 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxy-based Item Representation for Attribute and Context-aware Recommendation
Dec 11, 2023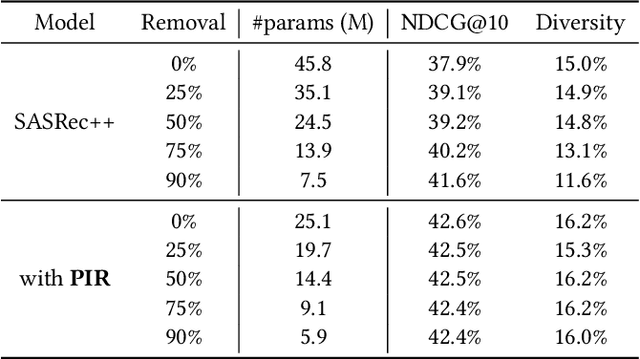
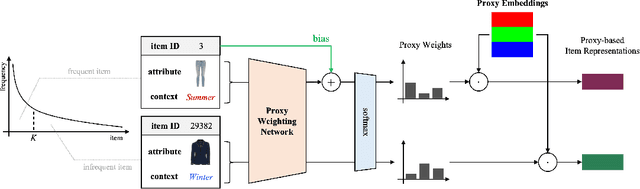
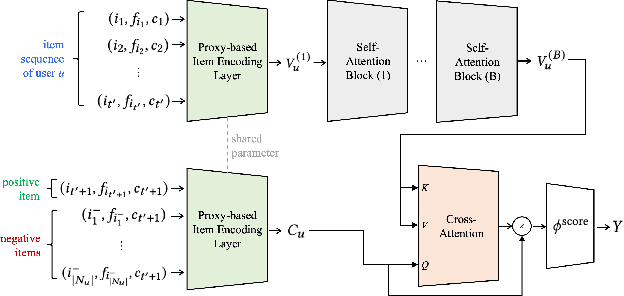

Neural network approaches in recommender systems have shown remarkable success by representing a large set of items as a learnable vector embedding table. However, infrequent items may suffer from inadequate training opportunities, making it difficult to learn meaningful representations. We examine that in attribute and context-aware settings, the poorly learned embeddings of infrequent items impair the recommendation accuracy. To address such an issue, we propose a proxy-based item representation that allows each item to be expressed as a weighted sum of learnable proxy embeddings. Here, the proxy weight is determined by the attributes and context of each item and may incorporate bias terms in case of frequent items to further reflect collaborative signals. The proxy-based method calculates the item representations compositionally, ensuring each representation resides inside a well-trained simplex and, thus, acquires guaranteed quality. Additionally, that the proxy embeddings are shared across all items allows the infrequent items to borrow training signals of frequent items in a unified model structure and end-to-end manner. Our proposed method is a plug-and-play model that can replace the item encoding layer of any neural network-based recommendation model, while consistently improving the recommendation performance with much smaller parameter usage. Experiments conducted on real-world recommendation benchmark datasets demonstrate that our proposed model outperforms state-of-the-art models in terms of recommendation accuracy by up to 17% while using only 10% of the parameters.
Exploiting Session Information in BERT-based Session-aware Sequential Recommendation
May 04, 2022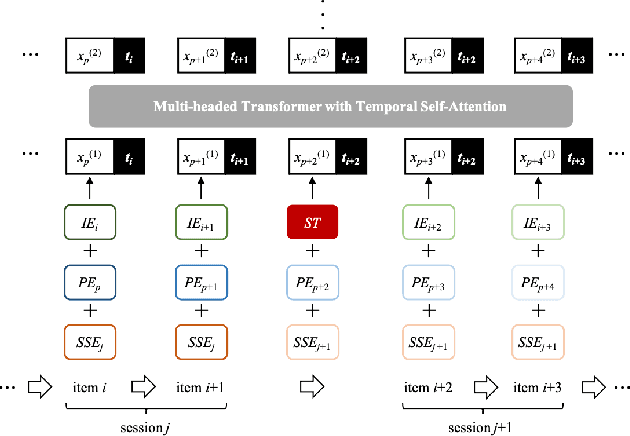
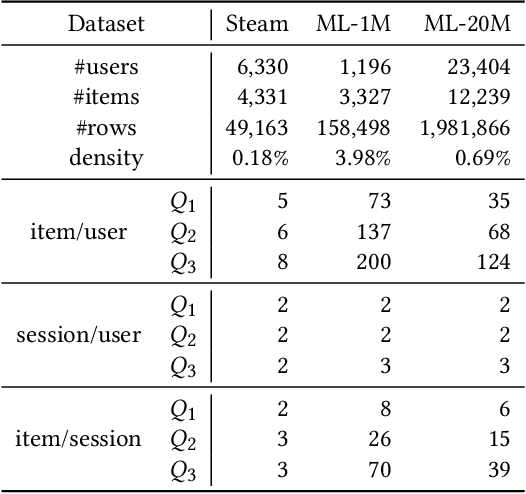

