 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReTabAD: A Benchmark for Restoring Semantic Context in Tabular Anomaly Detection
Oct 02, 2025In tabular anomaly detection (AD), textual semantics often carry critical signals, as the definition of an anomaly is closely tied to domain-specific context. However, existing benchmarks provide only raw data points without semantic context, overlooking rich textual metadata such as feature descriptions and domain knowledge that experts rely on in practice. This limitation restricts research flexibility and prevents models from fully leveraging domain knowledge for detection. ReTabAD addresses this gap by restoring textual semantics to enable context-aware tabular AD research. We provide (1) 20 carefully curated tabular datasets enriched with structured textual metadata, together with implementations of state-of-the-art AD algorithms including classical, deep learning, and LLM-based approaches, and (2) a zero-shot LLM framework that leverages semantic context without task-specific training, establishing a strong baseline for future research. Furthermore, this work provides insights into the role and utility of textual metadata in AD through experiments and analysis. Results show that semantic context improves detection performance and enhances interpretability by supporting domain-aware reasoning. These findings establish ReTabAD as a benchmark for systematic exploration of context-aware AD.
Diffusion based Semantic Outlier Generation via Nuisance Awareness for Out-of-Distribution Detection
Aug 27, 2024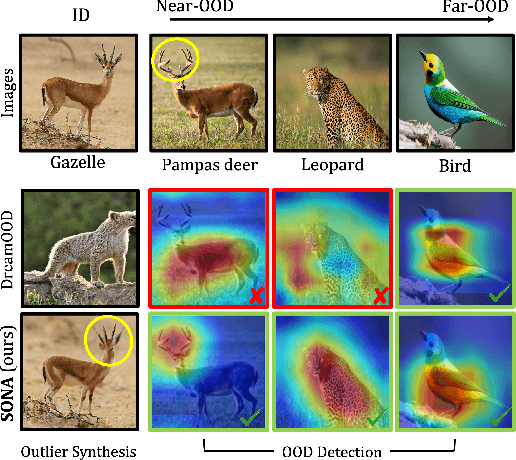
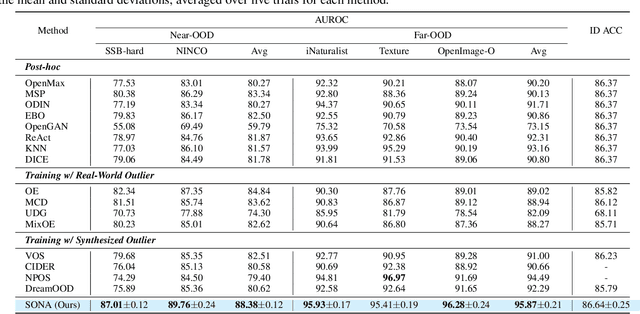
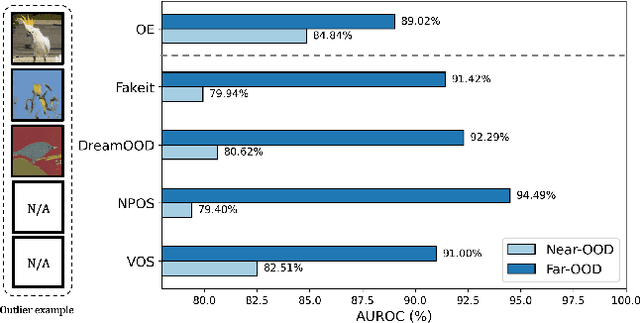
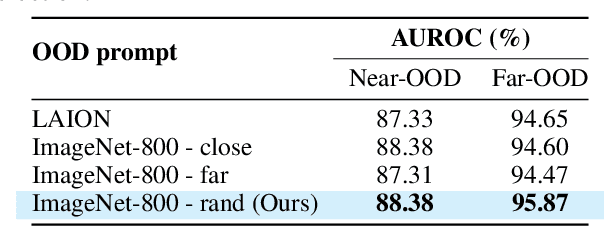
Out-of-distribution (OOD) detection, which determines whether a given sample is part of the in-distribution (ID), has recently shown promising results through training with synthetic OOD datasets. Nonetheless, existing methods often produce outliers that are considerably distant from the ID, showing limited efficacy for capturing subtle distinctions between ID and OOD. To address these issues, we propose a novel framework, Semantic Outlier generation via Nuisance Awareness (SONA), which notably produces challenging outliers by directly leveraging pixel-space ID samples through diffusion models. Our approach incorporates SONA guidance, providing separate control over semantic and nuisance regions of ID samples. Thereby, the generated outliers achieve two crucial properties: (i) they present explicit semantic-discrepant information, while (ii) maintaining various levels of nuisance resemblance with ID. Furthermore, the improved OOD detector training with SONA outliers facilitates learning with a focus on semantic distinctions. Extensive experiments demonstrate the effectiveness of our framework, achieving an impressive AUROC of 88% on near-OOD datasets, which surpasses the performance of baseline methods by a significant margin of approximately 6%.
