
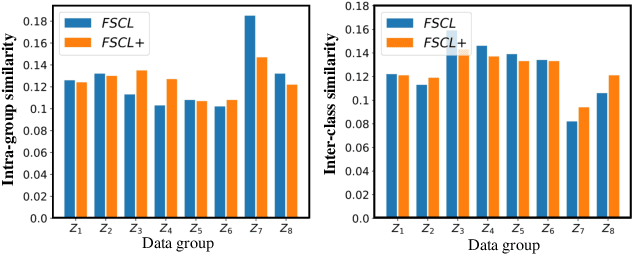
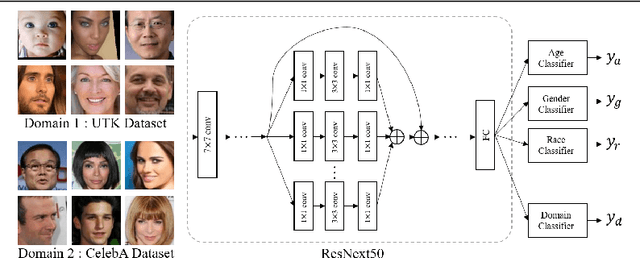
Learning visual representation of high quality is essential for image classification. Recently, a series of contrastive representation learning methods have achieved preeminent success. Particularly, SupCon outperformed the dominant methods based on cross-entropy loss in representation learning. However, we notice that there could be potential ethical risks in supervised contrastive learning. In this paper, we for the first time analyze unfairness caused by supervised contrastive learning and propose a new Fair Supervised Contrastive Loss (FSCL) for fair visual representation learning. Inheriting the philosophy of supervised contrastive learning, it encourages representation of the same class to be closer to each other than that of different classes, while ensuring fairness by penalizing the inclusion of sensitive attribute information in representation. In addition, we introduce a group-wise normalization to diminish the disparities of intra-group compactness and inter-class separability between demographic groups that arouse unfair classification. Through extensive experiments on CelebA and UTK Face, we validate that the proposed method significantly outperforms SupCon and existing state-of-the-art methods in terms of the trade-off between top-1 accuracy and fairness. Moreover, our method is robust to the intensity of data bias and effectively works in incomplete supervised settings. Our code is available at https://github.com/sungho-CoolG/FSCL.
FairFaceGAN: Fairness-aware Facial Image-to-Image Translation
Dec 02, 2020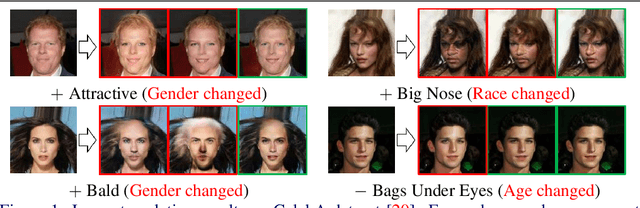

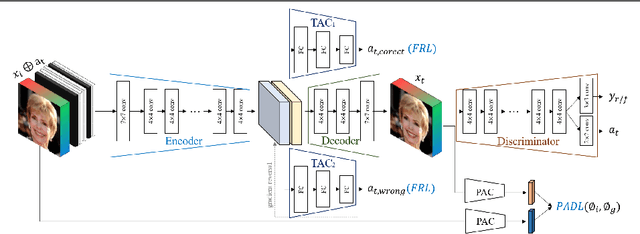
In this paper, we introduce FairFaceGAN, a fairness-aware facial Image-to-Image translation model, mitigating the problem of unwanted translation in protected attributes (e.g., gender, age, race) during facial attributes editing. Unlike existing models, FairFaceGAN learns fair representations with two separate latents - one related to the target attributes to translate, and the other unrelated to them. This strategy enables FairFaceGAN to separate the information about protected attributes and that of target attributes. It also prevents unwanted translation in protected attributes while target attributes editing. To evaluate the degree of fairness, we perform two types of experiments on CelebA dataset. First, we compare the fairness-aware classification performances when augmenting data by existing image translation methods and FairFaceGAN respectively. Moreover, we propose a new fairness metric, namely Frechet Protected Attribute Distance (FPAD), which measures how well protected attributes are preserved. Experimental results demonstrate that FairFaceGAN shows consistent improvements in terms of fairness over the existing image translation models. Further, we also evaluate image translation performances, where FairFaceGAN shows competitive results, compared to those of existing methods.
README: REpresentation learning by fairness-Aware Disentangling MEthod
Jul 07, 2020



Fair representation learning aims to encode invariant representation with respect to the protected attribute, such as gender or age. In this paper, we design Fairness-aware Disentangling Variational AutoEncoder (FD-VAE) for fair representation learning. This network disentangles latent space into three subspaces with a decorrelation loss that encourages each subspace to contain independent information: 1) target attribute information, 2) protected attribute information, 3) mutual attribute information. After the representation learning, this disentangled representation is leveraged for fairer downstream classification by excluding the subspace with the protected attribute information. We demonstrate the effectiveness of our model through extensive experiments on CelebA and UTK Face datasets. Our method outperforms the previous state-of-the-art method by large margins in terms of equal opportunity and equalized odds.