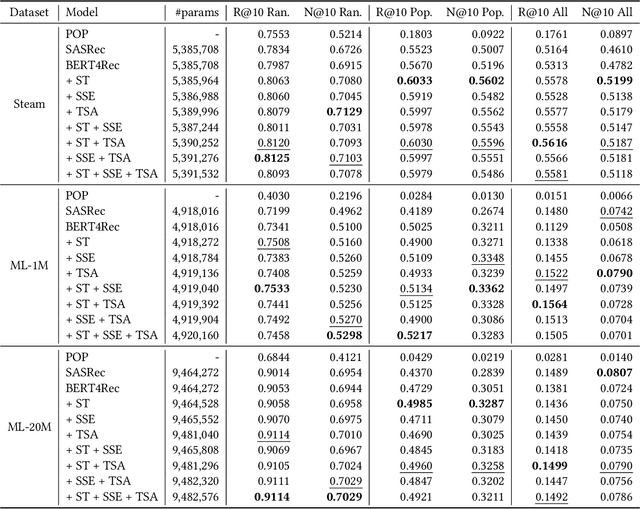
In recommendation systems, utilizing the user interaction history as sequential information has resulted in great performance improvement. However, in many online services, user interactions are commonly grouped by sessions that presumably share preferences, which requires a different approach from ordinary sequence representation techniques. To this end, sequence representation models with a hierarchical structure or various viewpoints have been developed but with a rather complex network structure. In this paper, we propose three methods to improve recommendation performance by exploiting session information while minimizing additional parameters in a BERT-based sequential recommendation model: using session tokens, adding session segment embeddings, and a time-aware self-attention. We demonstrate the feasibility of the proposed methods through experiments on widely used recommendation datasets.
Technologies for AI-Driven Fashion Social Networking Service with E-Commerce
Mar 11, 2022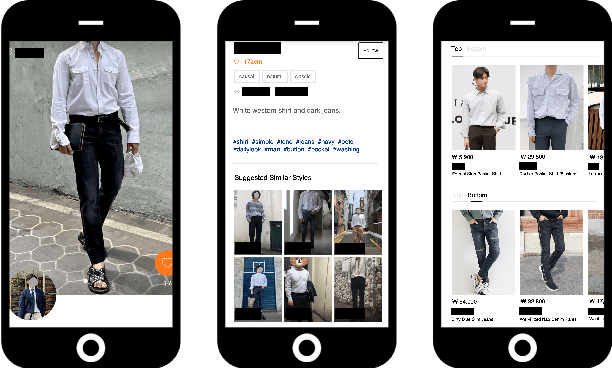
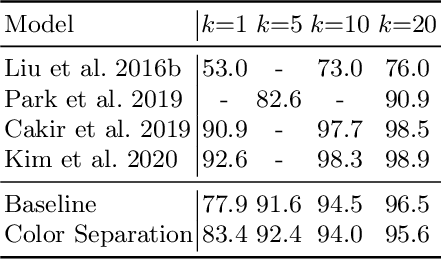
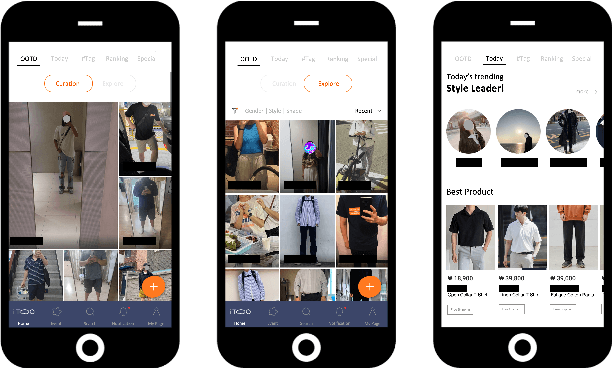