Binning as a Pretext Task: Improving Self-Supervised Learning in Tabular Domains
May 14, 2024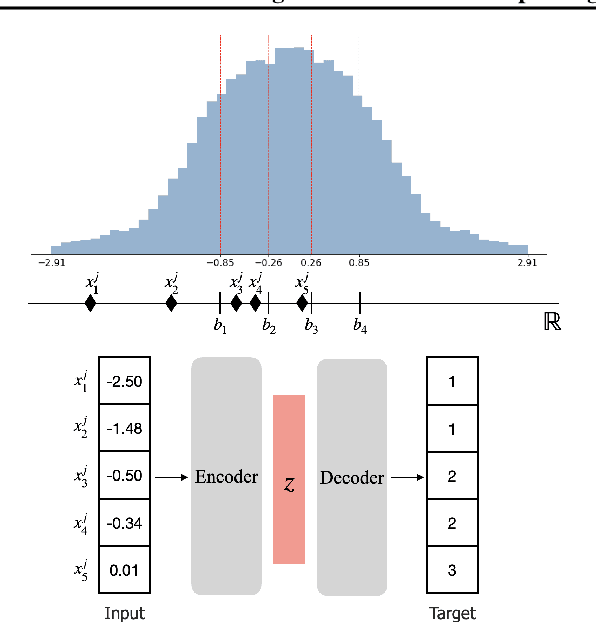
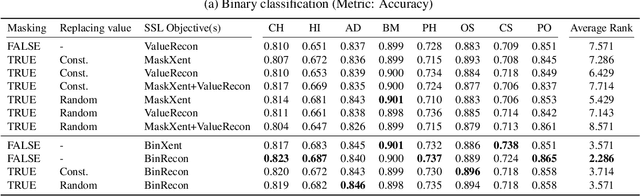
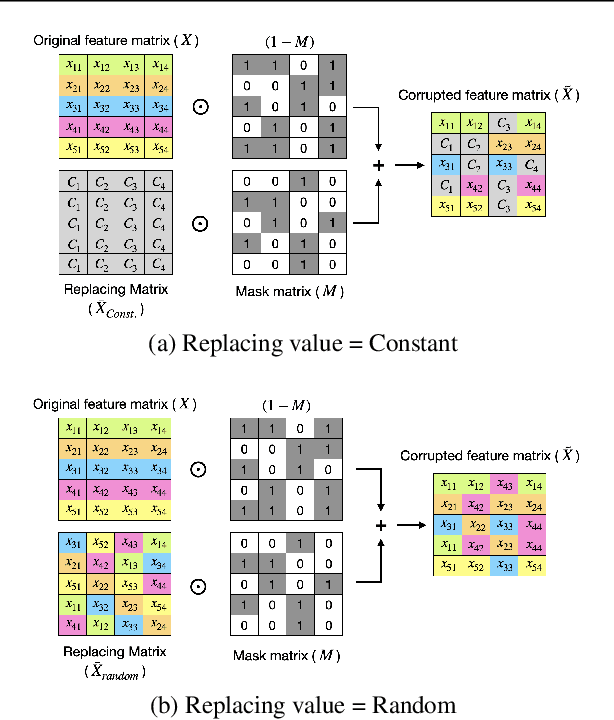
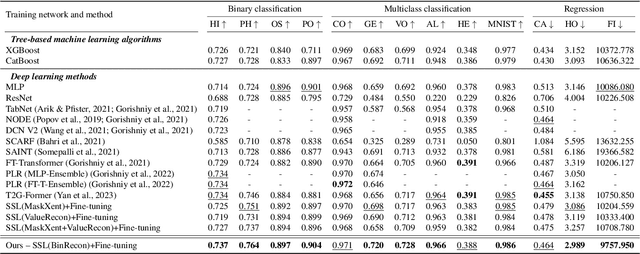
The ability of deep networks to learn superior representations hinges on leveraging the proper inductive biases, considering the inherent properties of datasets. In tabular domains, it is critical to effectively handle heterogeneous features (both categorical and numerical) in a unified manner and to grasp irregular functions like piecewise constant functions. To address the challenges in the self-supervised learning framework, we propose a novel pretext task based on the classical binning method. The idea is straightforward: reconstructing the bin indices (either orders or classes) rather than the original values. This pretext task provides the encoder with an inductive bias to capture the irregular dependencies, mapping from continuous inputs to discretized bins, and mitigates the feature heterogeneity by setting all features to have category-type targets. Our empirical investigations ascertain several advantages of binning: capturing the irregular function, compatibility with encoder architecture and additional modifications, standardizing all features into equal sets, grouping similar values within a feature, and providing ordering information. Comprehensive evaluations across diverse tabular datasets corroborate that our method consistently improves tabular representation learning performance for a wide range of downstream tasks. The codes are available in https://github.com/kyungeun-lee/tabularbinning.