 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Unsupervised Image-to-Image Translation
May 07, 2021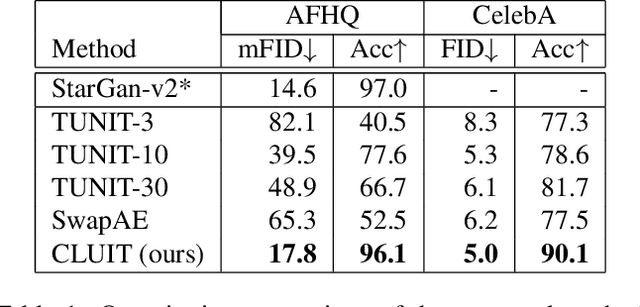

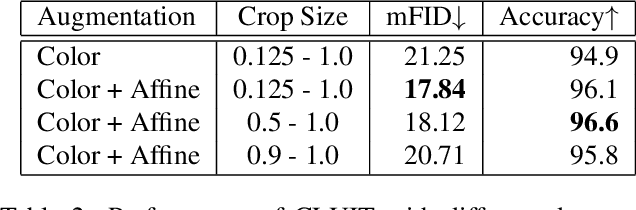

Image-to-image translation aims to learn a mapping between different groups of visually distinguishable images. While recent methods have shown impressive ability to change even intricate appearance of images, they still rely on domain labels in training a model to distinguish between distinct visual features. Such dependency on labels often significantly limits the scope of applications since consistent and high-quality labels are expensive. Instead, we wish to capture visual features from images themselves and apply them to enable realistic translation without human-generated labels. To this end, we propose an unsupervised image-to-image translation method based on contrastive learning. The key idea is to learn a discriminator that differentiates between distinctive styles and let the discriminator supervise a generator to transfer those styles across images. During training, we randomly sample a pair of images and train the generator to change the appearance of one towards another while keeping the original structure. Experimental results show that our method outperforms the leading unsupervised baselines in terms of visual quality and translation accuracy.
Semantics-Preserving Adversarial Training
Sep 23, 2020



Adversarial training is a defense technique that improves adversarial robustness of a deep neural network (DNN) by including adversarial examples in the training data. In this paper, we identify an overlooked problem of adversarial training in that these adversarial examples often have different semantics than the original data, introducing unintended biases into the model. We hypothesize that such non-semantics-preserving (and resultingly ambiguous) adversarial data harm the robustness of the target models. To mitigate such unintended semantic changes of adversarial examples, we propose semantics-preserving adversarial training (SPAT) which encourages perturbation on the pixels that are shared among all classes when generating adversarial examples in the training stage. Experiment results show that SPAT improves adversarial robustness and achieves state-of-the-art results in CIFAR-10 and CIFAR-100.
Variational Hierarchical Dialog Autoencoder for Dialog State Tracking Data Augmentation
Feb 07, 2020
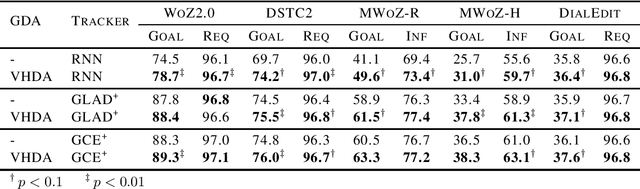
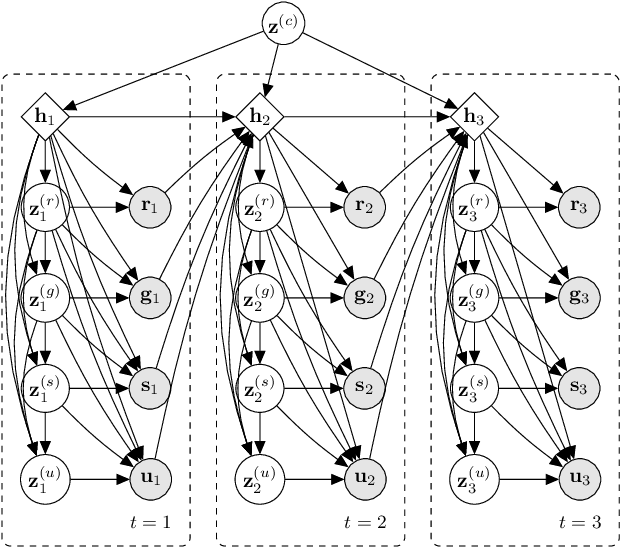

Recent works have shown that generative data augmentation, where synthetic samples generated from deep generative models are used to augment the training dataset, benefit certain NLP tasks. In this work, we extend this approach to the task of dialog state tracking for goal-oriented dialogs. Since, goal-oriented dialogs naturally exhibit a hierarchical structure over utterances and related annotations, deep generative data augmentation for the task requires the generative model to be aware of the hierarchical nature. We propose the Variational Hierarchical Dialog Autoencoder (VHDA) for modeling complete aspects of goal-oriented dialogs, including linguistic features and underlying structured annotations, namely dialog acts and goals. We also propose two training policies to mitigate issues that arise with training VAE-based models. Experiments show that our hierarchical model is able to generate realistic and novel samples that improve the robustness of state-of-the-art dialog state trackers, ultimately improving the dialog state tracking performances on various dialog domains. Surprisingly, the ability to jointly generate dialog features enables our model to outperform previous state-of-the-arts in related subtasks, such as language generation and user simulation.
Style2Vec: Representation Learning for Fashion Items from Style Sets
Aug 14, 2017



With the rapid growth of online fashion market, demand for effective fashion recommendation systems has never been greater. In fashion recommendation, the ability to find items that goes well with a few other items based on style is more important than picking a single item based on the user's entire purchase history. Since the same user may have purchased dress suits in one month and casual denims in another, it is impossible to learn the latent style features of those items using only the user ratings. If we were able to represent the style features of fashion items in a reasonable way, we will be able to recommend new items that conform to some small subset of pre-purchased items that make up a coherent style set. We propose Style2Vec, a vector representation model for fashion items. Based on the intuition of distributional semantics used in word embeddings, Style2Vec learns the representation of a fashion item using other items in matching outfits as context. Two different convolutional neural networks are trained to maximize the probability of item co-occurrences. For evaluation, a fashion analogy test is conducted to show that the resulting representation connotes diverse fashion related semantics like shapes, colors, patterns and even latent styles. We also perform style classification using Style2Vec features and show that our method outperforms other baselines.