The rapid growth of the online fashion market brought demands for innovative fashion services and commerce platforms. With the recent success of deep learning, many applications employ AI technologies such as visual search and recommender systems to provide novel and beneficial services. In this paper, we describe applied technologies for AI-driven fashion social networking service that incorporate fashion e-commerce. In the application, people can share and browse their outfit-of-the-day (OOTD) photos, while AI analyzes them and suggests similar style OOTDs and related products. To this end, we trained deep learning based AI models for fashion and integrated them to build a fashion visual search system and a recommender system for OOTD. With aforementioned technologies, the AI-driven fashion SNS platform, iTOO, has been successfully launched.
False Negative Distillation and Contrastive Learning for Personalized Outfit Recommendation
Oct 13, 2021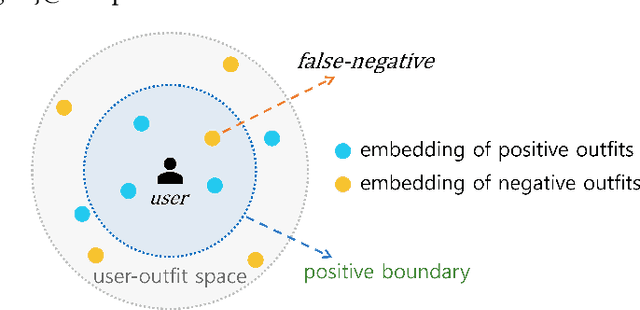
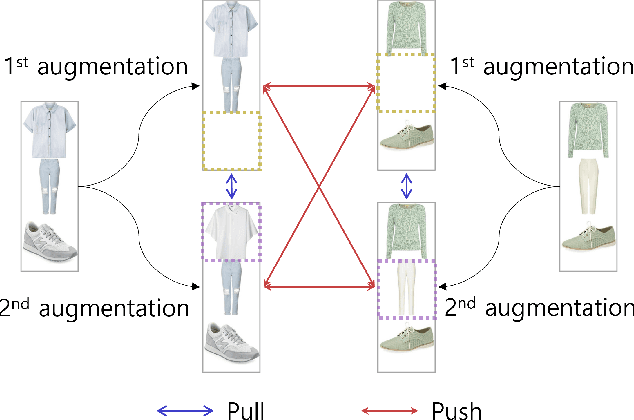
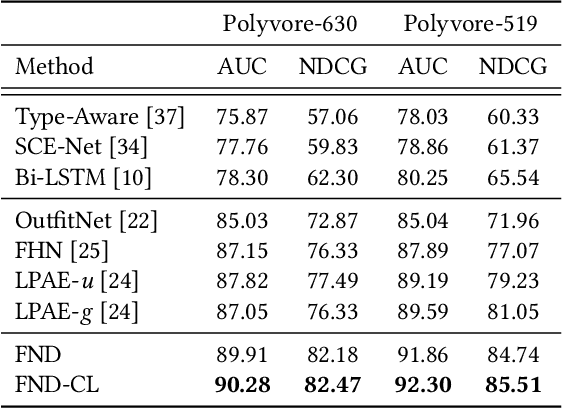
Personalized outfit recommendation has recently been in the spotlight with the rapid growth of the online fashion industry. However, recommending outfits has two significant challenges that should be addressed. The first challenge is that outfit recommendation often requires a complex and large model that utilizes visual information, incurring huge memory and time costs. One natural way to mitigate this problem is to compress such a cumbersome model with knowledge distillation (KD) techniques that leverage knowledge from a pretrained teacher model. However, it is hard to apply existing KD approaches in recommender systems (RS) to the outfit recommendation because they require the ranking of all possible outfits while the number of outfits grows exponentially to the number of consisting clothing items. Therefore, we propose a new KD framework for outfit recommendation, called False Negative Distillation (FND), which exploits false-negative information from the teacher model while not requiring the ranking of all candidates. The second challenge is that the explosive number of outfit candidates amplifying the data sparsity problem, often leading to poor outfit representation. To tackle this issue, inspired by the recent success of contrastive learning (CL), we introduce a CL framework for outfit representation learning with two proposed data augmentation methods. Quantitative and qualitative experiments on outfit recommendation datasets demonstrate the effectiveness and soundness of our proposed methods.
Masked Contrastive Learning for Anomaly Detection
May 18, 2021
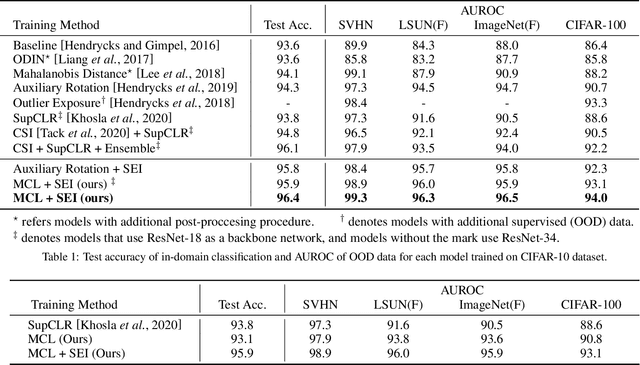


Detecting anomalies is one fundamental aspect of a safety-critical software system, however, it remains a long-standing problem. Numerous branches of works have been proposed to alleviate the complication and have demonstrated their efficiencies. In particular, self-supervised learning based methods are spurring interest due to their capability of learning diverse representations without additional labels. Among self-supervised learning tactics, contrastive learning is one specific framework validating their superiority in various fields, including anomaly detection. However, the primary objective of contrastive learning is to learn task-agnostic features without any labels, which is not entirely suited to discern anomalies. In this paper, we propose a task-specific variant of contrastive learning named masked contrastive learning, which is more befitted for anomaly detection. Moreover, we propose a new inference method dubbed self-ensemble inference that further boosts performance by leveraging the ability learned through auxiliary self-supervision tasks. By combining our models, we can outperform previous state-of-the-art methods by a significant margin on various benchmark datasets.
Contrastive Learning for Unsupervised Image-to-Image Translation
May 07, 2021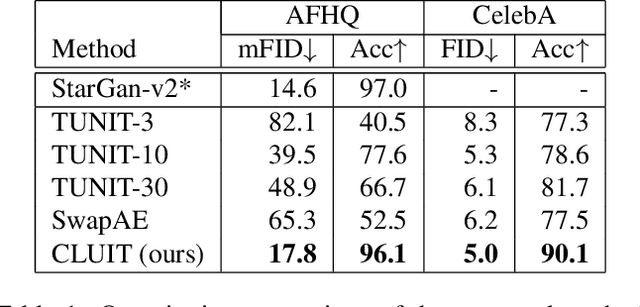

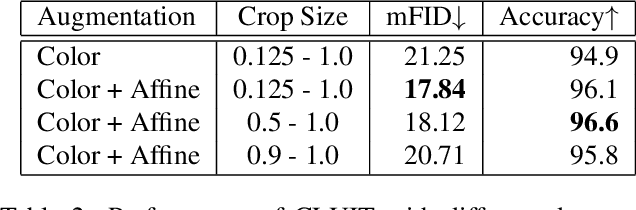

Image-to-image translation aims to learn a mapping between different groups of visually distinguishable images. While recent methods have shown impressive ability to change even intricate appearance of images, they still rely on domain labels in training a model to distinguish between distinct visual features. Such dependency on labels often significantly limits the scope of applications since consistent and high-quality labels are expensive. Instead, we wish to capture visual features from images themselves and apply them to enable realistic translation without human-generated labels. To this end, we propose an unsupervised image-to-image translation method based on contrastive learning. The key idea is to learn a discriminator that differentiates between distinctive styles and let the discriminator supervise a generator to transfer those styles across images. During training, we randomly sample a pair of images and train the generator to change the appearance of one towards another while keeping the original structure. Experimental results show that our method outperforms the leading unsupervised baselines in terms of visual quality and translation accuracy.
Style2Vec: Representation Learning for Fashion Items from Style Sets
Aug 14, 2017



With the rapid growth of online fashion market, demand for effective fashion recommendation systems has never been greater. In fashion recommendation, the ability to find items that goes well with a few other items based on style is more important than picking a single item based on the user's entire purchase history. Since the same user may have purchased dress suits in one month and casual denims in another, it is impossible to learn the latent style features of those items using only the user ratings. If we were able to represent the style features of fashion items in a reasonable way, we will be able to recommend new items that conform to some small subset of pre-purchased items that make up a coherent style set. We propose Style2Vec, a vector representation model for fashion items. Based on the intuition of distributional semantics used in word embeddings, Style2Vec learns the representation of a fashion item using other items in matching outfits as context. Two different convolutional neural networks are trained to maximize the probability of item co-occurrences. For evaluation, a fashion analogy test is conducted to show that the resulting representation connotes diverse fashion related semantics like shapes, colors, patterns and even latent styles. We also perform style classification using Style2Vec features and show that our method outperforms other baselines.
A Syllable-based Technique for Word Embeddings of Korean Words
Aug 05, 2017

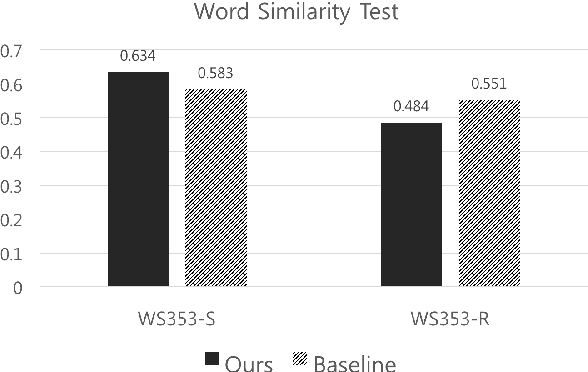

Word embedding has become a fundamental component to many NLP tasks such as named entity recognition and machine translation. However, popular models that learn such embeddings are unaware of the morphology of words, so it is not directly applicable to highly agglutinative languages such as Korean. We propose a syllable-based learning model for Korean using a convolutional neural network, in which word representation is composed of trained syllable vectors. Our model successfully produces morphologically meaningful representation of Korean words compared to the original Skip-gram embeddings. The results also show that it is quite robust to the Out-of-Vocabulary problem.